
Michael Trottの投稿の翻訳、「 Piのどこでも日付(e)!Piの桁の日付の出現に関する統計的および数学的考察 」
記事のコードはここからダウンロードできます 。
Kirill Guzenkoに感謝します。
内容
過去100年間のすべての日付を取得する
piのすべての日付を検索
すべての日付の統計
最初の日付
他の表現および他の定数の日付
最近の投稿(「 3/14/15 9:26:53世紀の「Piの日」のお祝いの翻訳、 およびHabréで非常に個人的なpiを取得する方法に関するストーリー 」を参照) piの世紀の日の一意の位置とpiの桁(以降は10進表記)で日付の内容の異なる例を示しました。 この投稿では、piの最初の1,000万桁における過去100年間のすべての可能な日付の分布の統計を調べます。 数字の99.998%が何らかの日付であり、piの最初の1,000万桁で数百万の日付が見つかることがわかります。
6桁以内で指定できる日付に焦点を当てます。 つまり、1915年3月15日から2015年3月14日までの36 525日の間隔で日付を一意に設定できます。
ムードを設定するためのテーマのグラフィカルな視覚化から始めましょう。

過去100年間のすべての日付を取得する
いつものように、今年のpiの日は3月14日でした。

20世紀の1世紀にわたる日から36 525日が経過しました。

問題の36,525の日付すべてのリストを作成します。
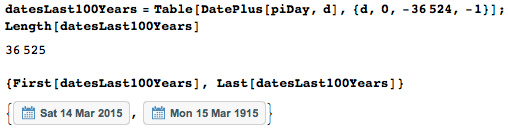
さらに作業を進めるために、関数dateNumberを定義します。この関数は、指定された日付に対して、最初から始まる日付のシリアル番号を返します(1915年3月15日の番号は1です)。
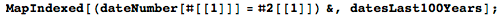
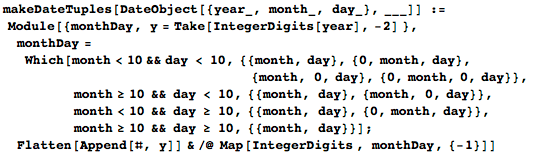
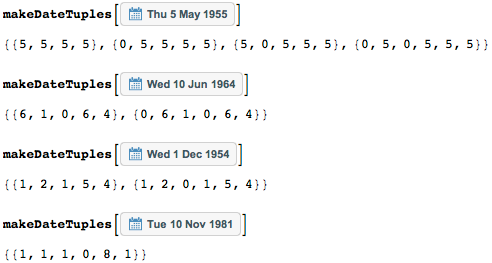
9月から1月までの月については、1つの番号のみを要求できます。つまり、9ではなく9の場合、9です。 数日も同様です。 つまり、いくつかの日付は、異なる一連の数字で設定できます。 makeDateTuples関数は、日付を表す整数のすべてのシーケンスを生成します。 複数の異なる日付表記を使用できます。常にゼロを使用するか、常に短い表記を使用します。 オプションで日と月のレコードにゼロを含めると、より多くの一致と結果が得られるため、今後それらを使用します。 (また、日-月-年の形式で日付を記録するための通常の形式を好む場合は、 makeDateTuples関数を変更するだけです。)
日付は、1つ、2つ、または4つの方法で表すことができます。
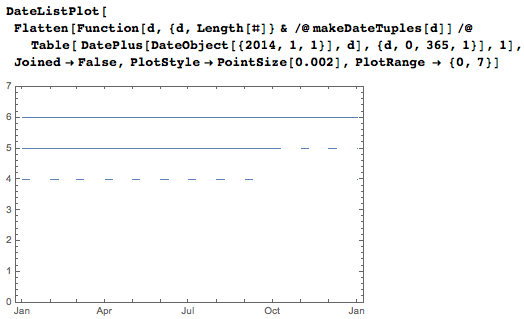
次のグラフは、昨年のどの日が4、5、および6桁で表されるかを示しています。 1月から9月までの最初の9日間は録音に4桁または5桁を必要とし、10月、11月、12月の最後の日は6桁を必要とします。
シーケンスを日付として高速に(一定時間内に)繰り返し認識するために、関数dateQおよびdatesOfを設定します。 datesOfは、一連の日付数字の正規化された形式を提供します。 シーケンスのペアを作成し、それらを日付として解釈することから始めます。

