
制限事項
一般に、OpenGL ES 2.0の2つの追加プロパティが必要になります(仕様ではそれらの可用性は必要ありません)。
- 頂点テクスチャフェッチ 。 頂点シェーダーのテクスチャユニットを介してテクスチャマップにアクセスできます。 パラメーター名GL_MAX_VERTEX_TEXTURE_IMAGE_UNITSのglGetIntegerv関数を使用して、GPUでサポートされるユニットの最大数を要求できます。 以下の表は、現在最も人気のあるプロセッサーに関するデータを示しています。
- 高い浮動小数点精度のフラグメント 。 フラグメントシェーダーで高精度の計算を実行できます。 glGetShaderPrecisionFormat関数を使用して、シェーダータイプとデータタイプにそれぞれGL_FRAGMENT_SHADERとGL_HIGH_FLOATのパラメーター名を付けて、精度と値の範囲を要求できます。 表にリストされているすべてのプロセッサーの精度は23ビットで、値の範囲は-2 ^ 127から2 ^ 127です。ただし、 Snapdragon Andreno 2xxを除き、このシリーズの範囲は-2 ^ 62から2 ^ 62です。
プロセッサー情報:
| CPU | 頂点TIU | 精度 | 範囲 |
|---|---|---|---|
| Snapdragon Adreno 2xx | 4 | 23 | [-2 ^ 62、2 ^ 62] |
| Snapdragon Adreno 3xx | 16 | 23 | [-2 ^ 127、2 ^ 127] |
| キンギョソウアドレノ4xx | 16 | 23 | [-2 ^ 127、2 ^ 127] |
| キンギョソウアドレノ5xx | 16 | 23 | [-2 ^ 127、2 ^ 127] |
| Intel HDグラフィックス | 16 | 23 | [-2 ^ 127、2 ^ 127] |
| ARM Mali-T6xx | 16 | 23 | [-2 ^ 127、2 ^ 127] |
| ARM Mali-T7xx | 16 | 23 | [-2 ^ 127、2 ^ 127] |
| ARM Mali-T8xx | 16 | 23 | [-2 ^ 127、2 ^ 127] |
| NVIDIA Tegra 2/3/4 | 0 | 0 | 0 |
| NVIDIA Tegra K1 / X1 | 32 | 23 | [-2 ^ 127、2 ^ 127] |
| PowerVR SGX(シリーズ5) | 8 | 23 | [-2 ^ 127、2 ^ 127] |
| PowerVR SGX(Series5XT) | 8 | 23 | [-2 ^ 127、2 ^ 127] |
| PowerVR Rogue(シリーズ6) | 16 | 23 | [-2 ^ 127、2 ^ 127] |
| PowerVR Rogue(Series6XT) | 16 | 23 | [-2 ^ 127、2 ^ 127] |
| VideoCore IV | 8 | 23 | [-2 ^ 127、2 ^ 127] |
| Vivante GC1000 | 4 | 23 | [-2 ^ 127、2 ^ 127] |
| Vivante GC4000 | 16 | 23 | [-2 ^ 127、2 ^ 127] |
NVIDIA Tegra 2/3/4には問題があります。Nexus7 、HTC One X、ASUS Transformerなどの多くの人気デバイスがこのシリーズで動作します。
パーティクルシステム
処理されるデータの量(パーティクルの数)を増やすコンテキストでCPUによって生成されるパーティクルシステムを考慮すると、主なパフォーマンスの問題は、各フレームでメインメモリからビデオデバイスメモリにデータをコピー(アンロード)することです。 したがって、主なタスクは、非動作モードで計算をGPUに転送することにより、このコピーを回避することです。
OpenGL ES 2.0には、GPUで計算を実行できるTransform Feedback (OpenGL ES 3.0で利用可能)やCompute Shader (OpenGL ES 3.1で利用可能)などの組み込みメカニズムがありません。
このメソッドの本質は、値(座標、加速度など)を使用することです。 テクスチャは、粒子を特徴付けるデータストレージバッファーとして使用し、頂点シェーダーとフラグメントシェーダーを使用して処理します。 法線を保存およびロードするように、法線マッピングについて話します。 この場合、バッファのサイズは、処理されるパーティクルの数に比例します。 各テクセルには、単一のパーティクルの個別の値(複数ある場合は値)が格納されます。 したがって、処理された数量の数は、粒子の数に反比例します。 たとえば、1048576パーティクルの位置と加速を処理するには、2つの1024x1024テクスチャが必要です(アスペクト比を維持する必要がない場合)
考慮すべき追加の制限があります。 情報を記録できるようにするには、テクスチャピクセルデータ形式がカラーレンダリング可能な形式として実装でサポートされている必要があります 。 これは、オフスクリーンレンダリングの一部としてカラーバッファとしてテクスチャを使用できることを意味します 。 この仕様では、GL_RGBA4、GL_RGB5_A1、GL_RGB565の 3つの形式のみを説明しています。 サブジェクト領域を考えると、座標や加速度(2次元の場合)などの値を処理するには、ピクセルあたり少なくとも32ビットが必要です。 したがって、上記の形式では不十分です。
必要な最小値を確保するために、 GL_RGBA8とGL_RGBA16Fの 2つの追加のテクスチャタイプを検討します。 このようなテクスチャは、多くの場合、それぞれLDR(SDR)およびHDRテクスチャと呼ばれます。
