問題の記述と初期データ
友人の推奨事項の高品質アルゴリズムの開発は、ほとんどすべてのソーシャルネットワークにとって最も優先度の高いものの1つです。 このような機能は、ユーザーを引き付けて維持するための強力なツールです。
英語の文献にはこの主題に関する多くの出版物があり、タスク自体にも特別な略語PYMK(People You May Know)があります。
Beelineは、 Microsoftの仮想ハッカソンのフレームワーク内で、企業のソーシャルネットワーク「Hive」のグラフを提供しました。 グラフのエッジの5%は人為的に隠されていました。 タスクは、元のグラフの隠れたエッジを見つけることでした。
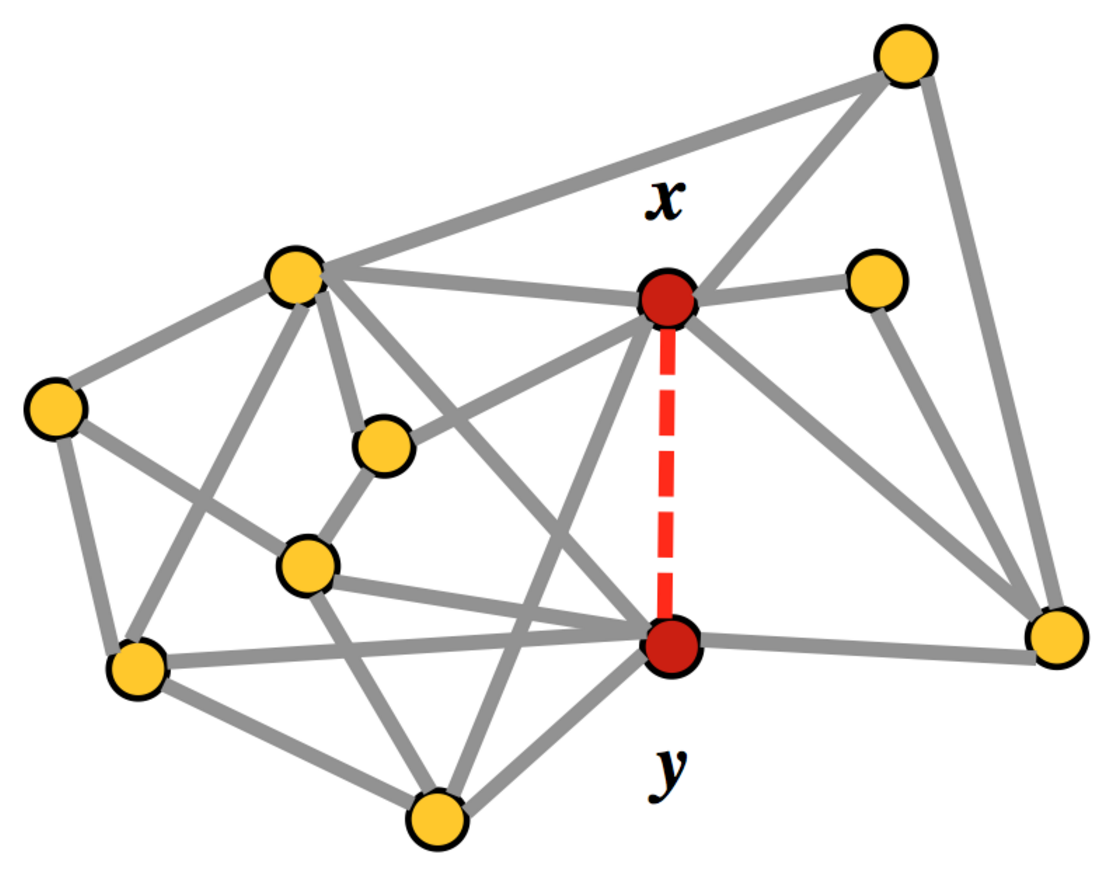
ソーシャルネットワークのユーザー間のコミュニケーションの存在に加えて、ユーザーが働いている会社、送受信されたメッセージの数、通話時間、送受信されたドキュメントの数に関する情報についても、各ペアに情報が提供されました。
エッジの検索問題はバイナリ分類問題として定式化され、メジャーF1が受け入れメトリックとして提案されました。 このようなタスクの一部では、品質メトリックがユーザーごとに個別に考慮され、平均が推定されます。 この問題では、品質はすべてのエッジに対してグローバルに評価されました。
トレーニングとテスト
一般的な場合、グラフ内の隠れたエッジを検索するには、可能なすべての頂点のペアをソートし、各ペアの接続の確率の推定値を取得する必要があります。
大きなグラフの場合、このアプローチでは多くのコンピューティングリソースが必要になります。 したがって、実際には、ソーシャルグラフの多くの候補は、少なくとも1人の共通の友人を持つペアにのみ制限されます。 原則として、このような制限により、品質を大幅に低下させることなく、計算量を大幅に削減し、アルゴリズムを高速化できます。
候補の各ペアは、特徴ベクトルとバイナリ回答によって記述されます。エッジがある場合は「1」、エッジがない場合は「0」です。 得られたセット{feature vector、answer}で、候補のペアのエッジの確率を予測するモデルがトレーニングされます。
なぜなら この問題のグラフは無指向性であるため、特徴ベクトルはペアの候補の順列に依存してはなりません。 このプロパティを使用すると、トレーニング中に数人の候補者を1回だけ考慮し、トレーニングサンプルのサイズを半分にすることができます。