以下に例を示します。
ほとんどの(77,350)シーケンスは、日付として明確に解釈できます。 いくつか(2700)には2つの解釈があります。

以下は、2桁の数字のシーケンスです。

シーケンス{1,2,1,5,4}には、1954年1月21日時点または1954年12月1日時点の2つの解釈があり、 datesOf関数を使用して復元されています。

これは、日付の4桁、5桁、および6桁の表現の数です。

そして、これは、 datesOf関数に設定された各タイプの定義の数です。

piのすべての日付を検索
それ以降のすべての計算では、piの最初の1,000万桁を使用します(後で1000万桁で日付を見つけるのに十分であることが示されます)。 piは他の定数に簡単に置き換えることができます(コードは普遍的です)。
文字列として数字の完全なシーケンスを使用する代わりに、(重複する)シーケンスに分割された数字のシーケンスを使用します。 これで、各シーケンスをすばやく独立して操作できます。 そして、シーケンス番号でシーケンスにインデックスを付けました。 例:

上記で定義したdateQおよびdatesOf関数を使用すると、日付として解釈できるすべての数字列をすばやく見つけることができます。
見つかった日付の解釈を次に示します。 各サブリストの形式は次のとおりです。
{date、startingDigit、digitSequenceRepresentingTheDate}
(日付、開始桁、日付を表す一連の数字)。

4つの数字で表される約810万の日付が見つかりました。 約380万の日付-5 。 約365千の日付-6 、合計1,200万の日付 。

文字列処理関数(特にStringPosition )を使用して、日付シーケンスの位置を検索できることに注意してください。 そしてもちろん、同じ結果が得られます。

StringPositionを使用すると、単一の日付を検索するのに適していますが、35,000シーケンスすべてを処理するには、はるかに時間がかかります。

少し立ち止まって、見つかった4桁のシーケンスのカウンターを見てみましょう。 10,000の可能な4桁のシーケンスのうち、8,100が使用され、それぞれが平均(1/10)⁴*10⁷=10⁴回出現します。これはpiの数字の分布の「ランダム性」に由来します。 標準偏差は約1000 ^½≈31.6になるはずです。 小さな計算とグラフでこれらの数字を確認します。

4桁の異なる日付の数の分布曲線は、予想されるベルの形をしています。
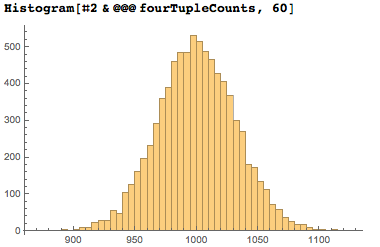
次のグラフは、日付を表す4桁の各シーケンスが、piの最初の1,000万桁の10進数で表示される頻度を示しています。 数字を数字に組み合わせて、4桁のシーケンスすべてに番号を付けました。 その結果、4桁のシーケンスが日付を表していない領域に空の垂直バーが表示される場合があります。
現在、見つかった日付位置の処理を続けています。 結果を同じ日付のリストにグループ化します。

実際、最初の1,000万桁ですべての日付が見つかりました。つまり、36,525の異なる日付が見つかったことがわかります(分析する桁数の選択が最適であったことが後でわかります)。

典型的なdateGroupsメンバーは次のようになります。
すべての日付の統計
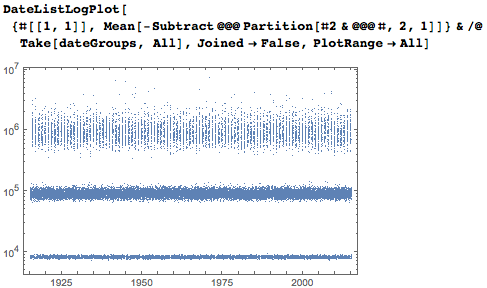
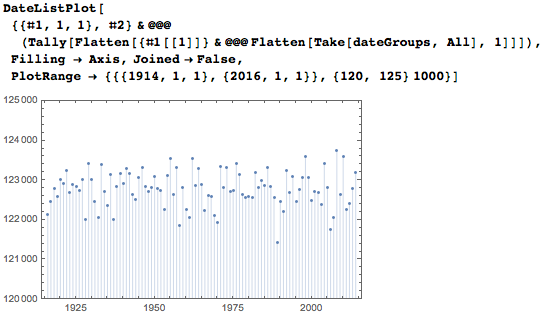
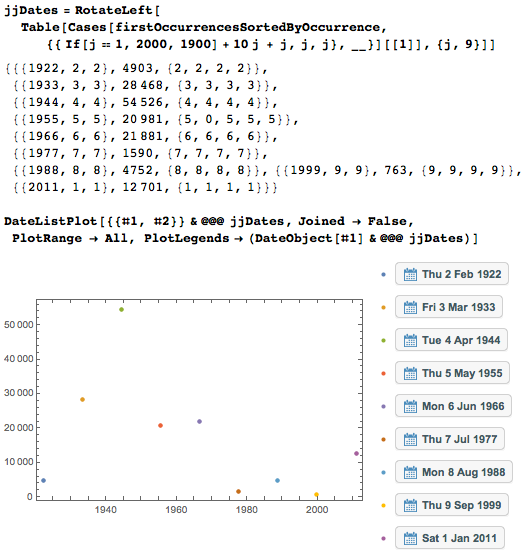
次に、統計の観点から見つかったデータを検討します。 piの最初の1,000万桁の各日付の出現回数は次のとおりです。 それはおもしろく、おそらく予想外のことでもありますが、多くの日付は何百回も発生します。 定期的に発生する縦縞は、10月から11月、12月の四半期に表示されます。

