
私は最初の出版物の著者の資格のレベルを知らないと言わなければなりません。 著者がスケーリングに重点を置いて並列プログラミングを教えることができる教育機関を最近卒業したという事実から話を進めます。 実際には、システムのコンピューティングリソース(スレッド)の数が限られていることがよくあるので、スケーリングだけでなく効率についても覚えておく必要があります。 フォーラムに投稿された元のコードサンプルには、効率(より大きな範囲)とスケーリング(より小さな範囲)の問題を解決する方法を理解するのに役立つ基本情報が含まれています。
この記事のコードを準備する際、サンプルコードを自由に変更して、その一般的な構造とレイアウトを維持しました。 サンプルコードは、説明されているアルゴリズムに加えて他の機能を持つアプリケーションから取得されたため、メインアルゴリズムは変更しませんでした。 提供されたコードサンプルでは、LOGICAL配列(マスク)を使用してフローを制御しました。 サンプルコードは論理配列なしで記述できますが、このコードは、サンプルコードではそれほど明らかではない何らかの理由でこれらのマスク配列が必要になる可能性のある、より大きなアプリケーションのフラグメントである可能性があります。 だから私はマスクを所定の場所に残しました。
コードと並列化の最初の試みを研究した結果、並列領域(並列DO)を作成するために間違った場所が選択されたと判断しました。 ソースコードは次のようになります。
bid = 1 ! { not stated in original posting, but would appeared to be in a DO bid=1,65 } do k=1,km-1 ! km = 60 do kk=1,2 !$OMP PARALLEL PRIVATE(I) DEFAULT(SHARED) !$omp do do j=1,ny_block ! ny_block = 100 do i=1,nx_block ! nx_block = 81 ... {code} enddo enddo !$omp end do !$OMP END PARALLEL enddo enddo
並列化の最初の試みで、ユーザーはそれをdo j =ループに適用しました。 これはサイクルの最も激しいレベルですが、このプラットフォームでこの問題を解決するには、異なるレベルで作業する必要があります。
この場合、16個のスレッドが使用されました。 2つの内部ループは一緒に8,100回の反復を実行し、スレッドごとに約506回の反復を行います(16個のスレッドがある場合)。 それでも、並列領域へのエントリは120回(60 * 2)実行されます。 最も内側のサイクルで行われた作業は重要ではありませんでしたが、リソースが必要でした。 このため、並列領域はアプリケーションのかなりの部分をカバーしています。 16個のスレッドと60個の外部ループカウンターの繰り返し(ループ使用時は120個)を使用すると、 do kループに並列領域を作成する方が効率的です。
do kループを何度も実行し、 do kループ全体の平均実行時間を計算するようにコードが修正されました。 最適化手法を適用する場合、ソースコードの平均実行時間と処理されたコードの差を使用して、達成された改善を測定できます。 テスト用の8コアE5-2650 v2プロセッサーはありませんが、6コアE5-2620 v2プロセッサーが見つかりました。 わずかに修正されたコードにより、次の結果が生成されました。
OriginalSerialCode Average time 0.8267E-02 Version1_ParallelAtInnerTwoLoops Average time 0.1746E-02, x Serial 4.74
6コアのE5-2620 v2プロセッサーでは、パフォーマンスの向上は6倍から12倍の範囲になります(ハイパースレッディングの追加の15%を考慮すると、速度は7倍になります)。 生産性を4.74倍に向上します。 予想より大幅に少ない:7倍の加速を期待しました。
この記事の以降のセクションでは、他の最適化手法について説明します。
OriginalSerialCode Average time 0.8395E-02 ParallelAtInnerTwoLoops Average time 0.1699E-02, x Serial 4.94 ParallelAtkmLoop Average time 0.6905E-03, x Serial 12.16, x Prior 2.46 ParallelAtkmLoopDynamic Average time 0.5509E-03, x Serial 15.24, x Prior 1.25 ParallelNestedRank1 Average time 0.3630E-03, x Serial 23.13, x Prior 1.52