- GL_RGBA8は仕様でサポートされており、この形式でテクスチャを読み込んで読み取ることができます。 記録するには、 OES_rgb8_rgba8拡張機能が必要です。
- GL_RGBA16Fは仕様でサポートされていません。この形式のテクスチャを読み込んで読み取るには、 GL_OES_texture_half_float拡張が必要です。 さらに、品質で許容できる結果を得るために、このようなテクスチャの線形縮小および拡大フィルターのサポートが必要です。 GL_OES_texture_half_float_linear拡張がこれを担当します 。 レコードについては、拡張子GL_EXT_color_buffer_half_floatが必要です 。
2013〜 2015年のGPUINFOによると、拡張機能のサポートは次のとおりです。
| 延長 | デバイス(%) |
|---|---|
| OES_rgb8_rgba8 | 98.69% |
| GL_OES_texture_half_float | 61.5% |
| GL_OES_texture_half_float_linear | 43.86% |
| GL_EXT_color_buffer_half_float | 32.78% |
一般的に、HDRテクスチャは私たちの目的により適しています。 まず、パフォーマンスを犠牲にすることなく、より多くの情報を処理できます。たとえば、バッファーの数を増やすことなく、3次元空間で粒子を操作できます。 第二に、それぞれ読み取り時と書き込み時にデータをアンパックおよびパックするための中間メカニズムは必要ありません。 ただし、HDRテクスチャのサポートが不十分なため、LDRを選択します。
そのため、ポイントに戻ると、私たちが行うことの一般的なスキームは次のようになります。
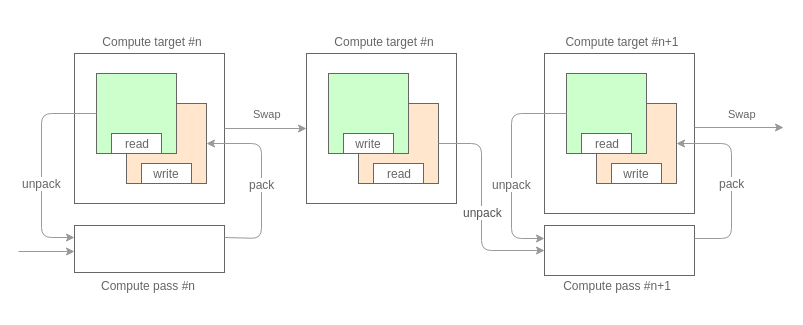
最初に必要なことは、計算をパスに分割することです。 パーティショニングは、処理する特性量の量とタイプに依存します。 データバッファとしてテクスチャを使用し、上記のピクセルデータの形式の制限を考慮すると、各パスは各パーティクルに対して32ビット以下の情報を処理できます。 たとえば、最初のパスでは加速度(32ビット、コンポーネントごとに16ビット)を計算し、2番目のパスでは位置(32ビット、コンポーネントごとに16ビット)を更新しました。
各パスは、ダブルバッファリングモードでデータを処理します。 これにより、前のフレームのシステム状態にアクセスできます。
パッセージの中心は、2つの三角形への通常のテクスチャマッピングです。ここでは、データバッファがテクスチャマップとして機能します。 シェーダーの一般的なビューは次のとおりです。
// attribute vec2 a_vertex_xy; attribute vec2 a_vertex_uv; varying vec2 v_uv; void main() { gl_Position = vec4(a_vertex_xy, 0.0, 1.0); v_uv = a_vertex_uv; }
// precision highp float; varying vec2 v_uv; // // ( ) uniform sampler2D u_prev_state; // // ( ) uniform sampler2D u_pass_0; ... uniform sampler2D u_pass_n; // <type> unpack(vec4 raw); <type_0> unpack_0(vec4 raw); ... <type_n> unpack_1(vec4 raw) // vec4 pack(<type> data); void main() { // // v_uv <type> data = unpack(texture2D(u_prev_state, v_uv)); <type_0> data_pass_0 = unpack_0(texture2D(u_pass_0, v_uv)); ... <type_n> data_pass_n = unpack_n(texture2D(u_pass_n, v_uv)); // <type> result = ... // gl_FragColor = pack(result); }
アンパック/パッキング関数の実装は、処理する値に依存します。 この段階では、計算の高精度に関する冒頭で説明した要件に依存しています。
たとえば、2次元座標(16ビットのコンポーネント[x、y])の場合、関数は次のようになります。
vec4 pack(vec2 value) { vec2 shift = vec2(255.0, 1.0); vec2 mask = vec2(0.0, 1.0 / 255.0); vec4 result = fract(value.xxyy * shift.xyxy); return result - result.xxzz * mask.xyxy; } vec2 unpack(vec4 value) { vec2 shift = vec2(1.0 / 255.0, 1.0); return vec2(dot(value.xy, shift), dot(value.zw, shift)); }
描画
計算段階の後、レンダリング段階が続きます。 この段階でパーティクルにアクセスするには、列挙のために外部インデックスが必要です。 データバッファーのテクスチャ座標を持つ頂点バッファー( Vertex Buffer Object )は、このようなインデックスとして機能します。 インデックスは一度作成および初期化(ビデオデバイスメモリにアップロード)され、プロセスで変更されません。
このステップで、テクスチャマップへのアクセスの要件が有効になります。 頂点シェーダーは、計算段階のフラグメントシェーダーに似ています。