日付間の平均距離も、平均間隔が10,000未満の年の4桁の記録の初期の出現を明確に示し、5桁の間隔は約100,000に対応し、6桁の間隔は約1,000,000に対応します。
読みやすくするために、トリプル{date、StartingPosition、dateDigitSequence}を個別にフォーマットしました。
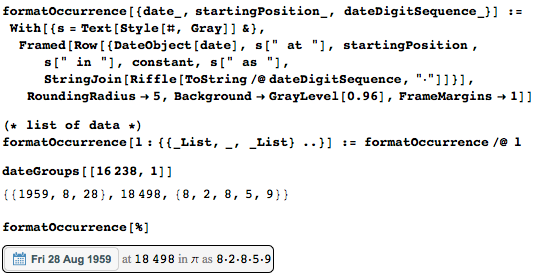
最初の1,000万桁の最も一般的な日付(1939年8月6日)は1,362回発生します。

今、最も希少なものを見つけましょう。 これら3つの日付は1回だけ見つかります。

そして、これらはそれぞれ2つです(スペースを節約するために出力が短縮されます)。

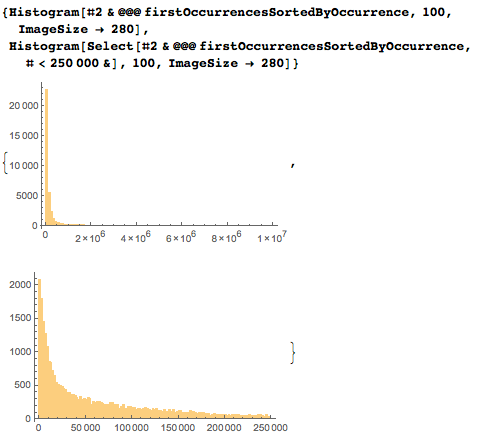
日付の出現回数の分布は次のとおりです。 日付の4桁、5桁、6桁の表示(左から右)に対応する3つのピークは明らかに異なります。 6桁のシーケンスで表される日付はめったに発生しません。 上記のように、平均で約1200回表示されます。

年ごとに日付を収集して表示することもできます(日付が切り捨てられて一意性が確保されるため、末尾の値が低くなります)。 分布はほぼ均一です。
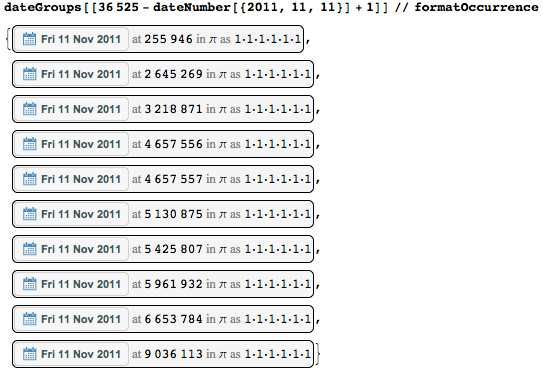
数字の美しいシーケンスと日付が表示される頻度を見てみましょう。 dateGroupsの結果は日付でソートされているため、指定した日付に簡単にアクセスできます。 日付11-11-11はどこですか?
そして、日付は1-23-45ですか?

日付はそれ自体の位置から始まりません(つまり、1945年1月1日[1-1-4-5]が位置1145であるという事実のような例はありません)。

しかし、「回文の場合」が1つあります。1985年3月3日(3.3.8.5)は回文の位置5833にあります。
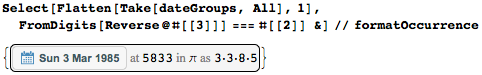
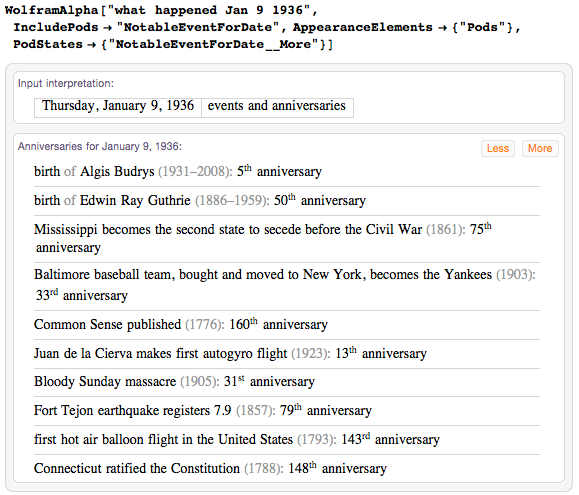
非常に特別な日付は1936年1月9日です。1936年の素数の位置-16,747に表示されます。