ParallelAtInnerTwoLoopsレポートは、2回目の実行では乗数が最初の実行の乗数と異なることを示していることに注意してください。 この動作の理由は、コードの配置の成功(または失敗)です。 コード自体は変更されておらず、両方の実行で完全に同一です。 唯一の違いは、追加コードの追加とこれらのルーチンへの呼び出しステートメントの挿入です。 タイトなループを配置すると、これらのループのパフォーマンスに大きく影響する可能性があることに注意してください。 場合によっては、単一のステートメントを追加しても、コードのパフォーマンスが大幅に変化する可能性があります。
コードの変更を読みやすくするために、3つの内部ループのテキストはサブルーチンで囲まれています。 このため、VTuneプロファイラーを使用してコードを調べて診断を実行するのが簡単になります。 ParallelAtkmLoopルーチンの例:
bid = 1 !$OMP PARALLEL DEFAULT(SHARED) !$omp do do k=1,km-1 ! km = 60 call ParallelAtkmLoop_sub(bid, k) end do !$omp end do !$OMP END PARALLEL endtime = omp_get_wtime() ... subroutine ParallelAtkmLoop_sub(bid, k) ... do kk=1,2 do j=1,ny_block ! ny_block = 100 do i=1,nx_block ! nx_block = 81 ... enddo enddo enddo end subroutine ParallelAtkmLoop_sub
最適化の最初の段階には2つの変更が含まれます。
- 並列化により、2レベルのループがループレベルdo kに移動します。 このため、並列領域のエントリ数は120倍減少しました。
- アプリケーションは、LOGICAL配列をマスクとして使用してコードを選択しました。 マスク配列を使用した不要な操作をなくすために、値の形成に使用されるコードを再編集しました。
これら2つの変更の結果、生産性は最初の並列化試行と比較して2.46倍に増加しました。 これは良い結果ですが、そこで停止する価値はありますか?
最も内側のループでは、次のことがわかります。
... {construct masks} if ( LMASK1(i,j) ) then ... {code} endif if ( LMASK2(i,j) ) then ... {code} endif if( LMASK3(i,j) ) then ... {code} endif
各反復には異なる量の作業があることがわかります。 この場合、動的計画を使用することをお勧めします。 次の最適化ステップはParallelAtkmLoopDynamicに適用されます。 これはParallelAtkmLoopと同じコードですが、 !$ Omp doにスケジュール(動的)が追加されています 。
この単純な変更だけで、速度が1.25倍になりました。 可能な計画方法は動的計画だけではないことに注意してください。 探索する価値のある他のタイプがあります。 また、このタイプの計画では、修飾子(フラグメントサイズ)が追加されることが多いことを忘れないでください。
さらに1.52倍の加速を提供する次のレベルの最適化は、積極的な最適化と呼ばれます。 この速度の52%の追加の増加を達成するには、具体的なプログラミングの努力が必要です(ただし、非常に複雑なものはありません)。 この最適化の可能性は、VTuneでアセンブラーコードを分析することで決定されます。
それを分析するためにアセンブラコードを理解する必要がないことを強調する必要があります。 原則として、次の手順を実行できます。
アセンブリコードが多いほど、パフォーマンスは低下します。
アセンブラコードがより複雑(膨大)になるほど、コンパイラは最適化の可能性を逃す可能性が高くなります。 逃した機会を発見した場合、コンパイラーがコードを最適化するのに役立つ簡単な手法を使用できます。
メインアルゴリズムのコードを見るとわかります。
コード
