この記事では、パスポート認識プログラムの冒険について引き続き説明します。パスポートはエルブラスに送られます!

それでは、Elbrusアーキテクチャについて何を知っていますか?
Elbrusは、高い安全性と信頼性を特徴とする、高性能でエネルギー効率の高いプロセッサアーキテクチャです。 Elbrusアーキテクチャの最新のプロセッサは、サーバー、デスクトップコンピューター、さらには組み込みコンピューターとしても使用できます。 情報セキュリティ、使用温度範囲、製品のライフサイクルに対する増大する要件を満たすことができます。 MCSTの出版物[1、2]が示すように、Elbrusアーキテクチャプロセッサは、信号処理、数学モデリング、科学計算、および計算能力の要件が増加した他のタスクの問題を解決するように設計されています。
Smart Enginesでは、エルブルスのパフォーマンスが、速度を大幅に低下させることなくパスポート認識を実現するのに十分であることを確認しようとしました。
概要:Elbrusアーキテクチャの機能
Elbrusアーキテクチャは、広範なコマンドワード(Very Long Instruction Word、VLIW)の原理を使用するアーキテクチャのカテゴリに属します。 VLIWアーキテクチャーを搭載したプロセッサーでは、コンパイラーは一連のコマンド(ワイドコマンドワード)のグループのシーケンスを生成します。グループ内のチーム間の依存関係はなく、異なるグループのチーム間の依存関係は最小限に抑えられます。 これらのコマンドグループは並列で実行され、操作レベルで高レベルの並列処理を提供します。

コマンドレベルでの並列化は、最適化コンパイラによって完全に提供されます。これにより、たとえばx86アーキテクチャの場合のように、並列化タスクが解決されないため、コマンドの実行装置が大幅に簡素化されます。 システムの消費電力が削減されます。これらのタスクはすべてコンパイラに割り当てられるため、プロセッサはオペランド間の依存関係を分析したり、操作を並べ替えたりする必要がなくなります。 コンパイラーは、ハードウェアバイナリコードアナライザーよりもはるかに大きな計算および時間リソースを持っているため、より徹底的な分析を実行し、より独立した操作を見つけ、その結果、より効率的に実行される幅広いコマンドワードを形成できます。
操作の並列処理の使用に加えて、Elbrusアーキテクチャは、計算処理に固有のその他のタイプの並列処理の実装も実装します。ベクトル並列処理、共有メモリの制御フローの並列処理、マルチマシンコンプレックスのタスクの並列処理です。
さらに、Elbrusアーキテクチャは、Intel x86アーキテクチャとバイナリ互換であり、動的なバイナリ変換に基づいて実装されています。
Elbrusアーキテクチャのもう1つの重要な機能は、実行時にプログラムとデータを保護するためのハードウェアサポートです。 プログラムは、ハードウェアレベルで実装された単一の仮想空間で実行されます。これにより、悪意のあるコードが実行される可能性が最小限に抑えられ、他のアーキテクチャでは検出が困難なエラーを検出できます。
したがって、Elbrusプロセッサのアーキテクチャの主な機能[3、4]:
- 並列エネルギー効率の良いコアアーキテクチャ。
- コンパイラを使用したコマンドフローの自動並列化。
- プロテクトモードが利用できるため、作成されるソフトウェアの信頼性とセキュリティが向上します。
- 一般的なマイクロプロセッサアーキテクチャとの互換性。
エルブラスとの知り合い
使用した特定のマシンはElbrus 4.4で、4つの4コアElbrus 4Cプロセッサと3つのメモリコントローラ、3つのプロセッサ間通信チャネル、1つのI / Oチャネル、8 MB L2キャッシュ(コアあたり2 MB)を組み合わせました。 。 Elbrus 4Cの動作クロック周波数は800 MHz、技術基準は65 nm、平均消費電力は45ワットです。 オペレーティングシステム-Linuxに基づいて作成されたOS「Elbrus」。 uname -a
示したものは次のとおりです。