最初のグラフにどのエッジが隠れているかという質問に答えるには、モデルの出力での確率推定を適切なしきい値を選択して、バイナリ回答に変換する必要があります。
モデルパラメーターの品質と選択を評価するために、提供されたグラフからランダムに選択されたエッジの5%を削除しました。 残りのグラフは、候補の検索、特徴の生成、トレーニングのモデル化に使用されました。 隠れたrib骨を使用して、しきい値と最終的な品質評価を選択しました。
PYMKタスクで機能を生成するための基本的なアプローチを以下に説明します。
カウンター
各ユーザーについて、統計、つまり地理、コミュニティ、年齢、性別による友人の分布を考慮します。 これらの統計によると、たとえばスカラー積を使用して、候補の相互の類似性の評価を取得します。
類似セットと一般的な友人
ジャカード係数-2つのセットの類似性を評価できます。 セットは友人であり、たとえば、候補者のコミュニティでもあります。
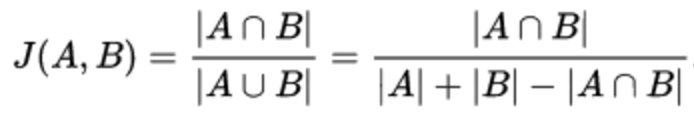
Adamik / Adarの比率は、基本的に2人の候補者の共通の友人の加重合計です。
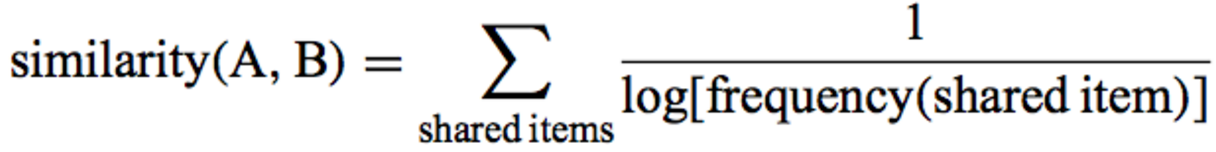
この量の重みは、共通の友人の友人の数に依存します。 共通の友人の友人が少ないほど、結果の金額に対する彼の貢献は大きくなります。 ところで、私たちはこのアイデアを積極的に使用して決定しました。
潜在因子
これらの符号は、行列展開の結果として取得されます。 さらに、分解は、ユーザー間の関係のマトリックスとコミュニティ(ユーザーマトリックス、または地理学)の両方に適用できます。 結果の潜在的な記号を持つベクトルの分解は、たとえば余弦距離測定を使用して、オブジェクトの相互の類似性を評価するために使用できます。
おそらく最も一般的な行列分解アルゴリズムはSVDです。 また、推奨システムで一般的なALSアルゴリズム、およびBigCLAMグラフでコミュニティを検索するためのアルゴリズムを使用することもできます。
グラフ上のサイン
この特性グループは、グラフの構造を考慮して計算されます。 原則として、計算中の時間を節約するために、グラフ全体ではなく、深さ2の共通の友人のサブグラフなど、グラフの一部が使用されます。
最も人気のある機能の1つはヒッティングタイムです。これは、rib骨の重みを考慮して、ある候補から別の候補へのルートを完了するために必要な平均ステップ数です。 パスは、現在のノードから発生するエッジの属性の値に応じた確率で、次の頂点がランダムに選択されるように配置されます。