subroutine ParallelAtkmLoopDynamic_sub(bid, k) use omp_lib use mod_globals implicit none !----------------------------------------------------------------------- ! ! dummy variables ! !----------------------------------------------------------------------- integer :: bid,k !----------------------------------------------------------------------- ! ! local variables ! !----------------------------------------------------------------------- real , dimension(nx_block,ny_block,2) :: & WORK1, WORK2, WORK3, WORK4 ! work arrays real , dimension(nx_block,ny_block) :: & WORK2_NEXT, WORK4_NEXT ! WORK2 or WORK4 at next level logical , dimension(nx_block,ny_block) :: & LMASK1, LMASK2, LMASK3 ! flags integer :: kk, j, i ! loop indices !----------------------------------------------------------------------- ! ! code ! !----------------------------------------------------------------------- do kk=1,2 do j=1,ny_block do i=1,nx_block if(TLT%K_LEVEL(i,j,bid) == k) then if(TLT%K_LEVEL(i,j,bid) < KMT(i,j,bid)) then LMASK1(i,j) = TLT%ZTW(i,j,bid) == 1 LMASK2(i,j) = TLT%ZTW(i,j,bid) == 2 if(LMASK2(i,j)) then LMASK3(i,j) = TLT%K_LEVEL(i,j,bid) + 1 < KMT(i,j,bid) else LMASK3(i,j) = .false. endif else LMASK1(i,j) = .false. LMASK2(i,j) = .false. LMASK3(i,j) = .false. endif else LMASK1(i,j) = .false. LMASK2(i,j) = .false. LMASK3(i,j) = .false. endif if ( LMASK1(i,j) ) then WORK1(i,j,kk) = KAPPA_THIC(i,j,kbt,k,bid) & * SLX(i,j,kk,kbt,k,bid) * dz(k) WORK2(i,j,kk) = c2 * dzwr(k) * ( WORK1(i,j,kk) & - KAPPA_THIC(i,j,ktp,k+1,bid) * SLX(i,j,kk,ktp,k+1,bid) & * dz(k+1) ) WORK2_NEXT(i,j) = c2 * ( & KAPPA_THIC(i,j,ktp,k+1,bid) * SLX(i,j,kk,ktp,k+1,bid) - & KAPPA_THIC(i,j,kbt,k+1,bid) * SLX(i,j,kk,kbt,k+1,bid) ) WORK3(i,j,kk) = KAPPA_THIC(i,j,kbt,k,bid) & * SLY(i,j,kk,kbt,k,bid) * dz(k) WORK4(i,j,kk) = c2 * dzwr(k) * ( WORK3(i,j,kk) & - KAPPA_THIC(i,j,ktp,k+1,bid) * SLY(i,j,kk,ktp,k+1,bid) & * dz(k+1) ) WORK4_NEXT(i,j) = c2 * ( & KAPPA_THIC(i,j,ktp,k+1,bid) * SLY(i,j,kk,ktp,k+1,bid) - & KAPPA_THIC(i,j,kbt,k+1,bid) * SLY(i,j,kk,kbt,k+1,bid) ) if( abs( WORK2_NEXT(i,j) ) < abs( WORK2(i,j,kk) ) ) then WORK2(i,j,kk) = WORK2_NEXT(i,j) endif if ( abs( WORK4_NEXT(i,j) ) < abs( WORK4(i,j,kk ) ) ) then WORK4(i,j,kk) = WORK4_NEXT(i,j) endif endif if ( LMASK2(i,j) ) then WORK1(i,j,kk) = KAPPA_THIC(i,j,ktp,k+1,bid) & * SLX(i,j,kk,ktp,k+1,bid) WORK2(i,j,kk) = c2 * ( WORK1(i,j,kk) & - ( KAPPA_THIC(i,j,kbt,k+1,bid) & * SLX(i,j,kk,kbt,k+1,bid) ) ) WORK1(i,j,kk) = WORK1(i,j,kk) * dz(k+1) WORK3(i,j,kk) = KAPPA_THIC(i,j,ktp,k+1,bid) & * SLY(i,j,kk,ktp,k+1,bid) WORK4(i,j,kk) = c2 * ( WORK3(i,j,kk) & - ( KAPPA_THIC(i,j,kbt,k+1,bid) & * SLY(i,j,kk,kbt,k+1,bid) ) ) WORK3(i,j,kk) = WORK3(i,j,kk) * dz(k+1) endif if( LMASK3(i,j) ) then if (k.lt.km-1) then ! added to avoid out of bounds access WORK2_NEXT(i,j) = c2 * dzwr(k+1) * ( & KAPPA_THIC(i,j,kbt,k+1,bid) * SLX(i,j,kk,kbt,k+1,bid) * dz(k+1) - & KAPPA_THIC(i,j,ktp,k+2,bid) * SLX(i,j,kk,ktp,k+2,bid) * dz(k+2)) WORK4_NEXT(i,j) = c2 * dzwr(k+1) * ( & KAPPA_THIC(i,j,kbt,k+1,bid) * SLY(i,j,kk,kbt,k+1,bid) * dz(k+1) - & KAPPA_THIC(i,j,ktp,k+2,bid) * SLY(i,j,kk,ktp,k+2,bid) * dz(k+2)) end if if( abs( WORK2_NEXT(i,j) ) < abs( WORK2(i,j,kk) ) ) & WORK2(i,j,kk) = WORK2_NEXT(i,j) if( abs(WORK4_NEXT(i,j)) < abs(WORK4(i,j,kk)) ) & WORK4(i,j,kk) = WORK4_NEXT(i,j) endif enddo enddo enddo end subroutine Version2_ParallelAtkmLoop_sub
Intel Amplifier(VTune)を実行し、ライン540を例として考えます。

これは、2つの数値を乗算する命令の一部です。 この部分的な情報については、次のことが期待できます。
- SLXインデックスで値をロードします。
- インデックスdzの値による乗算。
AmplifierのAssemblyボタンをクリックした場合。
次に、コード行番号で並べ替えます。
コード540の行には、次のものがあります。
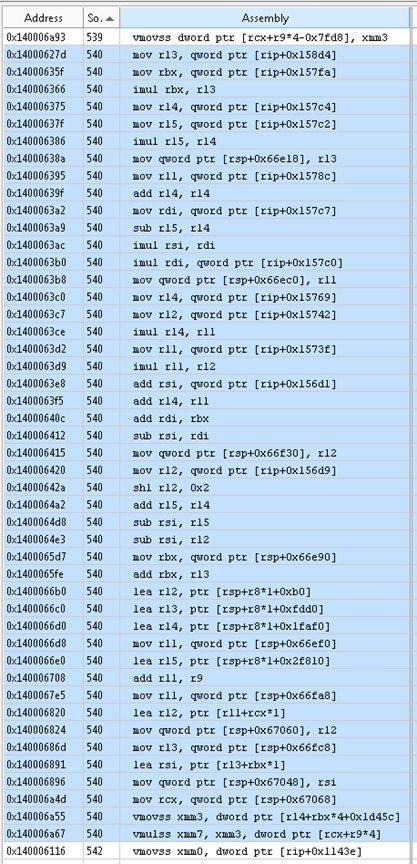
合計46個のアセンブラー命令を使用して、2つの数値を乗算します。
それでは、相互影響に移りましょう。
これらの2つの数値は、2つの配列のセルです。 SLXアレイには6つのサブスクリプションがあり、他のアレイには1つのサブスクリプションがあります。 最後の2つのアセンブラー命令は、メモリーからのvmovssとメモリーからのvmulssです。 期待に応える完全に最適化されたコードを取得したいと考えました。 上記のコードでは、46個のアセンブラー関数のうち44個が、これら2つの変数の配列インデックスの計算に関連しています。 当然、配列内のインデックスを取得するにはいくつかの命令が必要な場合がありますが、44は明らかに多すぎます。 複雑さを軽減する方法はありますか?
ソースコード(上記の最新バージョン)を見ると、最後の2つの従属SLXスクリプトと1つの従属dzスクリプトが、最も内部の2つのループに対して不変であることがわかります。 SLXの場合、2つのインデックス(最も内部的なループの2つの制御変数)の左側は、配列の連続したフラグメントです。 コンパイラは、配列の固定(右側)インデックスを、ループから推測できる不変ループコードの候補として認識しませんでした。 さらに、コンパイラーはすべての左側にある2つの索引を認識できず、1つの索引に崩壊しました。
これは、コンパイラーによって実装できる最適化の良い例です。 この場合、次の最適化手順では、不変の従属スクリプトがループから取り出され、生産性が1.52倍に向上します。
doコードの多くには、いくつかの従属スクリプトを持つ配列の連続フラグメントが含まれていることがわかりました。 アプリケーション全体を書き直さずに従属スクリプトの数を減らすことは可能ですか?
回答:はい、少数の従属スクリプトで表される配列の小さなセクションをカプセル化することは可能です。 サンプルコードでこれを行う方法は?
