1.多くのビッグデータ分析システムと同様に、Watsonの主な目標は、ソーシャルメディアの製品、企業、ブランド、およびサービスについてユーザーがどのくらいの頻度で、どのように書くかを簡単な方法(グラフおよび写真)でユーザーに提供することです。 AKAは、センチメント分析の結果に基づいてソートされた、メッセージフローに関する言及の頻度です。 Watsonの重要な機能の1つは、この段階ですでに隠れていました。 購入したストリーム。 つまり、情報は別の会社によって収集され、分析のために送信されます。 ツイートや新しいコメントがなく、分析で考慮されなかった場合、すべての質問は...ワトソンのものではありません。 今日、分析用の資料は、Twitter、フォーラム、ニュース、YouTube(より正確には、人々が壁に残したすべてのコメント)、Facebookの公開ページ、レビュー、ブログから入手できます。 同時に、上記のソースからのメッセージは定量分析にのみ使用され、Twitterとの合意によると、同社はユーザーがネットワーク上で書いているものや一般の人々が満足している(満足していない)ものをユーザーに読ませる権利がありません。 同時に、Twitter自体ではこれは簡単で簡単です。検索バーに必要な単語を入力するだけです...
2.前の段落に直接依存するプラス面は、無制限の数のトピックを開始する機会と考えることができます。 例: マシン1、マシン2、マシン3、マシン4 ...マシンN ...また、トピックの個別のトピックを作成するためのシステムへの追加ボーナス、または異なる方法で、特性: 寸法、燃料消費量、エンジン機能など 。 各トピック内で、メッセージストリームでキャッチする必要がある必要な検索語または用語の両方と、除外キーワードを指定できます。 たとえば、ドイツのOBI(OBI)ハイパーマーケットに関するメッセージを分析する状況では、スターウォーズのキャラクターを除外する必要があります。 オブジェクトがあいまいな場合に最も正確な検索クエリを作成するには、ヒントを使用できます。右側のフィールドには、オブジェクトで使用される最も頻繁な単語の雲が表示されます。 残念ながら、システムは常に多値オブジェクトを認識できるかどうかはわからず、ヒントは既知の多義語のリストでのみ機能します。

3.この時点で、ワトソンが作成した実際の分析を分析します。 ソーシャルメディアメッセージの分析で最も重要かつ基本的なポイントの1つは、人口統計学です。 つまり、性別、年齢、地理的位置による分布です。 ここで、この分析は言語学のおかげで実行されることに注意する必要があります。これは、多くの問題がこれに関連していることを意味します。