Elbrusの最適化コンパイラはlccと呼ばれます。 2015年8月27日付けのgcc 4.4.0と互換性のあるLccバージョン1.20.09がサーバーにインストールされました。 lccは標準のgccフラグと連携し、いくつかの追加フラグも定義します。 標準フラグから、-ffastと-ffast-mathに注意を払いました。 これらのオプションには、実際の演算による変換が含まれているため、デフォルトでオフになっています。これにより、実際の操作および機能についてIEEEまたはISO規格に厳密に従う必要があるプログラムの誤った結果が生じる可能性があります。 さらに、それらには潜在的に危険な最適化が含まれており、まれにポインターを自由に操作するプログラムの不正な動作につながる可能性があります。 両方のフラグには、さらに-fstdlib、-faligned、-fno-math-errno、-fno-signed-zeros、-ffinite-math-only、-fprefetch、-floop-apb-conditional-loads、-fstrict-aliasingが含まれます。 それらの使用は、プログラムのパフォーマンスに大きく影響します。
さらに、lccでは最適化を微調整できます。たとえば、関数置換パラメーターを設定するための一連のフラグがあります。
表1.フラグlcc。関数の置換のパラメーターを制御できます。
| Lccフラグ | 予定 |
|---|---|
| -finline-level = <f> | 置換強度の増加係数を設定します[0.1-20.0] |
| -finline-scale = <f> | 主なリソース制限の増加係数を設定します[0.1-5.0] |
| -finline-growfactor = <f> | 置換後のプロシージャのサイズの最大増加を設定します[1.0-30.0] |
| -finline-prog-growfactor = <f> | 置換後のプログラムサイズの最大増加量を設定します[1.0-30.0] |
| -finline-size = <n> | インラインプロシージャの最大サイズを指定します。 |
| -finline-to-size = <n> | 置換を実行できるプロシージャの最大サイズを指定します。 |
| -finline-part-size = <n> | 部分置換のプロシージャの推定領域の最大サイズを設定します。 |
| -finline-uncond-size = <n> | 無条件に置換されたプロシージャの最大サイズを設定します。 |
| -flib-inline-uncond-size = <n> | 無条件に置換されたライブラリプロシージャの最大サイズを設定します。 |
| -finline-probable-calls = <f> | 呼び出しカウンターが(argument * max_call_count)より小さいプロシージャーの置換を防止します。
ここで、max_call_countは、タスク全体の呼び出し操作の最大カウンターです。 |
| -fforce-inline | インライン指定子を使用した無条件の関数置換が含まれます。 |
| -finline-vararg | 可変数の引数を使用した関数置換が含まれます。 |
| -finline-only-native | 明示的なインライン修飾子を持つ関数のみを置換します |
プロシージャー間の最適化、ポインター分析、データページングなどを設定することもできます。
Elbrusのプロファイリングでは、多くの人が使い慣れたperfを使用できますが、あまり知られていないdprofも使用できます。 さらに、dprofの拡張機能を使用して、プロファイルをvalgrind互換の形式に変換できます。
そのため、私たちの目標は、パスポート認識プログラムのコンソールバージョンを立ち上げることでした。 完全にC / C ++で記述されており、C ++ 11を使用することもあります。 C ++ 11のサポートが記載されていないという事実にもかかわらず、実際にはlccは非常に選択的ではありますがそれを理解しています。 C ++ 11の完全なサポートは、lccの新しいバージョンで計画されています。
