最近、strstr関数の類似物を書く必要がありました(ストリング内のサブストリングを検索します)。 スピードアップすることにしました。 結果はアルゴリズムです。 検索エンジンの最初のリンクでは見つけられませんでしたが、他のアルゴリズムがたくさんあるので、書きました。
1〜255バイトのサイズの文字列を検索するときに、ロシア語の本の600 kbテキストでstrstr関数を使用して、アルゴリズムの速度を比較するグラフ:

アルゴリズムの根底にある考え方は次のとおりです。 最初の表記:
S-検索が実行される行が呼び出されます
P-探している文字列が呼び出されます
sl-ストリングの長さS
pl-ストリングの長さP
PInd-最初の段階でコンパイルされたタブレット。
したがって、アイデアは次のとおりです。S行でインデックスがpl 1、pl 2、...、pl J、...、pl (sl / pl)の要素を選択すると、セグメントpl (J-1).. .pl (J + 1)には文字列Pが含まれているため、選択されたアイテムは文字列Pに属している必要があります。
Pが到達する場所に描画される図は、pl * 3にあります。
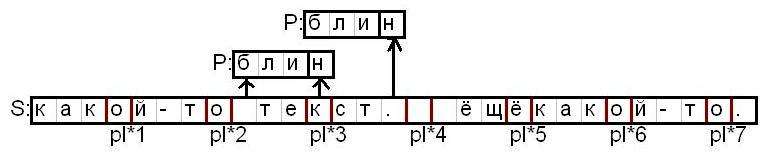
それでも、通常、選択された要素は文字列Pに少数回含まれているため、範囲全体ではなく、これらの出現のみをチェックできます。
合計アルゴリズムは次のとおりです。
手順1. Pを並べ替える
文字列Pのすべての要素(文字)について、これらの要素の値でこれらの要素のインデックスを並べ替えます。 つまり、ある値に等しいすべての要素のすべての数をすばやく取得できるようにします。 このラベルはPIndと呼ばれます:
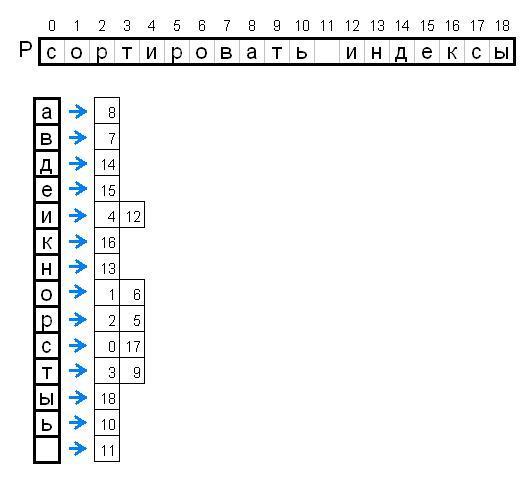
このプレートからわかるように、「ソートインデックス」に等しい目的の文字列Pをステップ2で検索する場合、Sの最大2つの部分文字列をチェックする必要があります。
最初にこのプレートをコンパイルするためにクイックソートなどを使用し、次に文字列の要素がシングルバイトであるため、ビット単位を使用できることに気付きました。
ステージ2.検索
plに等しいジャンプでラインSに沿って進み、対応する要素を選択します。 選択した各アイテムについて、ラインPにあるかどうかを確認します。
一致する場合、対応する要素のPIndからのすべてのインデックスについて、選択した要素と目的の文字列Pに関連するオフセットによって、部分文字列SがPIndからの対応するインデックスの先頭と一致するかどうかを確認します。
一致する場合は結果を返し、一致しない場合は続行します。
このアルゴリズムの最悪のオプションは、2番目のステップで文字列を比較する方法によって異なります。 単純な比較の場合は、sl * pl + pl、他の場合は、別の場合。 通常のstrstrのように、比較だけを使用しました。
アルゴリズムはpl要素をジャンプして、可能な行のみをチェックするという事実により、より高速に動作します。
最適なオプションは、アルゴリズムが文字列S全体をスキップし、テキストを見つけられないか、最初に見つけたときに、sl / plほど費やします。
計算方法がわからない平均速度。
以下に、このアルゴリズムの実装の1つを示します。これに従って、Cのグラフが作成されました。 ここで、plは制限されています。つまり、PIndテーブルは、行全体ではなく、長さmax_lenのプレフィックスPによって構築されます。 チャートの作成に使用されたのは彼でした:
char * my_strstr(const char * str1, const char * str2,size_t slen){ unsigned char max_len = 140; if ( !*str2 ) return((char *)str1); // unsigned char index_header_first[256]; unsigned char index_header_end[256]; unsigned char last_char[256]; unsigned char sorted_index[256]; memset(index_header_first,0x00,sizeof(unsigned char)*256); memset(index_header_end,0x00,sizeof(unsigned char)*256); memset(last_char,0x00,sizeof(unsigned char)*256); memset(sorted_index,0x00,sizeof(unsigned char)*256); // 1. char *cp2 = (char*)str2; unsigned char v; unsigned int len =0; unsigned char current_ind = 1; while((v=*cp2) && (len<max_len)){ if(index_header_first[v] == 0){ index_header_first[v] = current_ind; index_header_end[v] = current_ind; sorted_index[current_ind] = len; } else{ unsigned char last_ind = index_header_end[v]; last_char[current_ind] = last_ind; index_header_end[v] = current_ind; sorted_index[current_ind] = len; } current_ind++; len++; cp2++; } if(len > slen){ return NULL; } // 2. unsigned char *s1, *s2; // S+pl-1 unsigned char *cp = (unsigned char *) str1+(len-1); unsigned char *cp_end= cp+slen; while (cp<cp_end){ unsigned char ind = *cp; // P if( (ind = index_header_end[ind]) ) { do{ // unsigned char pos_in_len = sorted_index[ind]; s1 = cp - pos_in_len; if((char*)s1>=str1) { // s2 = (unsigned char*)str2; while ( *s2 && !(*s1^*s2) ) s1++, s2++; if (!*s2) return (char*)(cp-pos_in_len); } } while( (ind = last_char[ind]) ); } // pl cp+=len; } return(NULL); }
更新:これは実際にはstrstrの直接の置き換えではありません。パラメータ-文字列Sの長さを追加で必要とするためです。