この出版物の著者は、 ドミトリー・セルゲエフとジュリア・ペトロパブロフスカヤです。
最近、Forbesの支援を受けたマイクロソフトによるロシア初の仮想ハッカソンが終了しました。 私たちの2人のチームは、ワールドクラスからの指名で1位になりました。そこでは、会社の各クライアントが元クラブ会員の地位に移行する確率を予測する必要がありました。 この記事では、私たちの決定を共有し、その主な段階についてお話したいと思います。

データ準備
データセットはひどく汚染され、4つの個別のカテゴリに分類されていたため、ほとんどの時間はデータのクリーニング、復元、および結合に費やされました。
- 顧客契約
- 出席者
- 霜
- 顧客とクラブ間のコミュニケーション
テストおよびトレーニングデータセットは月ごとに分類されました。 トレインには、2015年12月の顧客情報と2016年3月のテストが含まれていました。各カテゴリについて、さらに処理するためにトレインとテストパーツを組み合わせました。
顧客契約
ターゲット変数は「顧客が彼の契約を延長したかどうか」であり、契約および顧客コードは17,631個であり、他のすべてのデータセットを結合するためのキーとして使用されたため、契約は最初に取り上げたデータセットでした。 変数内の少数の欠損値がmodによって復元されました。 次に、季節(冬、春...)、クラブと契約が締結された月と日、および変数「契約期間」、「凍結の残りの日数」、「アカウントのボーナスの残高」の機能を作成しました。 年齢グループ、クラブセグメントなど、さまざまなカテゴリ変数 そのまま。
出席者
最初に、変数を作成しました-フィットネスクラブへの1回限りの旅行の期間です。

特に勤勉なクライアントは、おそらく複雑な手順の通過のために、クラブでほぼ9時間過ごすことができることが判明しました。
また、データセットにはカテゴリ変数があり、そのグラデーションをより一般的なカテゴリにグループ化することにしました。 たとえば、「トレーナーカテゴリ」:
additional = [' ', ''] coach = [' ', " "] coach_vip = [" ", " "] other = ['']
同様に-「サービスの方向」:
sport = [" ", " ", "", " ", "Mind Body", " ", " ", "", " "] health_beauty = ["", " ", " ", ", ", "_SF", " ", " ", " ", " ", "", " _SF", "", "_SF", " ", "", " SPA", " ", "_SF", "SPA"]
最後に、1か月あたりのクラブへの訪問頻度と異なる季節(冬、春など)の合計訪問数の変数を追加し、契約下のデータセットに含まれるクライアントのコードに従ってデータをグループ化しました。 合計で、370万件のレコードのうち、約15,000件の観測が残っています。
霜
最初に、データセットに重複があることがわかりました。 少し調べてみると、クライアントの霜の履歴がテストスイートに転送されたため、同じ凍結操作の同じ契約番号がTrainとTestの両方に含まれていることがわかりました。 将来モデルの再トレーニングを避けるために、テストから繰り返し値を捨てました。
その年の間に、各クライアントはカードを数回フリーズすることができ、フリーズの一時的な構造を保持するために何らかの形で役立つように思われました。 これを行うために、1年の季節ごとに4つの変数を作成し、特定の季節に費やした凍結日数の合計を記録しました。 その結果、次のデータ構造が得られました。

コミュニケーションズ
生データには、相互作用の日付 、 ビュー、 ステータスの 3つの主要な列がありました。 「電話」 、 「会議」 、 「SMS」などのオプションは「ビュー」の下に隠れていましたが、「状態」は「保留」 、 「キャンセル」 、 「計画」の 3つのレベルで特徴付けられていました。 霜のように、最初にテストデータから重複を削除してクライアント履歴をクリアし、次に変数の作成に進みました。
ほとんどすべてのクライアントは、何らかの種類の数十の通信を行いました。 この情報を単一行に圧縮して、後で一意の契約コードを使用して結合するために、いくつかの新しい機能を作成しました。
まず、変数「相互作用のタイプ」を3つのダミーに分割しました。
- 個人的な会議
- 電話
- その他
次に、各クライアントについて、通信の合計および成功( 「保留」 )数を計算しました。 一方を他方に分割すると、変数「成功した通信のシェア」を受け取りました。
最新の発見は、「過去2か月間にコミュニケーションがあった」というダミー変数の作成でした。 契約を更新する場合は、現在の契約が終了したときに何らかの形でクラブに連絡することをお勧めします。
その結果、1,500,000行のうち、15,500行が受信され、最終データセットと結合されました。 カテゴリ変数をダミーに変換した後、列の数が72個に増えました。
機械学習
したがって、顧客のバイナリ分類、クラスはほぼ等しく表され、すべてが良好であり、学習することができます。 明らかなことに加えて、モデルの候補は次のとおりです。
- ランダムフォレスト
- ニューラルネットワーク
- SVM
- k-nn
- ナイーブベイズ
- ロジット回帰
- 決定印
一般に、各分類子は検証で非常に良い結果を示しました。 10倍のcvを持つ1000本の木のランダムフォレストは0.9499 AUCを生成し、2層ニューラルネットワークは結果を0.98に上げることができ、XGBのKaggleでの激しい雷雨は0.982の印象的なものでした。 Xgboostは、症状の重要性を視覚化するのにも役立ちました。