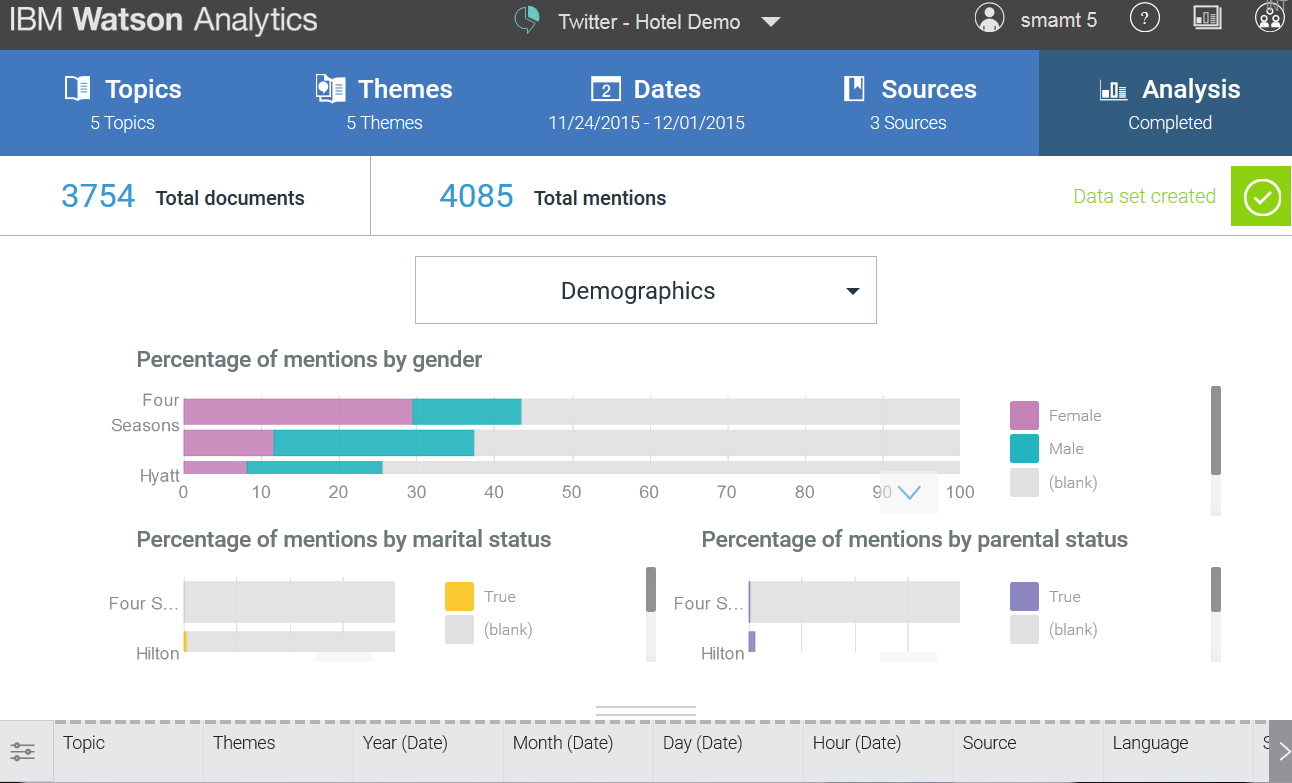
- 性別の分布は、名前(辞書)、ニックネーム( Mr.Xは男性の指標になり、「 リトルマーメイド99 」-女性)、および「 私は母親になりました 」のテキストで使用される特定の単語による男性/女性です。 、「 私は父親になった 」-男性。 これが常に正しく機能するかどうかは別の問題です。 一部のニックネームでは、特定の性別を人に明確に帰属させることはできません。また、コメントで異性の皮肉な使用を禁止する人はいません。
- 「既婚/独身」という指標もあります-情報はプロファイルとメッセージテキストから取得されます。 つまり、「 my wife 」という表現が見つかった場合、 「married」のステータスが呼び出されます。
- 「子供のいない/子供と」という指標も同様に機能します。 私の意見では、最後の2つの指標は最も物議をかもします。 ワトソンでは、直接の音声を区別しません。 これは、「 友人/ボーイフレンドの言葉から...私の夫/息子が何かをした 」などのメッセージが誤って処理されることを意味します。 友人からの情報は話者に帰属します。
- しかし、最も重要な指標である年齢と地理はどうでしょうか? しかし、年齢に関するデータはありません。 絶対に。 なし。 また、地理は、メッセージ内の都市および国の名前の言及によって決定されます。 そして、私たちのうち何人が、モスクワやサンクトペテルブルクにいて、サラトフやヴォロネジにいると書いたのでしょうか? だから、コメントはありません。
4.ワトソンが話す言語の範囲は非常に広いですが、メッセージの感情分析(Analysis of Social Mediaと呼ばれるケーキの主な成分)に興味がある場合、状況はさらに悪くなります。 1つの言語を追加するには、約9か月かかります。 現時点では、英語(疑いのある人は誰でも)、フランス語、ドイツ語、スペイン語、オランダ語、中国語(伝統的および簡易版)、ロシア語、およびポルトガル語はすでに非常にうまく機能しています。
Watsonは、次のタイプの調性を区別します:ポジティブ、ネガティブ、アンビバレンス。 最初の2つのタイプが説明なしで理解できる場合、後者は不明確な場合、ポジティブまたはネガティブな場合を指します。 例:「 このカメラのカラーレンダリングは良好ですが、音は粗雑です。」 カメラのみを考慮し、個々の特性を考慮しない場合、色調はあいまいになります。 ワトソンの調性の利点の1つは、ポジティブまたはネガティブに処理されるべきではない単語を「音調辞書」に個人的に追加できることです。 例としては、広告キャンペーンのスローガンがあります(「 戦車は泥を恐れません! 」)。 