解決策
この問題を解決する際に、Adamik / Adar係数で具体化されたアイデアを積極的に使用しました。これは、すべての友人が等しく役立つわけではないというものです。 私たちは割引関数を試しました-対数の代わりに小数度を試し、さまざまな効用属性に従って相互の友人を計量することも試しました。
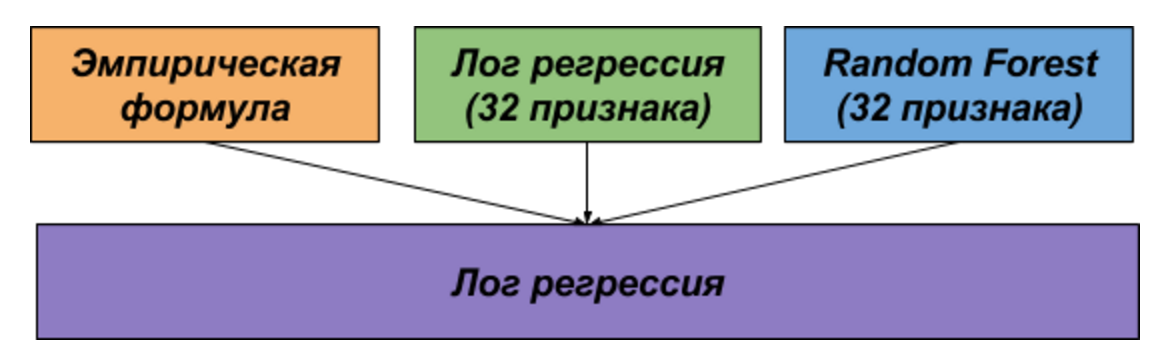
なぜなら 並行してタスクに取り組んだ後、2つの独立したソリューションを得て、それらを最終的な提出のために結合しました。
最初の解決策は、Adamik / Adarのアイデアに基づいており、共通の友人の友人の数と、共通の友人を介した候補者間のメッセージの流れの両方を考慮する経験式です。
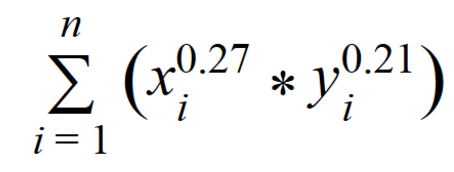
nは共通の友人の数です。
xiは、共通の友人の友人の数です。
yi-相互の友人を介した候補者間の着信メッセージと発信メッセージの合計
2番目のソリューションでは、32個の属性を生成し、それらのログモデルをトレーニングしました。 回帰およびランダムフォレスト。
1番目と2番目のソリューションのモデルは、別のロジスティック回帰を使用して結合されました。
この表では、2番目のソリューションで使用された主な機能について説明します。
| サイン | 説明 |
|---|---|
| | Adamik / Hadar係数の類似物ですが、対数の代わりに、3次の根が使用されました |
| | メッセージの伝導に基づいて、共通の友人の重さを量ります。 共通の友人の発信/着信メッセージ/通話/ドキュメントの比率が低いほど、合計時の重みが高くなります |
| flow_common | 相互の友人を通して候補者間のメッセージ/通話/文書の開通性を評価します。 クロスが高いほど、加算するときの重量が大きくなります |
| friends_jaccard | 候補者の友人のジャカード係数 |
| friend_company | 候補者の会社のユーザーの友人のシェアに基づく類似性 |
| company_jaccard | ジャカード係数を使用して、候補者の会社の親しみやすさを評価します(候補者が同じ会社のものである場合は1に等しい) |
以下の表は、個々のモデルと結果のモデルの両方の品質推定値を示しています
| モデル | F1 | 精度 | 完全性 |
|---|---|---|---|
| 経験式 | 0.064 | 0.059 | 0.069 |