厳密にはサポートされていません:
- std :: default_random_engine。 残念ながら、ここではサードパーティの擬似乱数ジェネレーターの使用のみを推奨できます。
- nullptr_t。 nullptrが本当に必要な場合は、代わりに特別に割り当てられたオブジェクトの値を使用する必要があります。
- std :: beginおよびstd :: end。 STLオブジェクトの場合、begin()およびend()メソッドを使用できますが、C / C ++オブジェクトの場合、アドレスを手動で検索する必要があります。
- std ::クロノ::安定した時計。 代わりにstd :: chrono :: high_resolution_clockを使用しましたが、もちろん、std :: chrono :: steady_clockがないため、動作時間の測定にエラーが発生する可能性があります。
- std :: string :: pop_back()メソッドがありません。 ただし、代わりに、std :: string :: erase(size()-1、1)を安全に使用できます。
- std :: to_stringは、double型の引数に対して定義されていません。 この問題は、たとえば、サポートされているlong doubleに変換することで解決されます。
- 標準のSTLコンテナは、コピーの代わりに移動操作を使用して保存オブジェクトとしてstd :: unique_ptrの仕様を提供しません。つまり、std :: map <int、std :: uniqie_ptr>は作成できません。
さらに、std :: unique_ptr、std :: shared_ptrはそれ自体でサポートされています。
さらに、lccはgcc拡張子__uint128_tと、BOM付きのUTF-8エンコードされたソースファイルを混乱させます。
サポートされていないコードを書き直した後、プロジェクトを正常にコンパイルすることができました。 ただし、パスポート認識プログラムを単純に実行することはできませんでした。開始しようとしたときに、バスエラーが発生しました。 ICSTの専門家と相談した結果、問題は、使用しているEigenライブラリ内で発生する不均衡なメモリアクセスであることがわかりました。
Eigenは、C ++ [5]で記述された最適化されたヘッダーのみの線形代数ライブラリです。 行列およびベクトルのさまざまな操作に使用でき、x86 SSE、ARM NEON、PowerPC AltiVec、およびIBM S390xの最適化も含まれています。
Eigen開発者は、ライブラリがElbrusで使用されることを期待していなかったため、サポートされているアーキテクチャのリストにライブラリを含めず、アライメントされたメモリアクセスモードを無効にしました。 MCSTの同僚は、この問題の修正を迅速に支援し、修正方法を示しました。

この追加の結果、必要なEigen機能が獲得されました。 これは、EigenとElbrusの非互換性であり、含まれる最適化によってのみ明らかになることに注意してください。
しかし、私たちの不幸はそこで終わりませんでした。 エラーBusエラーは消えていませんが、ライブラリのコードの実行中に発生しました。 少し調査した結果、認識中に追加の画像コンテナの初期化中に非整列メモリアクセスが定期的に発生することがわかりました。
スピードを上げるために、8ビット画像の行に固定値を入力すると、4バイトの倍数である行の一部があり、32ビット値(元の8ビットをコピーして作成された)が入力され、残りの行はすでに1バイトで入力されていました。 ただし、8ビット画像を割り当てる場合、メモリ内のアライメントは1バイトのみに保証され、このアドレスに32ビット値を書き込もうとしているときにエラーが発生しました。
この問題を解決するために、必要なバイト数の倍数である最も近いアドレスの計算(記述されている場合は4)の計算を行処理の先頭に追加し、このアドレスを1バイトで埋め、このアドレスから既に4バイトを埋めています。
このエラーを修正した後、私たちのプログラムは起動しただけでなく、正しい動作を示しました!