// // attribute vec2 a_data_uv; // , uniform sampler2D u_positions; // ( ) uniform sampler2D u_data_0; ... uniform sampler2D u_data_n; // vec2 unpack(vec4 data); // <type_0> unpack_0(vec4 data); ... <type_n> unpack_n(vec4 data); void main() { // vec2 position = unpack(texture2D(u_positions, a_data_uv)); gl_Position = vec4(position * 2.0 - 1.0, 0.0, 1.0); // <type_0> data_0 = unpack(texture2D(u_data_0, a_data_uv)); ... <type_n> data_n = unpack(texture2D(u_data_n, a_data_uv)); }
例
小さな例として、 ストレンジアトラクターとして知られる1,048,576粒子の動的システムを生成しようとします。

フレーム処理はいくつかの段階で構成されています:

計算ステージ
計算の段階では、粒子の配置を担当する独立した通路は1つだけになります。 それは簡単な式に基づいています:
Xn+1 = sin(a * Yn) - cos(b * Xn) Yn+1 = sin(c * Xn) - cos(d * Yn)
このようなシステムは、 Peter de Jong Attractorsとも呼ばれます。 時間が経つにつれて、係数のみが変更されます。
// attribute vec2 a_vertex_xy; varying vec2 v_uv; void main() { gl_Position = vec4(a_vertex_xy, 0.0, 1.0); v_uv = a_vertex_xy * 0.5 + 0.5; }
// precision highp float; varying vec2 v_uv; uniform lowp float u_attractor_a; uniform lowp float u_attractor_b; uniform lowp float u_attractor_c; uniform lowp float u_attractor_d; vec4 pack(vec2 value) { vec2 shift = vec2(255.0, 1.0); vec2 mask = vec2(0.0, 1.0 / 255.0); vec4 result = fract(value.xxyy * shift.xyxy); return result - result.xxzz * mask.xyxy; } void main() { vec2 pos = v_uv * 4.0 - 2.0; for(int i = 0; i < 3; ++i) { pos = vec2(sin(u_attractor_a * pos.y) - cos(u_attractor_b * pos.x), sin(u_attractor_c * pos.x) - cos(u_attractor_d * pos.y)); } pos = clamp(pos, vec2(-2.0), vec2(2.0)); gl_FragColor = pack(pos * 0.25 + 0.5); }
レンダラーステージ
シーンのレンダリング段階では、通常のスプライトでパーティクルをレンダリングします。
// // attribute vec2 a_positions_uv; // (, ) uniform sampler2D u_positions; varying vec4 v_color; vec2 unpack(vec4 value) { vec2 shift = vec2(0.00392156863, 1.0); return vec2(dot(value.xy, shift), dot(value.zw, shift)); } void main() { vec2 position = unpack(texture2D(u_positions, a_positions_uv)); gl_Position = vec4(position * 2.0 - 1.0, 0.0, 1.0); v_color = vec4(0.8); }
// precision lowp float; varying vec4 v_color; void main() { gl_FragColor = v_color; }
結果 
後処理
結論として、 後処理段階で、いくつかの効果を課します
勾配マッピング 。 元の画像の明るさに基づいてカラーコンテンツを追加します。
結果 
ブルーム 。 少し輝きを追加します。
結果 
コード
GitHubのプロジェクトリポジトリ。
現在利用可能:
- メインコードベース(C ++ 11 / C ++ 14)とシェーダー。
- アプリケーションの例とデモ。
- 液体 流体シミュレーション;
- 散乱光。 散乱光の影響の適応;
- 奇妙なアトラクタ。 記事に記載されている例。
- 風のフィールド。 多数の粒子(2 ^ 20)を含むNavier-Stokesの実装。
- 炎のシミュレーション。 火炎シミュレーション。
- Android用クライアント。
継続
この例では、計算の段階、シーンのレンダリングの段階、および後処理が、相互に依存するいくつかのパスで構成されていることがわかります。
次のパートでは、各段階で課される要件を考慮して、マルチパスレンダリングの実装を検討します。
私はコメントや提案に喜んでいるでしょう(yegorov.alex@gmail.comで可能です)
よろしくお願いします!