このアプローチを2つのレベルのネストに適用することにしました。
- 入札の最も外部レベルで(モジュールデータは、実際のコードで65の入札値が使用されることを示します)。
- 次のレベルで-サイクルレベルでkを実行します。 さらに、最初の2つのインデックスを1つに結合します。
最外層は、 入札レベル配列のフラグメントを渡します。
bid = 1 ! in real application bid may iterate ! peel off the bid call ParallelNestedRank1_bid( & TLT%K_LEVEL(:,:,bid), & KMT(:,:,bid), & TLT%ZTW(:,:,bid), & KAPPA_THIC(:,:,:,:,bid), & SLX(:,:,:,:,:,bid), & SLY(:,:,:,:,:,bid)) … subroutine ParallelNestedRank1_bid(K_LEVEL_bid, KMT_bid, ZTW_bid, KAPPA_THIC_bid, SLX_bid, SLY_bid) use omp_lib use mod_globals implicit none integer, dimension(nx_block , ny_block) :: K_LEVEL_bid, KMT_bid, ZTW_bid real, dimension(nx_block,ny_block,2,km) :: KAPPA_THIC_bid real, dimension(nx_block,ny_block,2,2,km) :: SLX_bid, SLY_bid …
ポインターのない配列(分散サイズまたは固定サイズ)では、配列は連続していることに注意してください。 これにより、右端のインデックスを「切り捨て」て連続配列のフラグメントを送信することが可能になります。そのためには、より大きな配列のサブセットでオフセットを計算するだけです。 同時に、右端のインデックスを除く他のインデックスを「カットオフ」しようとするには、一時配列を作成する必要がありますが、これは避ける必要があります。 ただし、場合によってはこれでも適切な場合があります。
ネストされた2番目のレベルでは、 do kループ配列の追加のインデックスを開き、最初の2つのインデックスを1つに圧縮しました。
!$OMP PARALLEL DEFAULT(SHARED) !$omp do do k=1,km-1 call ParallelNestedRank1_bid_k( & K_LEVEL_bid, KMT_bid, ZTW_bid, & KAPPA_THIC_bid(:,:,:,k), & KAPPA_THIC_bid(:,:,:,k+1), KAPPA_THIC_bid(:,:,:,k+2),& SLX_bid(:,:,:,:,k), SLY_bid(:,:,:,:,k), & SLX_bid(:,:,:,:,k+1), SLY_bid(:,:,:,:,k+1), & SLX_bid(:,:,:,:,k+2), SLY_bid(:,:,:,:,k+2), & dz(k),dz(k+1),dz(k+2),dzwr(k),dzwr(k+1)) end do !$omp end do !$OMP END PARALLEL end subroutine ParallelNestedRank1_bid subroutine ParallelNestedRank11_bid_k( & k, K_LEVEL_bid, KMT_bid, ZTW_bid, & KAPPA_THIC_bid_k, KAPPA_THIC_bid_kp1, KAPPA_THIC_bid_kp2, & SLX_bid_k, SLY_bid_k, & SLX_bid_kp1, SLY_bid_kp1, & SLX_bid_kp2, SLY_bid_kp2, & dz_k,dz_kp1,dz_kp2,dzwr_k,dzwr_kp1) use mod_globals implicit none !----------------------------------------------------------------------- ! ! dummy variables ! !----------------------------------------------------------------------- integer :: k integer, dimension(nx_block*ny_block) :: K_LEVEL_bid, KMT_bid, ZTW_bid real, dimension(nx_block*ny_block,2) :: KAPPA_THIC_bid_k, KAPPA_THIC_bid_kp1 real, dimension(nx_block*ny_block,2) :: KAPPA_THIC_bid_kp2 real, dimension(nx_block*ny_block,2,2) :: SLX_bid_k, SLY_bid_k real, dimension(nx_block*ny_block,2,2) :: SLX_bid_kp1, SLY_bid_kp1 real, dimension(nx_block*ny_block,2,2) :: SLX_bid_kp2, SLY_bid_kp2 real :: dz_k,dz_kp1,dz_kp2,dzwr_k,dzwr_kp1 ... ! next note index (i,j) compression to (ij) do kk=1,2 do ij=1,ny_block*nx_block if ( LMASK1(ij) ) then
連続配列の配列(参照)が呼び出しポイントで送信されることに注意してください。 呼び出されたプロシージャに対する空の引数は、異なるインデックスセットを持つ同じサイズの連続したメモリピースを示します。 Fortranで作業する場合に注意すれば、これは完全に実行可能です。
コードを作成するためのすべてのアクションは、コピーと貼り付け操作、そして検索と置換になります。 これ以外は、コードストリームは変更されません。 これは、注意深い初心者プログラマーが必要な指示を行うことで実行できます。
コンパイラの将来のバージョンでは、組み込みの最適化ツールによりこれらすべてのアクションが不要になる場合がありますが、「不要な」プログラミングにより生産性が大幅に向上する場合があります(この場合、52%増加)。
同等の命令は次のとおりです。

アセンブラコードは次のようになります。

46命令の代わりに、6命令が残り、7.66倍少なくなりました。 したがって、配列内のスレーブスクリプトの数を減らすと、命令の数が減ります。
「カッティング」による2レベルの投資の導入により、生産性が1.52倍に向上しました。 52%のパフォーマンスの向上は、余分な努力の価値がありますか? ここでは、すべてが主観的であると決めてください。 コンパイラの将来のバージョンで規定された最適化アルゴリズムは、不変配列の従属スクリプトを抽出するものと想定できます。これは上記で手動で行われました。 ただし、現時点では、インデックスの「切り取り」と圧縮の説明されている手法を使用できます。
私の推奨事項が役立つことを願っています。
» ソースコードの例