「無視する」というスローガンを追加しない場合、調性に関する不正確なデータ、実際には存在しない多くの肯定的なものを受け取ります。 これは特定の顧客に対してのみ機能します。つまり、特定の製品に対してのみキーを変更し、すべてに対してグローバルにではありません。 使用される辞書の大きな欠点の1つは、キーの強度を考慮していないことです。 つまり、ワトソンにとって「 悪い-ひどい-嫌な 」という言葉も同様に否定的です。 しかし、誰もがこれはそうではないと言うでしょう。
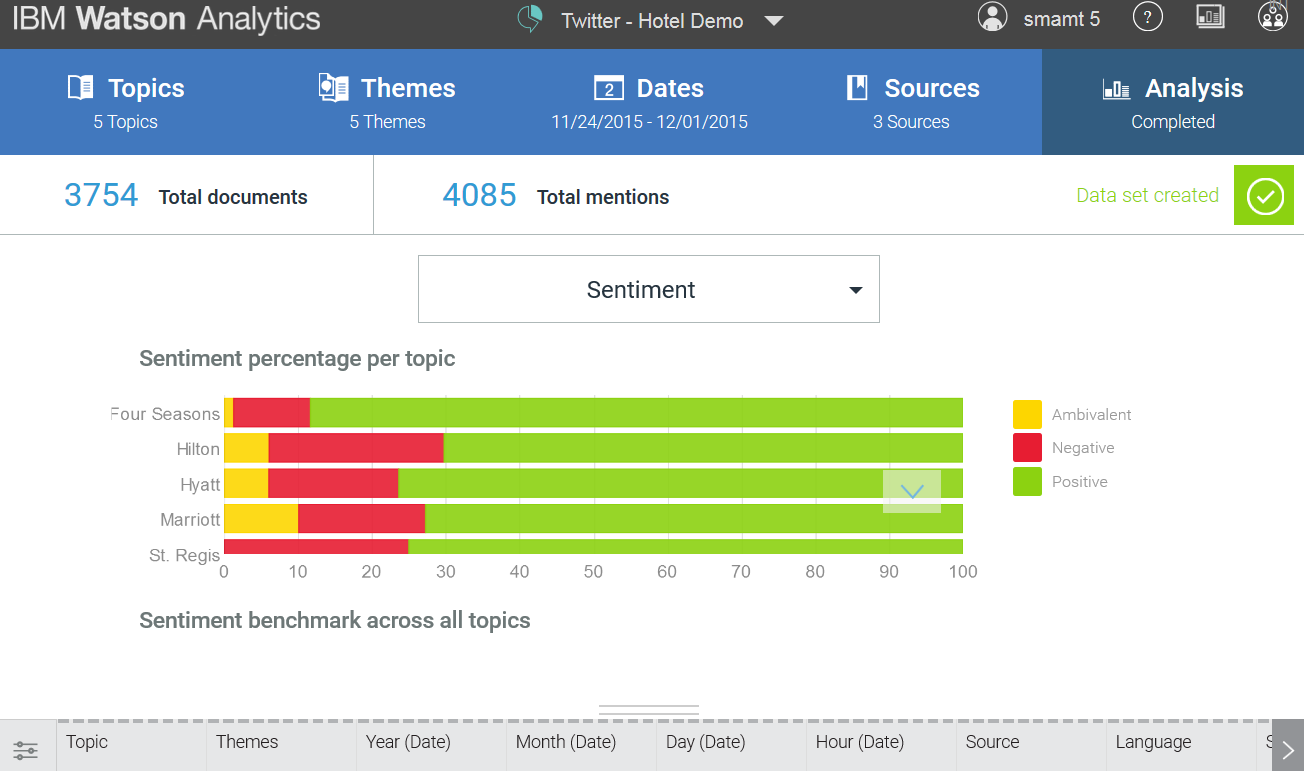
さらに、言語学(感情分析、文を部分に分割し、上記の人口統計)がルールに作用します。 AQL(注釈クエリ言語)は、調性の構文と操作を記述するために使用されます。 どのように機能するかは、公式のIBM Webサイトで確認できます。
ルールに対するアプローチの利点 :十分な忍耐力で、言語の特定のフレーズの使用のケースと機能の85-90%を説明できます。
欠点 :ルールを作成するときに考慮されなかった重要なメッセージ層が抜け落ちることがあります。 また、マシンアルゴリズムを簡単に再トレーニングできる場合は、新しいルールを規定するのにはるかにコストがかかります(以前のルールと競合しないように、実行の優先順位に違反しないようにします)。 また、ルールは言語によって異なります。 1つのグループの関連言語について、同じ「定式化」をわずかな修正で使用できる場合、これはよりまれな言語を説明するために機能しません。 いいえ、いくつかのベースは残りますが、....
悲しいかな、ワトソンは、調性の仕事をチェックするためにあなたのメッセージをアップロードすることを許可しておらず、どこでもモジュールの正確性に関するデータを見つけることができません。 分析システムをポジティブまたはネガティブなメッセージとして使用する場合でも、ユーザーはすべてのステートメントを完全に見るのではなく、ごく一部、そして一意に決定されたステートメントのみを見ます。
まとめ
このシステムは、明るくてカラフルな豊富なグラフと図、およびさまざまな比較基準(人口統計、調性)で目を楽しませます。 使いやすい。つまり、シャーロックである必要はなく、ワトソンになって彼女と仕事をする。 提供される言語が大幅に増えました。 しかし、年齢に関するデータの欠如、性別や地理による分布に関する疑わしいデータ、顧客が不満を持っていることを正確に知ることができないこと(例えば、最も興味深いのは曖昧な声明であり、正に変えることができるものはまさにシステムの信頼性に関する懸念を引き起こします)。 つまり、ワトソンにはまだ成長と開発の余地があり、彼は国内のソーシャルメディア分析システムよりもはるかに優れていると言っています。