歴史の中でこの日に思い出に残るイベントを見てみましょう。
その位置に表示される日付は1つではなかったため、条件を緩和し、その位置に「重なる」すべての日付を見つけることができます。

そして、piの最初の1000万桁で100回以上、piの最初の桁-314159のよく知られた組み合わせを見つけることができます。

円周率の中には、誕生日の日付だけでなく、たとえば1945年10月5日に100周年として祝われたħ日(プランク定数の減少の日)などの物理定数の日もあります。

一致する日付の位置は次のとおりです。
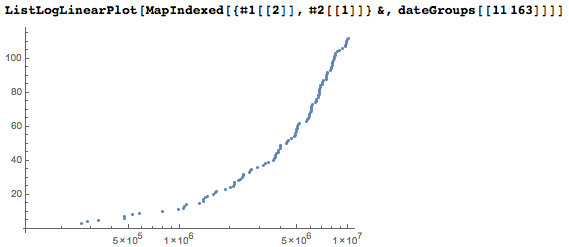
そして、これはすべての日付の発生を視覚化する試みです。 日付桁プレーンでは、各日付の開始点を設定します。 数値の位置には対数目盛を使用しているため、グラフの上部のポイント数ははるかに多くなっています。

数字の早い順に日付が表示される場合、数字の最後の日付のボリュームも視覚化できます。 日付は4〜6桁で指定されます。 次のグラフは、最初の10,000桁で始まるすべての日付の数字を示しています。

粗くした後、分布はかなり均一になります。

今までは、日付を取得し、piの数字のシーケンスで開始する位置を調べました。 次に、反対のことをしましょう。piの指定された数字を含む日付はいくつですか? 各桁の日付の総数を確認するには、日付を順に切り替えます。

数字ごとに最大20の日付が判明します。

それぞれ200桁の間隔が2つあります。 ほとんどの数字は日付にあることがわかります。
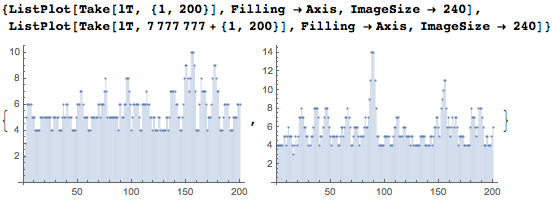
上記のように、数字のシーケンスには約1200万の日付があります。 私が使用した数字のシーケンスは、長さが1,000万桁で、各日付には約5桁が含まれています。 つまり、これらすべての日付には約6000万桁が必要です。 その結果、1,000万桁の多くを再利用する必要があります(平均で約5回)。 日付として解釈されるシーケンスでは、最初の1,000万桁のうち2005のみが使用されます。つまり、すべての桁の99.98%が日付で使用されます(すべてが最初の位置にあるわけではありません)。

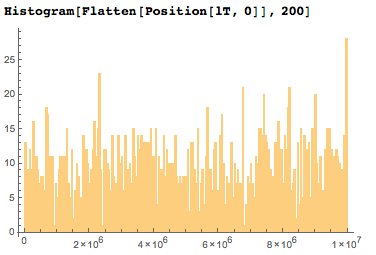
そして、ここに特定の各桁に存在する日付の数の分布のヒストグラムがあります。 多くの計算をしなくても、1桁あたり平均で約6つの日付があることがはっきりとわかります。

2005年の日付以外の数字は、最初の1,000万桁でかなり均等に分布しています。
アイドル番号の特定の位置を予想される平均位置と比較すると、ランダムウォークグラフのようなものが得られます。
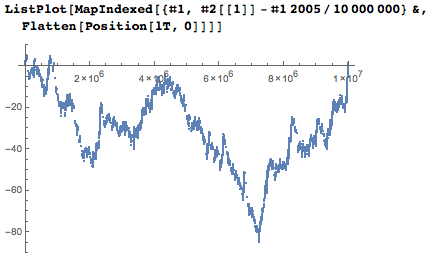
では、未使用の番号は誰と接していますか? 162の異なる5桁の近傍があります。 それらを見ると、中央の数字が日付の一部になれない理由がすぐにわかります。 地区にゼロが多すぎます。

