 これは、Node.jsを使用したWebスクレイピングスクリプトの作成と使用に関するシリーズの最初の記事です。
これは、Node.jsを使用したWebスクレイピングスクリプトの作成と使用に関するシリーズの最初の記事です。
- Node.jsを使用したWebスクレイピング
- Node.jsおよび問題のあるサイトでのWebスクレイピング
- Node.jsでのWebスクレイピングとボット保護
- Node.jsを使用した更新データのWebスクレイピング
ウェブスクレイピングのトピックは、少なくともそれがフリーランサーにとっては小さいが便利で興味深い注文の無尽蔵なソースであるため、ますます関心を集めています。 当然、より多くの人々がそれが何であるかを理解しようとしています。 ただし、次のライブラリのドキュメントから抽象的な例のウェブスクラップを理解するのはかなり困難です。 実際の問題の解決策を段階的に観察することで、このトピックを理解するのがはるかに簡単になります。
通常、Webスクレイピングのタスクは次のようになります。Webページでのみ使用可能なデータがあり、それらを取り出して一種の消化可能な形式で保存する必要があります。 誰もコンバーターをキャンセルしていないため、最終的なフォーマットは重要ではありません。 ほとんどの場合、ブラウザを開き、リンクをマウスでクリックして、ページから必要なデータをコピーします。 まあ、またはスクリプトで同じことを行います。
この記事の目的は、タスクの設定から最終結果の取得まで、このようなスクリプトを作成および使用するプロセス全体を示すことです。 例として、フリーランスのやり取りなどでよく見られるタスクのような実際のタスクを検討し、WebスクレイピングのツールとしてNode.jsを使用します。
問題の声明
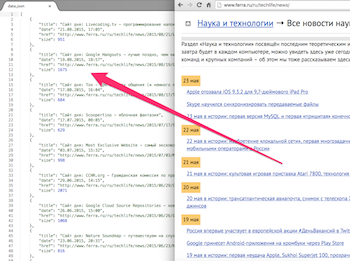 Ferra.ruに投稿したすべての記事とメモのリストを取得するとします。 出版物ごとに、タイトル、リンク、日付、テキストサイズを取得します。 このサイトには便利なAPIがないため、ページからデータを取得する必要があります。
Ferra.ruに投稿したすべての記事とメモのリストを取得するとします。 出版物ごとに、タイトル、リンク、日付、テキストサイズを取得します。 このサイトには便利なAPIがないため、ページからデータを取得する必要があります。
何年もの間、私はサイトで別のセクションを組織することを気にしなかったので、私の出版物はすべて通常のニュースと混同されます。 私が知っている唯一の方法は、必要な出版物を強調することです-著者によるフィルタリング。 作成者はニュースリストのあるページには表示されないため、対応するページですべてのニュースを確認する必要があります。 すべてのニュースではなく、1つのセクションで検索できるように、「科学と技術」セクションでのみ記述したことを覚えています。
ここでは、ほぼこの形式で、Webスクレイピングのタスクが通常私に来ます。 そのようなタスクでさえ、さまざまな驚きと落とし穴がありますが、それらはすぐには見えないので、それらを見つけて、プロセスの中で正しく解決する必要があります。 始めましょう:
サイト分析
ニュースページが必要であり、そのページへのリンクはページ分割されたリストに収集されます。 必要なすべてのページは許可なく使用できます。 ブラウザでページのソースを確認すると、すべてのデータがHTMLコードに直接含まれていることを確認できます。 かなり単純なタスク(実際、それが私がそれを選んだ理由です)。 ログイン、セッションの保存、フォームの送信、AJAXリクエストの追跡、接続されたスクリプトの解析などを行う必要はないようです。 ターゲットサイトの分析には、スクリプトの設計と作成よりも数倍時間がかかる場合がありますが、今回はそうではありません。 多分次の記事で...