すでに小さな勝利でしたが、先に進みました。 次のステップでは、システムの最適化に直接進みました。 私たちのプログラムは2つのモードで動作します:写真またはスキャンされた画像のパスポートの任意に配置された広がりの認識(任意のモード)、およびビデオのパスポートの認識(モバイルモード)。 2番目のケースでは、パスポートがフレームの大部分を占め、フレームごとにその位置がわずかに変化し、1つのフレームの処理にはドキュメント検索アルゴリズムが大幅に簡略化されていると想定されます。
どこでもモードで1つのテスト画像を認識し、すぐに1つのストリームに移動して、約100秒間Elbrusで動作しました(!)。
最初に、Elbrus 4.4の16コアすべてを使用しようとしました。 16スレッドすべてを効果的に使用することは、プログラムの約3分の1でのみ可能でした。 残りの計算は2つのスレッドに並列化されました。 その結果、認識時間は7.5秒に短縮されました。 インスピレーションを受けて、プロファイラーを見ました。 驚いたことに、次のようなものを見ました。

メインプログラムループ内に素晴らしい場所があることがわかりました。
std::vector<Object> candidates; for (int16_t x = x_min; x < x_max; x += x_step) for (int16_t y = y_min; y < y_max; y += y_step) candidates.emplace_back(x, y, 0.0f);
このコードを繰り返し実行した結果、ベクトルのサイズを変更するオーバーヘッドコストは大幅に増加し、認識時間の16%に達します。 他のアーキテクチャでは、この場所は目立ちませんでしたが、Elbrusではメモリの割り当てが予想外に遅いことが判明しました。 この厄介な見落としを修正した後、動作時間はほぼ1秒短縮されました。
次に、各スレッド(VLIWのメイン「チップ」)内の同時実行性を向上させました。 これを行うために、最短パス-MCSTの専門家によって既に最適化されたEMLライブラリを使用しました。
高性能EMLライブラリ
Elbrusアーキテクチャのマイクロプロセッサ用に、EMLライブラリが開発されました。これは、信号、画像、ビデオ、および数学関数と演算の高性能処理のためのさまざまな関数セットをユーザーに提供するライブラリです[4、6]。
EMLには、次の機能グループが含まれています。
- ベクトル-データベクトル(配列)を操作するための関数。
- 代数-線形代数の関数。
- 信号-信号処理機能。
- 画像-画像処理機能;
- ビデオ-ビデオ処理機能。
- ボリューム-三次元構造の変換関数;
- グラフィックス-図形を描画するための関数。
EMLライブラリは、C / C ++で書かれたプログラムで使用することを目的としています。
低レベルの画像処理関数は、EMLで直接サポートされるか、ベクトル(この場合は画像文字列)を介したEMLの基本的な算術関数で表現できます。
たとえば、32ビット実数の2つの配列の要素ごとの加算:
for (int i = 0; i < len; ++i) dst[i] = src1[i] + src2[i];
EML関数を使用して実行できます。
eml_Status eml_Vector_Add_32F(const eml_32f *pSrc1, const eml_32f *pSrc2, eml_32f *pDst, eml_32s len)
どこで
-
pSrc1
第1オペランドのベクトルへのポインター -
pSrc2
第2オペランドのベクトルへのポインター -
pDst
結果ベクトルへのポインター -
len
ベクトルの要素数
彼女は戻ります
-
EML_OK
関数が正常に機能した場合 -
EML_INVALIDPARAMETER
