はじめに
グラフィックアクセラレータ(GPU)は、画像およびビデオ処理用に長い間作成されてきました。 ある時点で、GPUは汎用コンピューティングに使用されるようになりました。 しかし、中央処理装置の開発もまだ続きませんでした。インテルは、ベクトル拡張(AVX256、AVX512、AVX1024)の開発に向けて積極的に開発しています。 その結果、異なるプロセッサが表示されます-コア、Xeon、Xeon Phi。 画像処理は、簡単にベクトル化されるこのようなクラスのアルゴリズムに起因します。
しかし、実践が示すように、かなり高いレベルのコンパイラーとXeon Phiの中央プロセッサーとコプロセッサーの適応性にもかかわらず、現代のコンパイラーは自動ベクトル化が不十分であり、ベクトル組み込み関数の使用は非常に難しいため、ベクトル命令を使用して画像処理を行うことはそれほど容易ではありません。 また、手動でベクトル化されたコードとスカラーセクションを組み合わせるという問題も発生します。
この記事では、ベクトル拡張を使用して中央処理装置の中央値フィルタリングを最適化する方法について説明しました。 実験の純度を高めるために、著者と同じ条件をすべて採用しました。3x3の正方形の中央値フィルタリングアルゴリズムを使用し、これらの画像はピクセルあたり8ビットを占有し、フレーム処理(フィルタリング正方形のサイズによる)は行われません。 GPUでこのコアを最適化しようとしました。 5x5平方の中央値フィルタリングのアルゴリズムも検討されました。 アルゴリズムの本質は次のとおりです。
- ソースイメージの各ポイントに対して、特定の近傍(この場合は3x3 / 5x5)が取得されます。
- この近傍のポイントは、明るさの増加によってソートされます。
- ソートされた近傍の中間点が最終画像に記録されます。
最初のGPUカーネル実装
「不必要な」最適化を行わないために、言及された記事の著者の計算を使用します。 最後に、コンピューティングコアの簡単なコードを取得します。
__device__ __inline__ void Sort(int &a, int &b) { const int d = a - b; const int m = ~(d >> 8); b += d & m; a -= d & m; } __global__ void mFilter(const int H, const int W, const unsigned char *in, unsigned char *out) { int idx = threadIdx.x + blockIdx.x * blockDim.x + 1; int idy = threadIdx.y + blockIdx.y * blockDim.y + 1; int a[9] = {}; if (idy < H - 1 && idx < W - 1) { for (int z2 = 0; z2 < 3; ++z2) for (int z1 = 0; z1 < 3; ++z1) a[3 * z2 + z1] = in[(idy - 1 + z2) * W + idx - 1 + z1]; Sort(a[1], a[2]); Sort(a[4], a[5]); Sort(a[7], a[8]); Sort(a[0], a[1]); Sort(a[3], a[4]); Sort(a[6], a[7]); Sort(a[1], a[2]); Sort(a[4], a[5]); Sort(a[7], a[8]); Sort(a[0], a[3]); Sort(a[5], a[8]); Sort(a[4], a[7]); Sort(a[3], a[6]); Sort(a[1], a[4]); Sort(a[2], a[5]); Sort(a[4], a[7]); Sort(a[4], a[2]); Sort(a[6], a[4]); Sort(a[4], a[2]); out[idy * W + idx] = (unsigned char)a[4]; } }
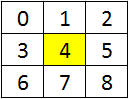
各ポイントについて、この写真に従って近傍がロードされます(結果が計算される画像ピクセルは黄色で強調表示されます)。
この実装では、マイナスが1つあります。画像は8ビット形式で保存され、計算は32ビットで行われます。 CPUでのベクター実装の戦闘コードを見ると、コンパイラーによっては最適化が機能しないため、並べ替え中の不要な操作の除外など、多くの最適化が適用されていることがわかります。 Nvidiaコンパイラーにはこのような欠点はありません-#pragma unrollが指定されていない場合でも、z2およびz1に2つのループを簡単にデプロイできます(この場合、コンパイラーはループ自体をデプロイすることを決定し、十分なレジスターがない場合、ループはデプロイされません)置換後のソート関数の不要な操作は除外されます( インラインの指定は本質的に助言です。コンパイラーの決定方法に関係なく関数を置換する必要がある場合は、 forceinlineを使用する必要があります)。