プロジェクトの準備
プロジェクトディレクトリ(およびその中の空のindex.jsファイルと最も単純なpackage.jsonファイル)の作成、Node.jsとnpmパッケージマネージャーのインストール、およびnpmを介したモジュールのインストールと削除について説明することは意味がないと思います。
実生活では、プロジェクトの開発にはGITリポジトリのメンテナンスが伴いますが、これは記事のトピックの範囲を超えているため、実生活での重要なコード変更ごとに個別のコミットが行われることに注意してください。
ページを取得する
ページのHTMLコードからデータを取得するには、サイトからこのコードを取得する必要があります。 これは、デフォルトでNode.jsに組み込まれたhttpモジュールのhttpクライアントを使用して行うことができますが、単純なhttpリクエストの場合、 http
異なるラッパーモジュールを使用する方が便利です。最も人気のあるリクエストはrequestです。試してみましょう。
最初のステップは、 request
モジュールがブラウザーから来るのと同じHTMLコードをサイトから受信することを確認することです。 ほとんどのサイトではそうなりますが、ブラウザに何かを与えるサイトに出くわすことがあり、httpクライアントでのスクリプトは異なります。 最初に、 curlからのGETリクエストでランディングページを最初にチェックしましたが、ある日、curlでrequest
スクリプトで異なるhttp応答をrequest
サイトに遭遇したため、すぐにスクリプトを実行しようとしました。 およそ次のコードで:
var request = require('request'); var URL = 'http://www.ferra.ru/ru/techlife/news/'; request(URL, function (err, res, body) { if (err) throw err; console.log(body); console.log(res.statusCode); });
スクリプトを実行します。 サイトが嘘をついているか、問題の関連がある場合、エラーが発生し、すべてが問題ない場合、ページのソーステキストの長いシートが直接ターミナルウィンドウに表示され、ブラウザとほぼ同じであることを確認できます。 これは良いことなので、ページを取得するために特別なCookieやhttpヘッダーを設定する必要はありません。
ただし、怠けすぎず、テキストをロシア語のテキストまでスクロールすると、 request
がエンコードを誤って定義していることに気付くでしょう。 たとえば、ロシア語のニュースヘッドラインは次のようになります。
4.7- iPhone 7
PC- DOOM 4 4
エンコーディングの問題は、インターネットの夜明けほど頻繁には発生しませんが、それでもかなり頻繁に発生します(APIのないサイトでは、特に頻繁に発生します)。 要求モジュールにはencoding
パラメーターがありますが、Node.jsで受け入れられたエンコードをサポートしており、バッファーを文字列に変換できます。 これはascii
、 utf8
、 utf16le
(別名ucs2
)、 base64
、 binary
およびhex
、 windows-1251
が必要であることを思い出させてください。
この問題の最も一般的な解決方法は、 encoding
をnull
request
設定して、ソースバッファーをbody
に配置し、 iconvまたはiconv-liteモジュールを使用して変換することです。 たとえば、次のように:
var request = require('request'); var iconv = require('iconv-lite'); var opt = { url: 'http://www.ferra.ru/ru/techlife/news/', encoding: null } request(opt, function (err, res, body) { if (err) throw err; console.log(iconv.decode(body, 'win1251')); console.log(res.statusCode); });
このソリューションの欠点は、すべての問題のあるサイトで、エンコードの把握に時間を費やす必要があることです。 このサイトが最後ではない場合は、より自動化されたソリューションを見つける必要があります。 ブラウザがエンコーディングを理解していれば、スクリプトもそれを理解するはずです。 実際のオタクの方法は、GitHubでrequest
モジュールを見つけて、その開発者がiconv
からのエンコーディングサポートを実装するのを支援することです。 さて、またはブラックジャックと良好なエンコーディングのサポートであなたのフォークを作ります。 経験豊富な開業医にとっての道は、 request
モジュールの代替を探すことです。
同様の状況で、私はニードルモジュールを見つけ、とても嬉しくなり、 request
使用しなくなりました。 デフォルト設定では、 needle
はブラウザと同じ方法でエンコーディングを決定し、http応答のテキストを自動的にトランスコードします。 そして、これはneedle
request
よりも優れている唯一のものではありません。
needle
問題のページを取得してみましょう:
var needle = require('needle'); var URL = 'http://www.ferra.ru/ru/techlife/news/'; needle.get(URL, function(err, res){ if (err) throw err; console.log(res.body); console.log(res.statusCode); });
今ではすべてが素晴らしいです。 あなたの良心をクリアするには、 別のニュースページで同じことを試してください。 そこもすべて順調です。
クロール
次に、各ニュースのページを取得し、そのニュースの著者の名前を確認し、もしそうなら、必要なデータを保存する必要があります。 ニュースページへのリンクの既製リストがないため、ページ分割されたリストを調べることで再帰的に取得します。 検索エンジンのクローラーのように、より正確にのみ。 したがって、スクリプトを使用してリンクを取得し、処理のために送信し、有用なデータ(存在する場合)をどこかに保存し、同じ処理のために新しいリンク(ニュースまたはリストの次のページ)をキューに入れる必要があります。
最初は、いくつかのパスでクロールを実行する方が簡単に見えるかもしれません。 たとえば、最初にページ分割されたリストのすべてのページを再帰的に収集し、次にそれらからすべてのニュースページを取得してから、各ニュース項目を処理します。 このアプローチは、初心者がスクレイピングプロセスを念頭に置くのに役立ちますが、実際には、すべてのタイプの要求に対する単一レベルの単一キューが、少なくとも、より簡単かつ迅速に開発されます。
このようなキューを作成するには、有名な非同期モジュールのqueue
機能を使用できますが、 async.queue
と下位互換性があるが、 async
モジュールの残りの機能が含まれていないため、はるかに少ないasync.queue
モジュールを使用することを好みます。 小さなモジュールはスペースをとらないため(これはナンセンスです)、良くありませんが、特に困難なクロールに必要な場合はすぐに終了しやすいためです。
tress
は次のように機能します。
var tress = require('tress'); var needle = require('needle'); var URL = 'http://www.ferra.ru/ru/techlife/news/'; var results = []; // `tress` var q = tress(function(url, callback){ // url needle.get(url, function(err, res){ if (err) throw err; // res.body // results.push // q.push callback(); // callback }); }); // , q.drain = function(){ require('fs').writeFileSync('./data.json', JSON.stringify(results, null, 4)); } // q.push(URL);
関数が毎回http-requestを実行し、実行中にスクリプトがアイドル状態になることに注意してください。 そのため、スクリプトはかなり長い間機能します。 速度を上げるためにtress
2番目のパラメーターでtress
並列処理できるリンクの数に渡すことができます。 同時に、スクリプトは1つのプロセスと1つのスレッドで動作し続け、Node.jsの非ブロッキングI / O操作によって並列性が確保されます。
解析
すでに持っているコードは、スクレイピングのベースとして使用できます。 実際、最も単純なミニフレームワークを作成しました。これは、次の難しいサイトに出会うたびに徐々に改良でき、単純なサイト(大部分)の場合は、解析を担当するコードを簡単に記述できます。 このフラグメントの意味は常に同じです。入力-HTTP応答の本文、および出力-結果の配列とリンクキューの補充。 解析ツールは、残りのコードに影響を与えません。
解析の達人は、ページを解析する最も強力で用途の広い方法が正規表現を使用することであることを知っています 。 これにより、非常に非標準的で非常にセマンティックなレイアウトでページを解析できます。 一般的に、言語を知らなくてもデータをサイトから間違いなくコピーできる場合、定期的に解析できます。
ただし、ほとんどのHTMLページはDOMパーサーによって簡単に解析されるため、はるかに便利で読みやすくなっています。 レギュラーは、DOMパーサーが失敗した場合にのみ使用してください。 私たちの場合、DOMパーサーは完璧です。 現在、Node.jsのDOMパーサーの中で、 cheerioは自信を持ってリーダーです-カルトJQueryのサーバーバージョンです。
( ちなみに、Ferra.ruはJQueryを使用しています。これは、 cheerio
がそのようなサイトに対処するかなり信頼できるサインです )
最初は、ページの種類ごとに個別のパーサーを作成する方が便利な場合があります(この場合、リストとニュースの2つがあります)。 実際、ページ上で各種類のデータを簡単に検索できます。 必要なデータがページにない場合、それらは単に見つかりません。 異なるタイプのページで異なるデータが同じに見える場合、混乱を避ける方法について考える必要がありますが、難しいサイトを見たことはありません。 しかし、さまざまな種類のデータが同じページにランダムに結合されている多くのサイトに出会ったため、すべてのページに対して単一のパーサーをすぐに作成することに慣れる価値があります。