| ログ回帰 | 0.060 | 0.057 | 0.065 |
| ランダムフォレスト | 0.065 | 0.070 | 0.062 |
| ログ回帰+ランダムフォレスト | 0.066 | 0.070 | 0.063 |
| 対数回帰+ランダムフォレスト+経験式 | 0.067 | 0.063 | 0.071 |
しきい値の選択
したがって、モデルはトレーニングされます。 次のステップは、受け入れメトリックを最適化するためのしきい値を選択することです。
この問題では、メトリックF1を最適化しました。
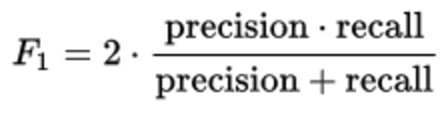
このメトリックは、精度と完全性の両方に等しく敏感であり、これらの値の調和平均を表します。
なぜなら メトリックF1のしきい値依存性は凸関数であるため、最大値の検索は難しくありません。
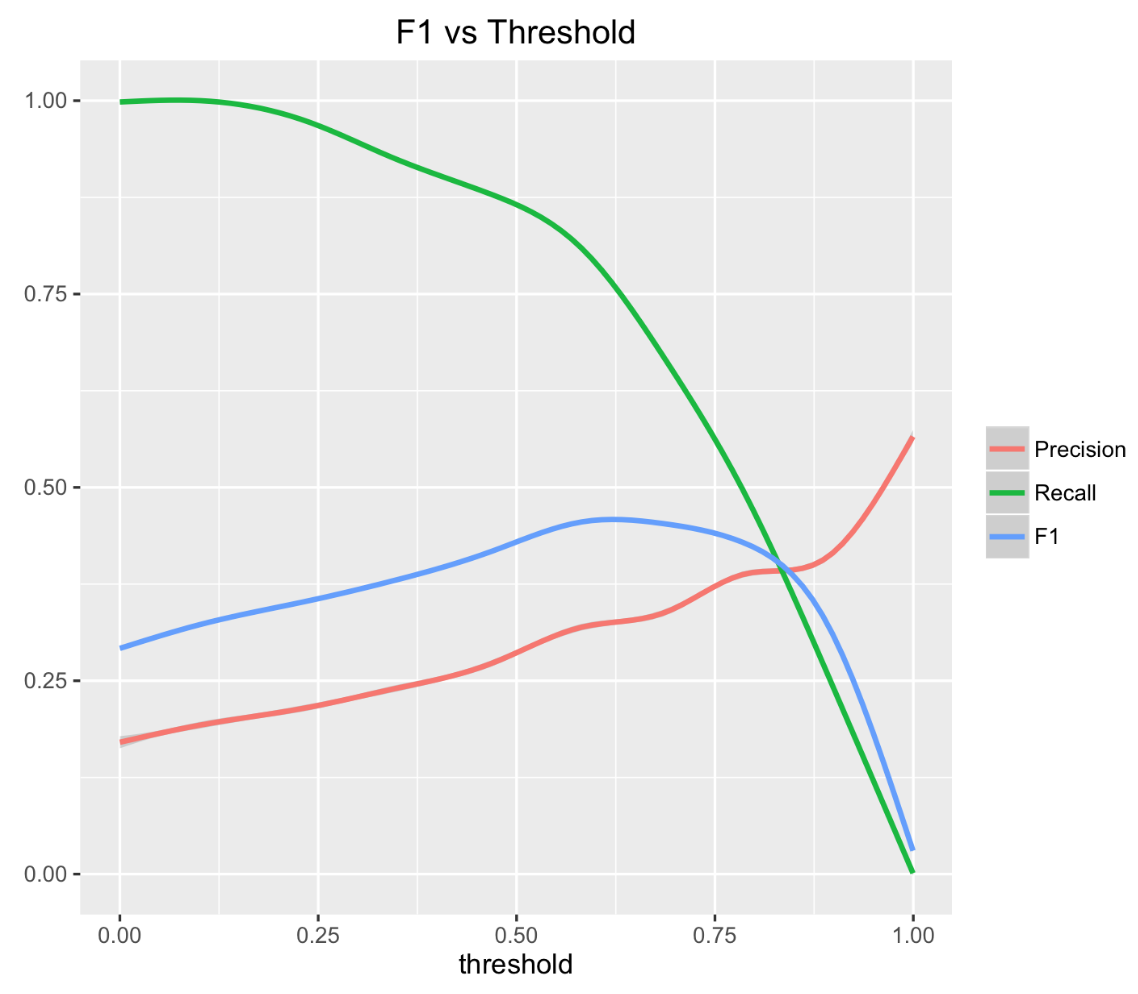
この問題では、最適なしきい値を選択するために、バイナリ検索アルゴリズムを使用しました。
技術
初期グラフは、ユーザー識別子と対応する属性を持つエッジのリストとして指定されました。 合計550万のリンクがトレーニングサンプルに提示されました。 ソースデータは、csv形式のテキストファイルの形式で提供され、ハードドライブで163 MBを占有します。
ハッカソンの一環として、 Microsoft BizSparkプログラムの下でAzureクラウドサービスのリソースが提供され、計算用の仮想マシンが作成されました。 1時間あたりのサーバー価格は0.2ドルで、計算の強度に依存しませんでした。 主催者が割り当てた予算は、この問題を解決するのに十分でした。
Sparkに共通のフレンド検索アルゴリズムを実装しました。中間計算の結果は寄木細工の形式でディスクにキャッシュされたため、データの読み取り時間を大幅に短縮できました。 仮想マシンで一般的な友人を検索するアルゴリズムは8時間でした。 寄木細工の形式で共通の友人のリストを持つ候補者は2.1GBを占有します。
モデルパラメータのトレーニングと選択のアルゴリズムは、 scikit-learnパッケージを使用してPythonで実装されます。 機能の生成、モデルのトレーニング、および仮想サーバーでのしきい値の選択のプロセスには、合計で約3時間かかりました。
結論として、問題を解決するために積極的に参加してくれたイヴァンブラギンと、経験式を選択する創造性に感謝します。