は、ポインターの1つがNULLであるか、ベクトルの長さが0以下である場合。
合計で、eml_Status列挙は4つの値を取ることができます。
-
EML_OK
エラーなし -
EML_INVALIDPARAMETER
引数または範囲外 -
EML_NOMEMORY
操作用の空きメモリがありません -
EML_RUNTIMEERROR
データ、実行中のエラー
主なデータ型が定義されています:
typedef char eml_8s; typedef unsigned char eml_8u; typedef short eml_16s; typedef unsigned short eml_16u; typedef int eml_32s; typedef unsigned int eml_32u; typedef float eml_32f; typedef double eml_64f;
32ビット実数の要素ごとの乗算の関数も同様に配置されます。
eml_Status eml_Vector_Mul_32F(const eml_32f *pSrc1, const eml_32f *pSrc2, eml_32f *pDst, eml_32s len)
ただし、整数の場合、そのような演算を実行する要素ごとの加算およびシフト乗算関数のみが定義されます。
// Addition for (int i = 0; i < len; ++i) dst[i] = SATURATE((src1[i] + src2[i]) << shift); // Multiplication for (int i = 0; i < len; ++i) dst[i] = SATURATE((src1[i] * src2[i]) << shift);
そして実際にはEML関数:
// int16_t addition eml_Status eml_Vector_AddShift_16S(const eml_16s *pSrc1, const eml_16s *pSrc2, eml_16s *pDst, eml_32s len, eml_32s shift) // int32_t addition eml_Status eml_Vector_AddShift_32S(const eml_32s *pSrc1, const eml_32s *pSrc2, eml_32s *pDst, eml_32s len, eml_32s shift) // uint8_t addition eml_Status eml_Vector_AddShift_8U(const eml_8u *pSrc1, const eml_8u *pSrc2, eml_8u *pDst, eml_32s len, eml_32s shift) // int16_t multiplication eml_Status eml_Vector_MulShift_16S(const eml_16s *pSrc1, const eml_16s *pSrc2, eml_16s *pDst, eml_32s len, eml_32s shift) // int32_t multiplication eml_Status eml_Vector_MulShift_32S(const eml_32s *pSrc1, const eml_32s *pSrc2, eml_32s *pDst, eml_32s len, eml_32s shift) // uint8_t multiplication eml_Status eml_Vector_MulShift_8U(const eml_8u *pSrc1, const eml_8u *pSrc2, eml_8u *pDst, eml_32s len, eml_32s shift)