そのため、ニュースリンクのリストは、 b_rewiev
クラスを持つdiv
要素内にあります。 そこには必要のない他のリンクがありますが、正しいリンクは簡単に見分けられます。なぜなら、そのようなリンクのみが親p
要素を持っているからです。 ページネーションの次のページへのリンクは、クラスbpr_next
持つspan
要素内にあり、単独で存在します。 ニュースページとリストの最後のページには、そのような要素はありません。 pajinatorのリンクは相対的であることを考慮する価値があるため、絶対リンクにリンクすることを忘れないでください。 著者の名前は、クラスb_infopost
持つdiv
要素の奥深くに隠されています。 リストページにはそのような要素はないため、作成者が一致すれば、愚かなニュースデータを収集できます。
壊れたリンクを忘れないでください(ネタバレ:破棄するセクションには、そのようなリンクが1つあります)。 または、各リクエストのレスポンスコードを確認できますが、ページにコード200
リンクが破損しているサイトがあります(たとえ「404」と書かれていても)。 別のオプションは、パーサーで検索する要素について、そのようなページのコードを調べることです。 この場合、壊れたリンクページにはそのような要素はないため、パーサーはそのようなページを単に無視します。
cheerio
を使用してコードに解析を追加します。
var tress = require('tress'); var needle = require('needle'); var cheerio = require('cheerio'); var resolve = require('url').resolve; var fs = require('fs'); var URL = 'http://www.ferra.ru/ru/techlife/news/'; var results = []; var q = tress(function(url, callback){ needle.get(url, function(err, res){ if (err) throw err; // DOM var $ = cheerio.load(res.body); // if($('.b_infopost').contents().eq(2).text().trim().slice(0, -1) === ' '){ results.push({ title: $('h1').text(), date: $('.b_infopost>.date').text(), href: url, size: $('.newsbody').text().length }); } // $('.b_rewiev p>a').each(function() { q.push($(this).attr('href')); }); // $('.bpr_next>a').each(function() { // q.push(resolve(URL, $(this).attr('href'))); }); callback(); }); }, 10); // 10 q.drain = function(){ fs.writeFileSync('./data.json', JSON.stringify(results, null, 4)); } q.push(URL);
基本的に、問題を解決するWebスクレイピング用のスクリプトを入手しました( 要点 、 要点コード )。 ただし、このようなスクリプトはお客様に提供しません。 並列リクエストでも、このスクリプトは長時間実行されます。つまり、少なくとも実行プロセスの表示を追加する必要があります。 また、通信が短時間中断しても、中間結果を保存せずにスクリプトがクラッシュするため、クラッシュする前にスクリプトに中間結果を保存するか、クラッシュせずに一時停止するようにする必要があります。 また、スクリプトを強制的に中断し、同じ場所から続行する機会を自分で追加します。 これは概して過剰ですが、そのような「ケーキの上のチェリー」は顧客との関係を大いに強化します。
ただし、顧客がデータを1回廃棄して、結果を含むファイルを送信するように要求した場合、これを行うことはできません。 すべてがそのように機能します(10スレッドで23分、1005の出版物と1つの壊れたリンクが見つかりました)。 完全に怠solな場合、pajinatorを再帰的にパスすることはできませんが、Ferra.ruで働いていた期間のテンプレートからリストページへのリンクを生成できます。 その場合、スクリプトは長すぎません。 これは最初は面倒ですが、これらのソリューションの選択は、Webスクレイピングタスクの重要な部分でもあります。
おわりに
原則として、そのようなスクレーパーの書き方を知っていれば、フリーランスの取引所で注文を取り、生活することができます。 ただし、いくつかの問題があります。 第一に、多くの顧客は最終データを望んでおらず、彼ら自身が問題なく使用できるスクリプトを望んでいます(そして、彼らは非常に特定の要件を持っています)。 第二に、注文が既に行われ、作業の半分が既に完了している場合にのみ発見されるサイトには困難があり、お金と評判を失うか、精神的搾取を行う必要があります。
近い将来、より複雑なケース(セッション、AJAX、サイトでの不具合など)およびWebスクレーパースクリプトを市場性のある外観にすることに関する記事を計画しています。 質問や提案を歓迎します。