上記の記事の中央処理装置(Intel Core-i7 4770 3.4 GHz)とほぼ同じリリース年のNvidia GTX 780 Ti GPUでテストします。 画像サイズ-白黒1920 x 1080ピクセル。 コンパイルされた最初のバージョンをGPUで実行すると、次の時間が発生します。
| リードタイム、ミリ秒 | 相対加速度 | ||||
|---|---|---|---|---|---|
| スカラーCPU | AVX2 CPU | Version1 GPU | スカラー/ AVX2 | スカラー/バージョン1 | AVX2 /バージョン1 |
| 24.814 | 0.424 | 0.372 | 58.5 | 66.7 | 1.13 |
上記の時間からわかるように、「ネイティブに」コードを書き換えてGPUで実行するだけで、十分な加速が得られ、画像をサイズに合わせるのに問題はありません。GPUのコードは、どのサイズの画像でも同じように動作しますGPUが完全にロードされたとき)。 また、メモリのアライメントについて考える必要はありません-コンパイラがすべてを行います。特別なCUDA RunTime関数を使用してメモリを割り当てるだけで十分です。
グラフィックアクセラレータに出くわした多くの人は、データをダウンロードしてアップロードし直す必要があるとすぐに言います。 2 MBのイメージに対して15 GB /秒のPCIe 3.0速度を使用すると、一方向伝送で約130マイクロ秒が得られます。 したがって、画像ストリーミングが発生する場合、ロードとアンロードには約260マイクロ秒かかりますが、アカウントには約372マイクロ秒かかります。つまり、最も「ネイティブ」な実装でも、GPUへの転送がカバーされます。 また、画像あたり260マイクロ秒よりも高速であるため、画像ストリームの処理が失敗すると結論付けることもできます。 ただし、1つの画像の処理中にこのフィルターを別の10個のフィルターと併用すると、このカーネルのさらなる最適化が役立ちます。
2番目のGPUコアの実装
ソート操作の効率を高めるために、最近追加されたSIMD命令を使用できます。 これらの命令は、2つのunsigned / signed shortまたは4つのunsigned / signed charの1つの操作で数学関数を計算できる組み込み関数です。 利用可能な機能のリストは、Cuda ToolKitのドキュメントに記載されています 。 2つの関数が必要です:vminu4(unsigned a、usnigned b)およびvmaxu4(unsigned a、unsigned b)。 符号付き8ビット値なしの4xの最小値と最大値を計算します。 4つの値を読み込むには、画像全体を水平方向に4つの部分に分割します。各ブロックは、符号なしintのビットシフトを使用して4つの読み込みポイントを組み合わせて、4つのバンドからデータを読み込みます。
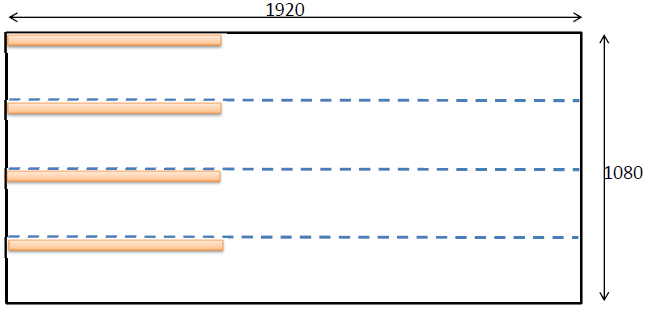
アクティブな処理ゾーンはサイズが1920 x 270の最上部の正方形であるため、128 x 1スレッドのブロックはオレンジ色で表示され、128 * 4の要素がロードされます。 ご存じのように、GPUのワープのサイズは32スレッドで構成されています。 1つのワープのすべてのスレッドは、一度にサイクルごとに1つの命令を実行します。 各スレッドはunsigned char型の4つの要素をアップロードするため、1つのワープは1つの命令で合計128要素の処理を実行します。つまり、1024ビットの処理が得られます。 CPUについては、現在256ビットのAVX2レジスタが使用可能です(将来的には512および1024ビットになります)。 これらの最適化により、コンピューティングコアのコードは次の形式に変換されます。
__device__ __inline__ void Sort(unsigned int &a, unsigned int &b) { unsigned t = a; a = __vminu4(t, b); b = __vmaxu4(t, b); } __global__ __launch_bounds__(256, 8) void mFilter_3(const int H, const int W, const unsigned char * __restrict in, unsigned char *out, const unsigned stride_Y) { int idx = threadIdx.x + blockIdx.x * blockDim.x + 1; int idy = threadIdx.y + blockIdx.y * blockDim.y + 1; unsigned a[9] = { 0, 0, 0, 0, 0, 0, 0, 0, 0 }; if (idx < W - 1) { for (int z3 = 0; z3 < 4; ++z3) { if (idy < H - 1) { const int shift = 8 * (3 - z3); for (int z2 = 0; z2 < 3; ++z2) for (int z1 = 0; z1 < 3; ++z1) a[3 * z2 + z1] |= in[(idy - 1 + z2) * W + idx - 1 + z1] << shift; } idy += stride_Y; } Sort(a[1], a[2]); Sort(a[4], a[5]); Sort(a[7], a[8]); Sort(a[0], a[1]); Sort(a[3], a[4]); Sort(a[6], a[7]); Sort(a[1], a[2]); Sort(a[4], a[5]); Sort(a[7], a[8]); Sort(a[0], a[3]); Sort(a[5], a[8]); Sort(a[4], a[7]); Sort(a[3], a[6]); Sort(a[1], a[4]); Sort(a[2], a[5]); Sort(a[4], a[7]); Sort(a[4], a[2]); Sort(a[6], a[4]); Sort(a[4], a[2]); idy = threadIdx.y + blockIdx.y * blockDim.y + 1; for (int z = 0; z < 4; ++z) { if (idy < H - 1) out[idy * W + idx] = (unsigned char)((a[4] >> (8 * (3 - z))) & 255); idy += stride_Y; } } }
小さな変更の結果、処理された要素の数を4倍(または命令あたり128要素)に増やしました。 コードの複雑さが増し、コンパイラーが生成するレジスタが多すぎるため、GPUを100%読み込むことができません。 まだ簡単な計算があるので、__ launch_bounds(128、16)を使用して、各ストリームプロセッサで可能な最大数のスレッド(このGPUの最大数は2048スレッド)を実行することをコンパイラーに伝えます。各128スレッドの16ブロックの構成が起動されました。 もう1つのイノベーション-テクスチャキャッシュを使用して重複データを読み込むためのrestrictキーワードを追加します(分析すると、多くのデータがあり、ほとんどのポイントが3回読み取られます)。 テクスチャキャッシュを有効にするには、constも指定する必要があります。 表示はすべて次のようになります。
const unsigned char * __restrict in.
2番目のバージョンの関連時間:
| リードタイム、ミリ秒 | 相対加速度 | ||||||
|---|---|---|---|---|---|---|---|
| スカラーCPU | AVX2 CPU | Version1 GPU | Version2 GPU | スカラー/ AVX2 | スカラー/バージョン2 | AVX2 /バージョン2 | バージョン1 /バージョン2 |
| 24.814 | 0.424 | 0.372 | 0.207 | 58.5 | 119.8 | 2.04 | 1.79 |
3番目のGPUコアの実装
すでに加速は悪くありません。 しかし、この距離で4つの要素をロードすると、繰り返しダウンロードが多すぎることがわかります。 これにより、パフォーマンスが大幅に低下します。 既にレジスターに直接ロードしたものを使用して、データの局所性を改善する方法はありますか? はい、できます! これらの4行を互いに近くに配置すると、ブロックの始まりが距離4で高さ全体に「塗り付けられます」。したがって、Yに沿ったスレッドのブロックのサイズを考えると、次のコードに到達します。
#define BL_X 128 #define BL_Y 1 __device__ __inline__ void Sort(unsigned int &a, unsigned int &b) { unsigned t = a; a = __vminu4(t, b); b = __vmaxu4(t, b); } __global__ __launch_bounds__(256, 8) void mFilter_3a(const int H, const int W, const unsigned char * __restrict in, unsigned char *out) { int idx = threadIdx.x + blockIdx.x * blockDim.x + 1; int idy = threadIdx.y + blockIdx.y * blockDim.y * 4 + 1; unsigned a[9] = { 0, 0, 0, 0, 0, 0, 0, 0, 0 }; if (idx < W - 1) { for (int z3 = 0; z3 < 4; ++z3) { //if (idy < H - 1) <---- this is barrier for compiler optimization { const int shift = 8 * (3 - z3); for (int z2 = 0; z2 < 3; ++z2) for (int z1 = 0; z1 < 3; ++z1) a[3 * z2 + z1] |= in[(idy - 1 + z2) * W + idx - 1 + z1] << shift; } idy += BL_Y; } Sort(a[1], a[2]); Sort(a[4], a[5]); Sort(a[7], a[8]); Sort(a[0], a[1]); Sort(a[3], a[4]); Sort(a[6], a[7]); Sort(a[1], a[2]); Sort(a[4], a[5]); Sort(a[7], a[8]); Sort(a[0], a[3]); Sort(a[5], a[8]); Sort(a[4], a[7]); Sort(a[3], a[6]); Sort(a[1], a[4]); Sort(a[2], a[5]); Sort(a[4], a[7]); Sort(a[4], a[2]); Sort(a[6], a[4]); Sort(a[4], a[2]); idy = threadIdx.y + blockIdx.y * blockDim.y * 4 + 1; for (int z = 0; z < 4; ++z) { if (idy < H - 1) out[idy * W + idx] = (unsigned char)((a[4] >> (8 * (3 - z))) & 255); idy += BL_Y; } } }
この方法で最適化されたコードにより、コンパイラは既にロードされたデータを使用できます。 唯一の問題は、状態をチェックすることです(idy <H-1)。 このチェックを削除するには、必要な行数を追加する必要があります。つまり、画像を垂直方向に4段揃えし、すべての追加要素を最大数(255)で埋める必要があります。 コードを3番目のオプションに変換すると、時間は次のようになります。
| リードタイム、ミリ秒 | 相対加速度 | ||||||
|---|---|---|---|---|---|---|---|
| スカラーCPU | AVX2 CPU | Version1 GPU | Version2 GPU | Version2 GPU | スカラー/ AVX2 | スカラー/バージョン3 | AVX2 /バージョン3 |
| 24.814 | 0.424 | 0.372 | 0.207 | 0.130 | 58.5 | 190.8 | 3.26 |
さらに、計算はそれほど多くないため、最適化することはすでに非常に困難です。 共有メモリの使用に関する問題は、ここでは対処しませんでした。 共有メモリを使用する試みがいくつかありましたが、最高の時間を得ることができませんでした。 画像処理速度をそのサイズに関連付けると、画像のサイズが揃っているかどうかに関係なく、約15ギガピクセル/秒を得ることができます。
GPUの5x5メディアンフィルターのコア
すべての最適化を適用すると、わずかな変更を加えた5x5の正方形のフィルターを実装できます。 このコードの複雑さは、25個の要素に対する部分的なバイトニックソートの正しい実装にあります。 同様に、任意のサイズのフィルターを実装できます(ある種のフィルターサイズから開始すると、一般的な並べ替えアルゴリズムがおそらく高速になります)。
__global__ __launch_bounds__(256, 8) void mFilter5a(const int H, const int W, const unsigned char * in, unsigned char *out, const unsigned stride_Y) { int idx = threadIdx.x + blockIdx.x * blockDim.x + 2; int idy = 4 * threadIdx.y + blockIdx.y * blockDim.y * 4 + 2; if (idx < W - 2) { unsigned a[25] = { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 }; for (int t = 0; t < 4; ++t) { const int shift = 8 * (3 - t); for (int q = 0; q < 5; ++q) for (int z = 0; z < 5; ++z) a[q * 5 + z] |= (in[(idy - 2 + q) * W + idx - 2 + z] << shift); idy++; } Sort(a[0], a[1]); Sort(a[3], a[4]); Sort(a[2], a[4]); Sort(a[2], a[3]); Sort(a[6], a[7]); Sort(a[5], a[7]); Sort(a[5], a[6]); Sort(a[9], a[10]); Sort(a[8], a[10]); Sort(a[8], a[9]); Sort(a[12], a[13]); Sort(a[11], a[13]); Sort(a[11], a[12]); Sort(a[15], a[16]); Sort(a[14], a[16]); Sort(a[14], a[15]); Sort(a[18], a[19]); Sort(a[17], a[19]); Sort(a[17], a[18]); Sort(a[21], a[22]); Sort(a[20], a[22]); Sort(a[20], a[21]); Sort(a[23], a[24]); Sort(a[2], a[5]); Sort(a[3], a[6]); Sort(a[0