番号の最大未使用ブロックは、位置8,127,088と8,127,093の間の6桁です。

ほとんどの図では、異なる年の日付が重複しています。 下のチャートは、数字の位置の関数として、早期から晩までの年の範囲を示しています。
以下は、未使用の数値と、3つの左隣および3つの右隣人です。

上記のアルゴリズムの動作を説明するために、乱数を取り、それをカバーするすべての日付を見つけます。
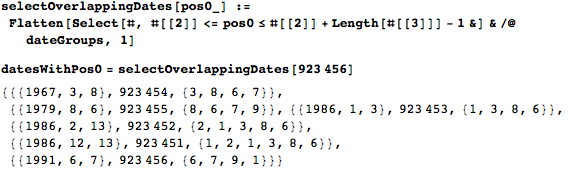
そして、これが日付の「オーバーレイ」の視覚化です。
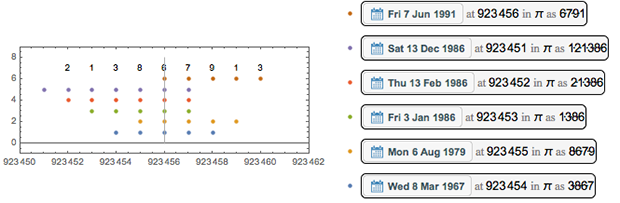
最も使用される数字は、位置2 645 274のユニットです。20の異なる日付に存在します。

ここに彼女の近所の数字と可能な日付があります。
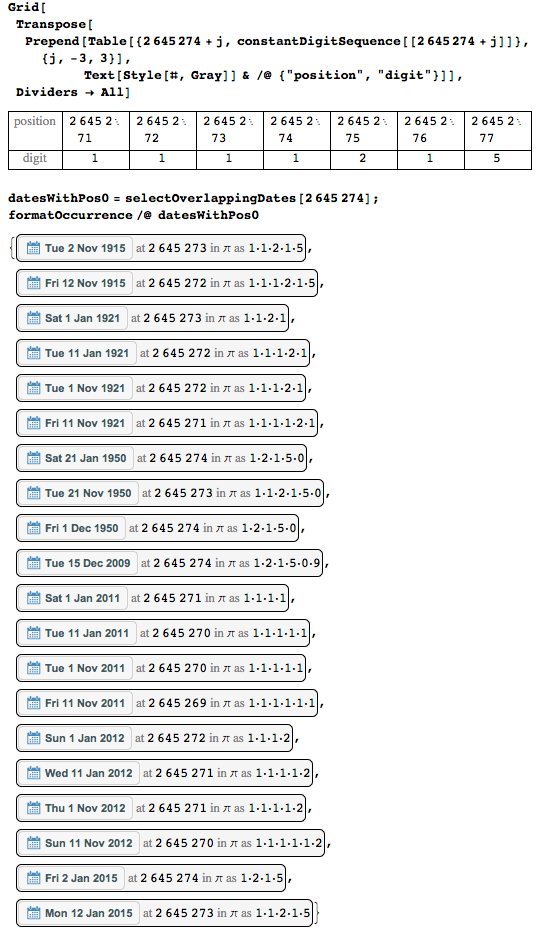
特定の桁で始まる桁数を増やして(たとえば、最初の10,000桁)、桁と日付の面に比較的密な日付カバーが表示されます。

次に、関連する日付をプロットしましょう。 少なくとも1つの共通の数字(必ずしも最初の数字である必要はない)がある場合、2つの日付は関連していると見なします。

同じグラフが最初の600桁についてのみ以下に示されていますが、専用のコミュニティがあります。

ここで、同じ日付の2つのオカレンス間の平均距離を計算します。
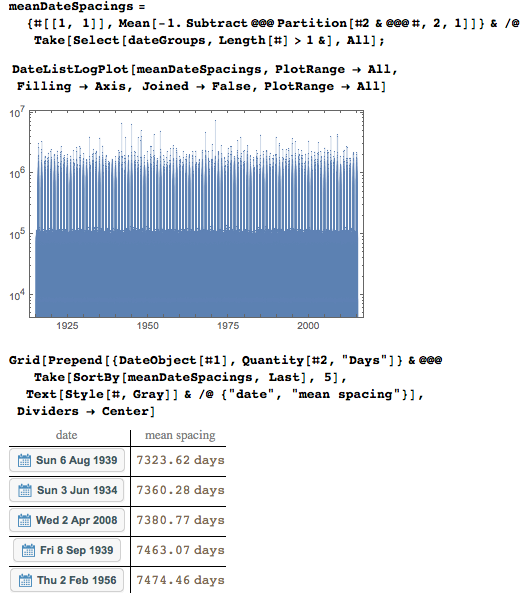
最初の日付
最も興味深いのは、日付の最初の出現であるため、それらを抽出しましょう。 日付リストの2つのバージョンを使用します。1つ目は{date、first date position} ( firstOccurrences )の形式のリストのリストで、2つ目はpi桁の位置番号( firstOccurrencesSortedByOccurrence )でソートされた同じリストです。