このような関数は、たとえば整数演算に役立ちます。
EMLは画像の構造を定義します:
typedef struct { void * data; /**< */ eml_image_type type; /**< */ eml_32s width; /**< , x */ eml_32s height; /**< , y */ eml_32s stride; /**< */ eml_32s channels; /**< () */ eml_32s flags; /**< */ void * state; /**< */ eml_32s bitoffset;/**< */ eml_format format; /**< */ eml_8u addition[32 - 2 * sizeof (void *)]; /**< 64 */ } eml_image;
画像でサポートされているeml_image_typeデータ型:
- EML_BIT-1ビットの符号なし整数データ
- EML_UCHAR-8ビット符号なし整数データ
- EML_SHORT-16ビット符号付き整数データ
- EML_INT-32ビット符号付き整数データ
- EML_FLOAT-32ビット浮動小数点データ
- EML_DOUBLE-64ビットの浮動小数点データ
- EML_USHORT-16ビット符号なし整数データ
EMLは、画像処理に必要な他の機能もサポートしています。 たとえば、分離可能なフィルターの効果的な実装に必要な転置関数は次のとおりです。
eml_Status eml_Image_FlipMain(const eml_image *pSrc, eml_image *pDst)
この関数は、元の画像の中心を結果の画像の中心に重ね、転置を実行します。 彼女の作品は次の式で説明できます。
dst[width_dst/2 + (y - height_src/2), height_dst/2 + (x - width_src/2)] = src[x, y], x = [0, width-1], y = [0, height-1]
画像は同じデータ型( EML_UCHAR, EML_SHORT, EML_FLOAT EML_DOUBLE
)であり、同じチャネル数(1、3、または4)である必要があります。
実験と結果
表2は、さまざまなデータ型の加算と乗算の実行時間を示しています。 この実験では、長さ10 5 50の2つの配列の加算/乗算の1000回の反復の実行時間を測定し、得られた値から中央値を取りました。 この表は、1回の反復の平均実行時間を示しています。 EMLを使用すると、実際の32ビット数と8ビット符号なし整数の計算を大幅に高速化できることがわかります。 これらのデータ型は最適化された画像処理パスで頻繁に使用されるため、これは重要です。
表2.長さ10 5の配列のElbrus 4.4による加算と乗算の実行時間。
| 追加 | ||
|---|---|---|
| データ型 | uint8_t | 浮く |
| EMLなし、μs | 16.7 | 148.8 |
| EML、μs | 8.0 | 83.6 |
| 乗算 | ||
|---|---|---|
| データ型 | uint8_t | 浮く |
| EMLなし、μs | 31.4 | 108.9 |
| EML、μs | 27.6 | 73.5 |
次に、EMLが画像でどのように機能するかを確認し、転置を調べました。これは、画像処理でかなり一般的な操作であるためです。 さまざまなタイプの正方形画像の転置時間のサイズ依存性:
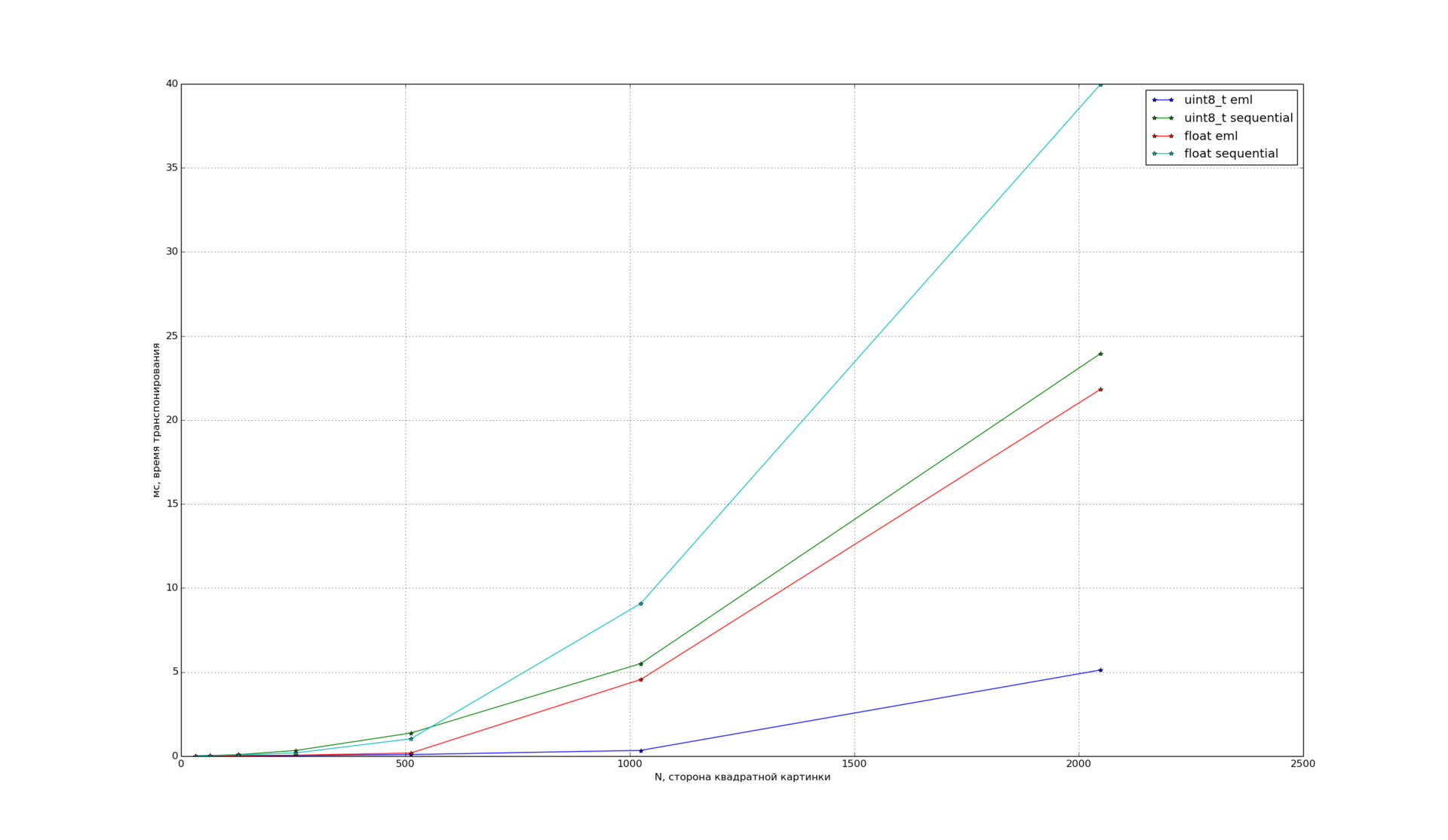
EMLがuint8_tおよびfloat型の優れた加速を示していることがわかります。