], a[6]); Sort(a[0], a[3]); Sort(a[4], a[7]); Sort(a[1], a[7]); Sort(a[1], a[4]); Sort(a[11], a[14]); Sort(a[8], a[14]); Sort(a[8], a[11]); Sort(a[12], a[15]); Sort(a[9], a[15]); Sort(a[9], a[12]); Sort(a[13], a[16]); Sort(a[10], a[16]); Sort(a[10], a[13]); Sort(a[20], a[23]); Sort(a[17], a[23]); Sort(a[17], a[20]); Sort(a[21], a[24]); Sort(a[18], a[24]); Sort(a[18], a[21]); Sort(a[19], a[22]); Sort(a[9], a[18]); Sort(a[0], a[18]); Sort(a[8], a[17]); Sort(a[0], a[9]); Sort(a[10], a[19]); Sort(a[1], a[19]); Sort(a[1], a[10]); Sort(a[11], a[20]); Sort(a[2], a[20]); Sort(a[12], a[21]); Sort(a[2], a[11]); Sort(a[3], a[21]); Sort(a[3], a[12]); Sort(a[13], a[22]); Sort(a[4], a[22]); Sort(a[4], a[13]); Sort(a[14], a[23]); Sort(a[5], a[23]); Sort(a[5], a[14]); Sort(a[15], a[24]); Sort(a[6], a[24]); Sort(a[6], a[15]); Sort(a[7], a[16]); Sort(a[7], a[19]); Sort(a[13], a[21]); Sort(a[15], a[23]); Sort(a[7], a[13]); Sort(a[7], a[15]); Sort(a[1], a[9]); Sort(a[3], a[11]); Sort(a[5], a[17]); Sort(a[11], a[17]); Sort(a[9], a[17]); Sort(a[4], a[10]); Sort(a[6], a[12]); Sort(a[7], a[14]); Sort(a[4], a[6]); Sort(a[4], a[7]); Sort(a[12], a[14]); Sort(a[10], a[14]); Sort(a[6], a[7]); Sort(a[10], a[12]); Sort(a[6], a[10]); Sort(a[6], a[17]); Sort(a[12], a[17]); Sort(a[7], a[17]); Sort(a[7], a[10]); Sort(a[12], a[18]); Sort(a[7], a[12]); Sort(a[10], a[18]); Sort(a[12], a[20]); Sort(a[10], a[20]); Sort(a[10], a[12]); idy = 4 * threadIdx.y + blockIdx.y * blockDim.y * 4 + 2; for (int z = 0; z < 4; ++z) { if (idy < H - 2) out[idy * W + idx] = (unsigned char)((a[12] >> (8 * (3 - z))) & 255); idy++; } } }
このサイズのフィルターの処理速度はAVX2を使用すると約5.7倍速くなりますが、GPUバージョンは3.8倍(約0.5ミリ秒)だけ遅くなります。 5×5平方の中央値フィルタリングによるGPUでの最終的な加速は、AVX2バージョンと比較して5倍に達する可能性があります。
おわりに
結論として、結果の一部を要約できます。 順次スカラープログラムを最適化することにより、GPUを使用して大きな加速を実現できます。 メジアンフィルターの場合、フィルターの半径に応じて、加速度値は1000倍に達する可能性があります。 もちろん、AVX2命令を使用した非常に最適なバージョンは、GPUとCPUの間のギャップを劇的に削減します。 しかし、個人的には、コードを手動でベクトル化することは実際に考えられるほど簡単ではないと結論づけることができます。 それどころか、GPUの最も「ネイティブ」な実装でさえ、かなり高い加速を提供します。 ほとんどの場合、これで十分です。 また、1つのマザーボードのグラフィックスカードの数が複数になる可能性があると考えると、画像またはビデオのフローの処理における全体的な加速が直線的に増加する可能性があります。
GPUを使用するかどうかの問題は修辞的なものです。 もちろん、画像とビデオを処理するタスクでは、GPUのパフォーマンスが向上し、計算負荷が増加すると、CPUとGPUの処理速度の差が大きくなり、後者の方が有利になります。
戦闘の最適化については、2番目の記事「 Nvidia GPUのメディアンフィルタリングの高速または深層最適化」を参照してください。