最初の3つは、 「 契約期間」 、 「ボーナスポイントのバランス」 、および「平均訪問期間」です。 また、トップ10には「成功した通信の数」 、 「凍結の残りの日数」 、そして突然「冬にフィットネスに参加しましたか」があります 。
決定的な大麻を除いて、残りのモデルはそれぞれ平均0.92〜0.94 AUCであり、アンサンブルに追加して、異なる予測間の相関を減らしました。
アンサンブルは、2つのレベルの形で考案されました-最初の100の決定切り株で、多数決の原則を使用して予測が結合されました。 51個の切り株が「対象」で、49個が「反対」の場合、ユニットは配置されました。 第二に、他の分類器の予測が後続の統合のために接続されました。
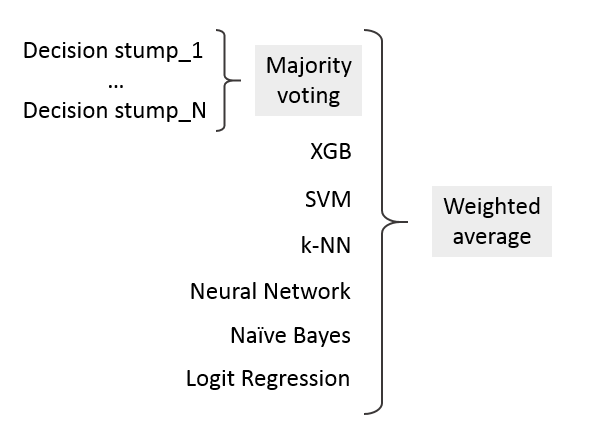
アンサンブルを作成するために、 加重平均の方法が使用され 、各分類器は個別にトレーニングされ、その後、予測から線形結合が作成されます。

aj-予測がアンサンブルに入る重み
yj(x)-個々の分類子予測
pは使用されるモデルの数です
重みは、重みベクトルx0の最適値を返す注目すべき最小化関数を使用して、アンサンブルの対数損失を最小化することにより決定されました。
from scipy.optimize import minimize opt = minimize(ensemble_logloss, x0=[1, 1, 1, 1, 1, 1, 1])
負の相関が与えられたモデルエラーの場合、これは必要ではないという興味深い意見がありますが、負の重みが与えられたモデルはアンサンブルから除外され、トレーニングデータへの適合を回避しました。
この選択の結果、ロジスティック回帰はなくなり、残念ながらすべてのヘンプが減少しましたが、AUCは1000分の2パーセント増加し、0.98486に達しました。 完全に価値があります。
最後に、テストデータセットで予測が行われ、少なくともその品質をある程度把握するために、2つのヒストグラムが作成されました。1つ目は、検証サンプルの契約を更新するクライアントのアンサンブル予測確率のテスト、2つ目はテストサンプルのヒストグラムです。

TrainとTestのサンプルが多かれ少なかれ同質であり、更新の数が拒否された数とほぼ等しいと仮定すると、契約延長の確率のモデルによる二重の過大評価があります。 しかし、私たちはアンサンブルの決定を信頼することを決め、不必要に彼を罰しませんでした ar慢 楽観的な予測。 そしてそれが判明したように-無駄ではありません。
結論として、ハッカソンのオーガナイザーに、非常に興味深い実用的なタスクと忘れられない経験に感謝します。
リポジトリへのリンク 。