piの最初の10桁の日付のすべての可能な解釈。

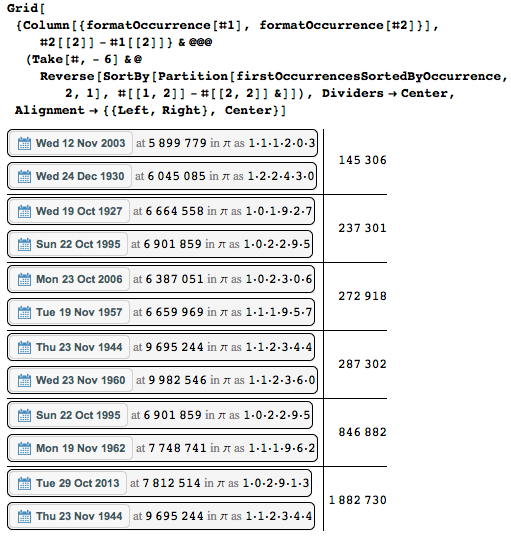
または、ここにもう1つの極端なものがあります-可能な限り遅く初めて発生する日付です。
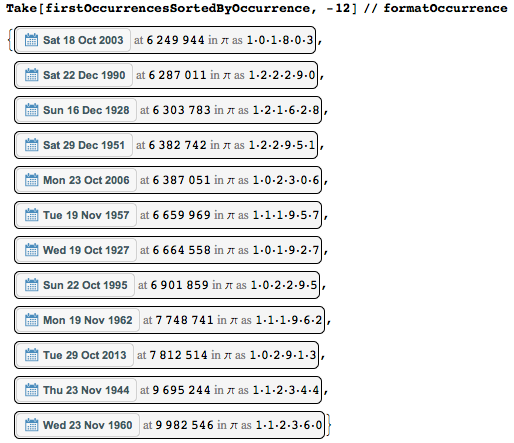
1960年11月23日水曜日が9 982 546(= 2 * 7 * 713039)の位置でのみ開始されることがわかります。したがって、最初の1千万桁のみを使用して、幸運にもそれをキャッチできました。 この「記録」日付の簡単な直接チェックを次に示します。

そして、この日に生まれて幸運な有名人の幸運な人は誰ですか?

そして、最も「深く埋められた」日付のトップ10のそれぞれの間に月はどの段階にありましたか?
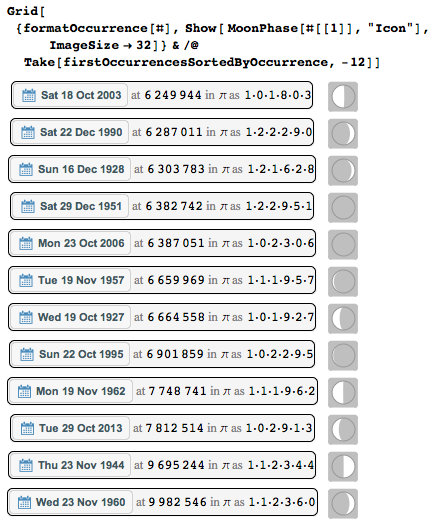
また、1960年11月23日水曜日は10進数の数字列の中で最も遠い日付ですが、素数の形式での最新の位置は1995年10月22日の日付に対応します。

一般に、すべての日付の10%未満がプライムの形でポジションに表示されることがわかります。

多くの場合、平面上の特定の方向にpiの数字を向けて、ランダムウォークを形成します。 日付の最初の出現間の距離に応じて同じことを行います。 典型的な2次元ランダムウォークの画像を取得します。

