
はじめに
その週darkkは、橋の状態(混合/離婚)を認識する問題への彼のアプローチを説明しました。
この記事で説明されているアルゴリズムは、コンピュータービジョン手法を使用して写真から特徴を抽出し、ロジスティック回帰を与えて、ブリッジが減少した可能性の推定値を取得しました。
コメントでは、自分でプレイできるように写真を投稿するように依頼しました。 darkkはリクエストに応えました。
過去数年間で、ニューラルネットワークはデータから特徴を自動的に抽出して処理するアルゴリズムとして非常に人気があり、これはコードを書く人の観点から簡単に行われ、非常に高い精度が多くのタスクで達成されています( 〜機械学習のすべてのタスクの5%)彼らは、他のアルゴリズムが考慮されないほどのマージンで、英国の旗に対する競合他社を引き裂きます。 ニューラルネットワークのこれらの成功した方向性の1つは、画像の操作です。 2012年のImageNetコンテストでのたたみ込みニューラルネットワークの説得力のある勝利の後、学界やそうでないサークルの大衆は非常に興奮し、この方向のソフトウェア製品と同様に科学的結果がほぼ毎日現れました。 その結果、多くの場合、ニューラルネットワークの使用が非常に簡単になり、「ファッショナブルで若々しい」ものから、機械学習の専門家、そして実際にはすべての人が使用する通常のツールに変わりました。
問題の声明。
darkkは、サンクトペテルブルクのAlexander Nevsky Bridgeの画像を投稿しました。 上昇位置で30k +、下降位置で30k +、中間位置で9k +。
私たちが解決しようとしている問題は、日中、夜中、および年中の異なる時間にアレクサンドル・ネフスキー橋に向けられた静的カメラからの画像を使用して、橋がクラスに属する確率を決定することです(上昇/下降/プロセス)。 私は、これが実際的な観点から重要であるという理由で、発生/除外されたクラスで作業します。
ニューラルネットワークは、トレーニングやその他のエキゾチックなデータが非常に少ない状況で、画像、ノイズの多いデータなどの非常に複雑な問題を解決できます(たとえば、 この問題はドライバーの注意散漫 に関するものであるか、これは神経のセグメンテーションに関するものです 。しかし!十分なデータがあり、分類オブジェクトは実質的に変更されないままです-ニューラルネットワーク、そして実際に機械学習タスクのために-それはシンプルと非常にシンプルの間のどこかにあります。 コンピュータビジョンと機械学習の許容される組み合わせ。
私が解決しようとするタスクは、この問題に関してニューラルネットワークが提供できるものを評価することです。
データ準備。
ニューラルネットワークはノイズに対して非常に堅牢であるという事実にもかかわらず、データのクリーニングはわずかに害を及ぼしません。 この場合、ブリッジの最大値と他のすべての最小値が含まれるように画像をトリミングします。
次のようなものでした。

そして、それはこのようになりました:

データを3つの部分に分割する必要もあります。
- 電車
- 検証
- テストする
電車-5月19日-7月17日
検証-7月18、19、20
テスト-7月21、22、23
実際、これで画像の準備は終わりです。 線、角度、その他の記号を分離しようとする必要はありません。
トレーニングモデル。
畳み込み層が特徴を抽出する単純な畳み込みネットワークを定義し、最後の層が質問に答えようとします。
( Theanoをバックエンドとして使用してKerasパッケージを使用しますが、それは単に安価で陽気だからです。)
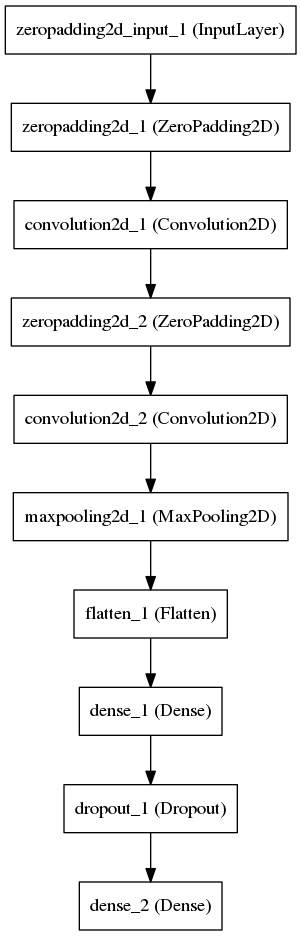
かなり単純なタスク、少数の空きパラメーターを持つ単純なネットワーク構造があるため、ネットワークは著しく収束します。 すべての写真をメモリに入れることができますが、私たちはそのようには感じないので、ディスクから写真を少しずつ読んで訓練します。
トレーニングプロセスは次のようになります。
Using Theano backend. Using gpu device 0: GeForce GTX 980 Ti (CNMeM is disabled, cuDNN 5103) Found 59834 images belonging to 2 classes. Found 6339 images belonging to 2 classes. [2016-08-06 14:26:48.878313] Creating model Epoch 1/10 59834/59834 [==============================] - 54s - loss: 0.1785 - acc: 0.9528 - val_loss: 0.0623 - val_acc: 0.9882 Epoch 2/10 59834/59834 [==============================] - 53s - loss: 0.0400 - acc: 0.9869 - val_loss: 0.0375 - val_acc: 0.9880 Epoch 3/10 59834/59834 [==============================] - 53s - loss: 0.0320 - acc: 0.9870 - val_loss: 0.0281 - val_acc: 0.9883 Epoch 4/10 59834/59834 [==============================] - 53s - loss: 0.0273 - acc: 0.9875 - val_loss: 0.0225 - val_acc: 0.9886 Epoch 5/10 59834/59834 [==============================] - 53s - loss: 0.0228 - acc: 0.9896 - val_loss: 0.0182 - val_acc: 0.9915 Epoch 6/10 59834/59834 [==============================] - 53s - loss: 0.0189 - acc: 0.9921 - val_loss: 0.0142 - val_acc: 0.9961 Epoch 7/10 59834/59834 [==============================] - 53s - loss: 0.0158 - acc: 0.9941 - val_loss: 0.0129 - val_acc: 0.9940 Epoch 8/10 59834/59834 [==============================] - 53s - loss: 0.0137 - acc: 0.9953 - val_loss: 0.0108 - val_acc: 0.9964 Epoch 9/10 59834/59834 [==============================] - 53s - loss: 0.0118 - acc: 0.9963 - val_loss: 0.0094 - val_acc: 0.9979 Epoch 10/10 59834/59834 [==============================] - 53s - loss: 0.0111 - acc: 0.9964 - val_loss: 0.0083 - val_acc: 0.9975 [2016-08-06 14:35:46.666799] Saving model [2016-08-06 14:35:46.809798] Saving history [2016-08-06 14:35:46.810558] Evaluating on test set Found 6393 images belonging to 2 classes. [0.014433901176242065, 0.99405599874863126] ...
または写真で:

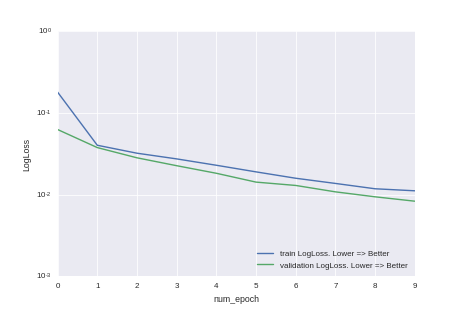
トレーニングを行わなかったことがわかります。モデルの精度は、トレーニング時間を増やすだけで改善できます。 しかし、不注意な教師は大学で言いたいので、これは希望する人のための宿題です。
予測精度評価
数値
精度評価は、7月21〜23日のデータに対して行われます。
precision_score = 0.994
roc_auc_score = 0.985
log_loss_score = 0.014
ビジュアル

緑色の線は、写真でマークされているものです。
青い線は、過去20回の予測の移動平均です。
背後に残っているもの。
モデルをトレーニングするとき、valの精度が電車の精度よりも優れている理由。 回答:=>列車では-この精度はドロップアウトであるが、valでは-ではないため
このモデルアーキテクチャが選択される理由 回答=>「しかし、それは明らかです!」と言いたいのですが、正しい答えは、おそらくまだ、 http://cs231n.github.io/の講義ノートを読むことです。https://www.youtubeで一連の講義を見る.com / watch?v = PlhFWT7vAEwそして、答えが「MNISTのような非常に類似したタスクで動作するため、このアーキテクチャが選択される」という形で洞察が得られるまでkaggle.comで競争を推進します
どの写真でモデルはエラーを出します。 回答:=>私は片目で見ました-これらは、カメラが機能しなかったために人を区別できない写真です。 モデルがエラーを与える適切な画像があるかもしれませんが、これにはもっと思慮深い分析が必要です。
上記のすべてのコードはどこで入手できますか? 回答=> https://github.com/ternaus/spb_bridges
モデルは他のブリッジで動作しますか? 回答=>可能ですが、知っている人は試してみる必要があります。
そして、タスクがこれだった場合:アレクサンドル・ネフスキー橋の画像を使用して、鋳造橋を予測するためのモデルを作成します、あなたは同じことをしますか? 回答=>いいえ。 彼らは異なるリフティングシステムを持っているので、そこでデータを見て、考えてみなければなりませんでした。 適切な相互検証の問題は非常に深刻です。 一般的に、これは興味深いタスクです。
また、ブリッジだけが残るように画像をトリミングしない場合、タスクははるかに困難になりますか? 回答=>できますが、それほど多くはありません。
しかし、2つのクラス(混合/離婚)に分類せず、3つ(混合/離婚/運動中)に分類するとどうなりますか? 回答=> 3つのクラスに分類すると、3つのクラスのいずれかに属しているかの評価が得られます。 ただし、ファイル内の複数の行を変更する必要があります。これにより、データが部分に分割され、1行がモデルの定義に含まれます。 =>愛好家のための宿題。
モデルをうまく機能させるために脳を壊す必要がある難しいタスクの例=>回答:今、テキストを完成させ、 githubをコードと組み合わせます。 画像の神経セグメンテーションについて考え始めます。
橋のある写真はどこで入手できますか? 回答:=>これは暗くすることです
- アレクサンドル・ネフスキーの橋が引かれているかどうかを知るために必要なニューロンの数は? 回答:=>そして、1つのニューロン、つまりロジスティック回帰は素晴らしい結果をもたらします。
あとがき。
これは、機械学習におけるこの分野の開発のこの段階でのニューラルネットワークにとって、本当に非常に簡単なタスクです。 さらに、ニューラルネットワークでさえありませんが、より単純なアルゴリズムがバタンと機能します。 ニューラルネットワークの利点は、ノイズが多い場合は自動特徴抽出モードで動作し、たとえば画像を操作する場合など、一部のタイプのデータでは最新のレベルの精度が得られることです。 そして、このテキストにコードを添付して、ニューラルネットワークでの作業は非常に難しいという意見を払拭しようとしました。 いいえ、そうではありません。 複雑なタスクで正確な精度を示すようにニューラルネットワークを操作することは困難ですが、非常に多くのタスクがこのカテゴリに属しておらず、この領域に入るためのしきい値は、人気のあるリソースに関するニュースを読んだ後に見えるほど高くはありません。