リポジトリの何が問題になっていますか? 明らかに、パターン自体はすべて問題ありませんが、違いは開発者の理解にあります。 私はこれを調査しようとしましたが、2つの主要な点に出会いました。これは、私の意見では、彼に対する異なる態度の理由です。 それらの1つはリポジトリの「ローリング」責任であり、もう1つは単体テストの過小評価です。 カットの下で、最初に説明します。
リポジトリの移動責任
アプリケーションアーキテクチャの構築に関しては、誰もがすぐにプレゼンテーション層、ビジネス層、データ層の3つの層を考えます( MSDNを参照 )。 このようなシステムでは、ビジネスロジックオブジェクトはリポジトリを使用して物理ストアからデータを取得します。 リポジトリは、生のレコードセットではなくビジネスエンティティを返します。 これは、物理ストレージのタイプ(ベース、ファイル、またはサービス)を置き換える必要がある場合、抽象的なリポジトリクラスを作成し、必要なストレージに特定のストレージを実装するという事実によって正当化されることが非常に多くあります。 次のようになります。
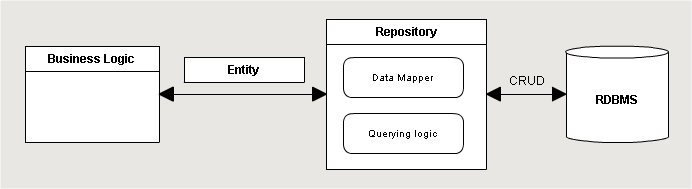
Martin FowlerとMSDNは同じ分離について話している。 通常、説明は単純化されたモデルです。 したがって、これは小さなプロジェクトには正しいように見えますが、このパターンをより複雑なものに移植しようとすると誤解を招きます。 既存のORMはさらに複雑です すぐに多くのことを実装します。 しかし、開発者がデータを取得するためだけにEntity Framework(または別のORM)を使用する方法を知っていると仮定します。 たとえば、2次キャッシュ、またはすべてのビジネスオペレーションのログをどこに配置する必要がありますか? これを行うために、機能別にモジュールを分離し、SOLIDからSPRをたどり、それらからコンポジションを構築しようとすることは明らかです。おそらく次のようになります。

リポジトリは以前と同じ役割を果たしていますか? 現在、ストレージからデータを取得しないため、明らかな答えは「NO」です。 この責任は別の施設に移されました。 これに基づいて、抽象主義者とコンクリート主義者の陣営の間で最初の矛盾が生じる。
分析の代わりに
コードの変更に関係なく、すべての用語が意味を保持することを原則として受け入れる場合、最初の段階では、オブジェクトを単にデータを返すリポジトリと呼ばないことが正しいでしょう。 これは純水のDAOパターンです。 そのタスクは、特定のデータアクセスインターフェイス(ling、ADO.NETなど)を非表示にすることです。 同時に、リポジトリはそのような詳細について何も知らない可能性があり、すべてのデータアクセスサブシステムを単一の構成に収集します。
そのような問題が存在すると思いますか?