パスポート認識プログラム(テストイメージ、エニウェアモード)を高速化した結果を表3に示します。これらは、エルブルスとの共同作業の最初の3か月で得られたものであり、もちろん、システムの最適化に取り組む予定です。
表3. Elbrus 4.4のパスポート認識プログラムの最適化プロセス。
| バージョン | 労働時間、s |
|---|---|
| 1スレッド | 〜100 |
| 16スレッド、O3 | 6.2 |
| 16スレッド、O4 | 5.4 |
| 16ストリーム、O4、トランスポーズ(EML) | 5.0 |
| 16ストリーム、O4、転置、行列演算(EML) | 4.5 |
| 16ストリーム、O4、転置、行列演算、算術演算(EML) | 3.4 |
最適化されたバージョンの動作時間を推定するために、各モードの1000入力画像あたりの動作時間を分析しました。 表4に、エニウェアモードとモバイルモードでの1フレームの最小、最大、および平均認識時間を示します。
表4. Elbrus 4.4でのパスポート認識の営業時間。
| モード | 最小時間、s | 最大時間、s | 平均時間、s |
|---|---|---|---|
| どこでも | 0.9 | 8.5 | 2.2 |
| モバイル | 0.2 | 1.5 | 0.6 |
インテルやARMとパフォーマンスを比較しませんでした。これらのプロセッサー向けにライブラリを最適化するのに数年かかりました。わずか3か月の操作で今すぐ比較を行うのは正しくありません。
おわりに
この記事では、Elbrusのような珍しいアーキテクチャにプログラムを移植した経験を共有しようとしました。 「これは確かに私たちには起こりえないことです!」私たちはいくつかのタイプのプログラムエラーを議論して考えましたが、誰も愚かな間違いから安全ではありません。 Elbrusプラットフォームを使用することで、コード内の少なくとも2つの問題のある場所を見つけることができたため、メーカーの約束が満たされたと見なすことができます。
わずか数か月で、正しい認識作業を達成できるだけでなく、Elbrusのシステムを大幅に高速化することもできました。 Elbrus 4.4とx86のパスポート認識プログラムのパフォーマンスは桁違いに異なり、非常に良い結果です。 そして、私たちはそこで停止するつもりはありません。 それでも大幅に改善できると考えています。
これはすべて、エルブラスへの旅の最初のステップが非常に成功したとみなせることを意味します!
ハードウェアプラットフォームを提供してくれたMCST社とその従業員、およびアーキテクチャと最適化に関するアドバイスに感謝します。
使用したソース
[1] A.K. キム、I.N。 Bychkov et al。今日の建築ライン「エルブラス」:マイクロプロセッサ、コンピューターシステム、ソフトウェア//現代の情報技術とIT教育。 レポートの収集、p。 21–29。
[2] A.K. キム。 ロシアの汎用マイクロプロセッサと高性能コンピューティングシステム:結果と将来の展望。 無線電子機器シリーズEVTの質問、T。3、p。 2012年5月13日。
[3] A.K. キムとI.N. ビチコフ。 パソコン、サーバー、スーパーコンピューター向けのロシアのエルブルス技術。
[4] V.S. Volin et al。Elbrusファミリーのマイクロプロセッサとコンピューティングシステム。 学習ガイド。 ピーター、2013年。
[5] Eigen、線形代数用のC ++テンプレートライブラリ:行列、ベクトル、数値ソルバー、および関連アルゴリズム、 http://eigen.tuxfamily.org
[6] P.A. イシン、V.E。 Loginov、およびP.P. ヴァシリエフ。 Elbrusアーキテクチャ向けの高性能数学およびマルチメディアライブラリを使用したコンピューティングを高速化します。