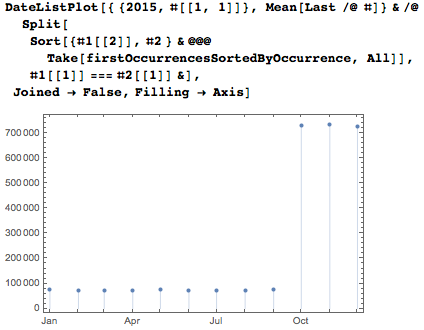
ここに、ここ数年の最初のデートの位置があります。 毎年10月、11月、12月のバーストは、5桁または6桁の順序で日付を設定する必要があるために発生しますが、1月から9月までは、オプションのゼロをスキップするとより少ない桁数で日付を設定できます。
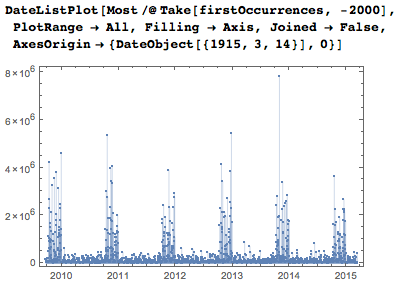
すべての日付を含めると、もちろん、より厳密なグラフが表示されます。
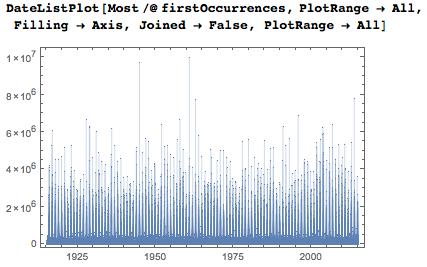
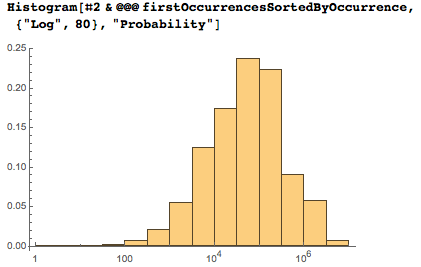
対数の縦軸は、ほとんどの日付が最初に1000分の1から100分の1の間で表示されることを示しています。
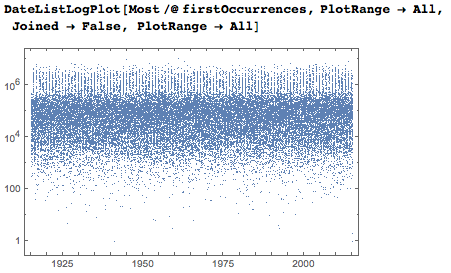
一連の数字(およびその結果として日付)の一般的な均質性とローカルな「事故」をより深く、より直感的に理解するために、日付の最初の出現のポイントに基づいて日桁平面にボロノイ図を与えます。 数値の増加に伴う密度の減少は、日付の最初の出現のみを考慮したという事実によるものです。

復活祭の日曜日は、毎年さまざまな日に当たるため、視覚化には絶好の日です。
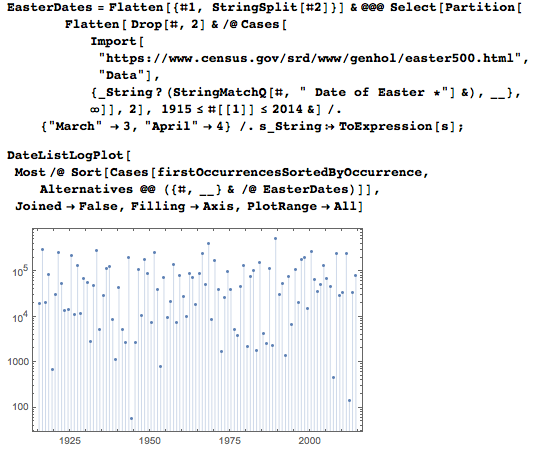
日付を示すのに必要な桁数の関数としての日付の最初の出現の平均位置は、もちろん、エンコードするのに必要な桁数に依存します。

日付の最初の出現の平均位置は239,083になりますが、数百万桁の広がりにより、標準偏差ははるかに大きくなります。

これは、1桁の数字を繰り返すことによって形成される「良い」日付の最初の出現です。
最初の日付の発生数の詳細な分布は、最初の数万桁で最も密度が高くなります。
対数軸は分布を示すのに非常に適していますが、セルサイズが大きくなるため、最大値の解釈は慎重に行う必要があります。
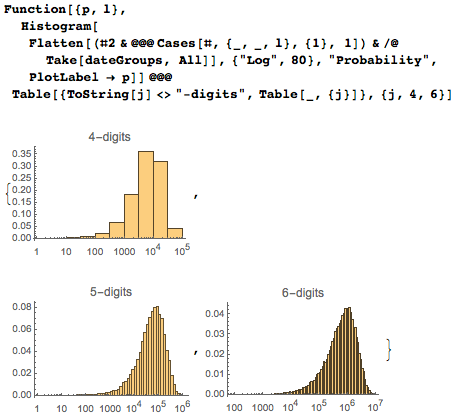
最後の分布は、基本的に、4桁、5桁、および6桁のシーケンスの最初の出現の加重重ね合わせです。
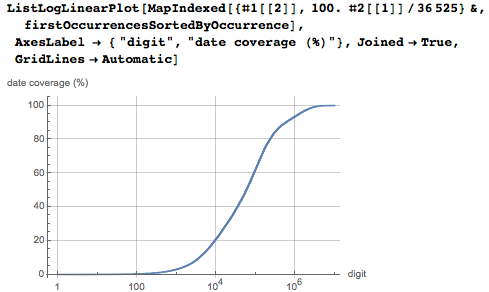
しかし、数字の位置に応じた、日付の累積分布。 1000万桁の最初の1%には、すべての日付の60%がすでに含まれていることがわかります。
偶数の日付には、奇数の日付よりわずかに多くの日付があります。

数字、3、4などの倍数に対しても同じことができます。 左の画像は、対応の各クラスの平均値からの偏差を示し、右の画像は、パリティ基準で考慮される最大の一致を示しています。

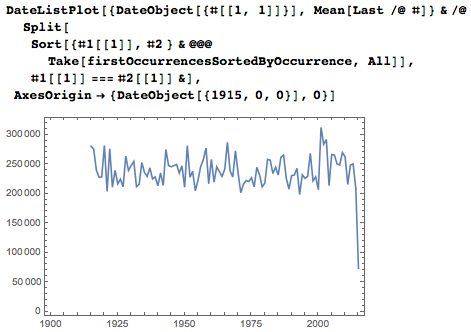
特定の各年における実際の最初の発生数は、平均を中心に変動します。
月でソートされた日付の最初の出現の平均日付は、月の2桁と1桁のレコードを明確に区別します。
月の平均(1〜31)は、主にゆっくり増加する関数です。

最後に、平均的な曜日を示します。 日付の最初の出現のほとんどは、環境に一致する日付です。

上記のように、ほとんどの数字は一部の日付に含まれています。 初めて表示される日付(121,470)には少数の桁のみが含まれています。

いずれの場合もシーケンスの位置の一部はオーバーラップし、オーバーラップする数字のシーケンスで日付のチェーンのネットワークを形成できます。

次のグラフは、連続する日付間のギャップのサイズの増加を示しています。
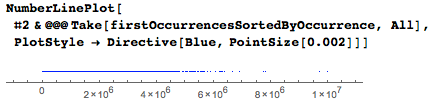
間隔分布:
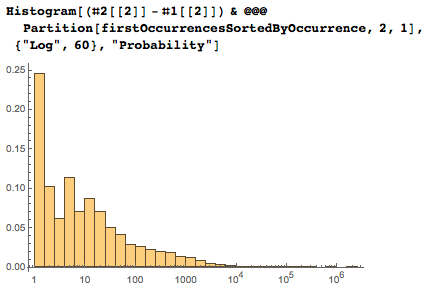
互いに最も離れている連続した日付のペアを次に示します。 最後から2番目の図では、大きなギャップがはっきりと見えます。
他の表現および他の定数の日付
ここで、連続した分数の左側の部分(プラス記号の前の数字)が10進表現の数字と一致する特別な日付を検討します。

これにより、次のpiの継続部分の行が得られます。

そして、興味深いことに、そのような日は1日だけです。

これまでに実行された計算は、piの桁に関して実行されていません。 他の無理数(または合理的に長い有理数)の数字には日付が含まれています。 今年(2015年)の日付を含む多くの数値式を見つけるのは楽しかったです。 ここでは、インタラクティブなデモにまとめられています。
今、私たちは思考の終わりに来ました。 最後の例として、数字の位置を、今年3月14日9:26:53に発生したpi時間の後の秒として解釈してみましょう。 他の定数の10進表現で数字のシーケンス3•1•4•1•5を待つ時間はどれくらいですか? 式(小さな)を見つけることは可能ですか?最初の100万桁で、シーケンス3•1•4•1•5が該当しませんか?(次のリストξsの要素のほとんどはランダムな式です。最後の要素は、数字のシーケンス3を持つ式を検索したときに見つかりました•1•4•1•5可能な限り)

以下に、10進表記の一連の数値を含む2つの有理数を示します。

そして、piの最初の桁を持つ2つの整数があります。

Brett Championが投稿の最後の投稿で説明した新しいTimelinePlot関数を使用して(Habréの投稿「 Wolfram言語の新機能:タイムラインを作成するためのTimelinePlot関数 」を参照)、待機時間を簡単に示すことができます。

読者は、パイの桁で日付のより深い研究を行うか、パイの代わりに別の定数(たとえば、オイラーの数e )を検討することをお勧めします。一般に、質的構造はほぼすべての無理数で同じです(異なる図を見るには、ChampernowneNumber 定数 [10]を試してください)。eの最初の1,000万桁にはすべての日付が含まれますか?また、2014年10月21日にどのような立場になりますか?他の定数にはどのような特別な日付が含まれていますか?これらおよび他の多くの質問が彼らの答えを待っています。