みなさんこんにちは。
私たちは、Drupalが作成した古典的なWeb 2.0サイトです。 私たちはメディアサイトであると言えます さまざまな記事があり、新しい記事が絶えず公開されています。 SEOに多くの注意を払っています。 このために、フルタイムで働く人々を特別に訓練しました。
1か月あたり40万人以上のユニークユーザーが訪れます。 これらのうち、90%はGoogle検索によるものです。
そしてほぼ半年間、私たちはサイトのシングルページアプリケーションバージョンを開発してきました。
おそらく既にご存知のように、JSはseashnikの永遠の痛みです。 また、JSでサイトを作成することはできません。
開発を開始する前に、この問題の調査を開始しました。
そして、彼らは、一般的に受け入れられている方法は、ページの既にレンダリングされたバージョンをグーグルボットに戻すことであるとわかりました。
AJAXアプリケーションをクロール可能にする
また、この方法はGoogleによって推奨されなくなり 、ボットがjsサイトを開くことができることを保証します。これは、最新のブラウザーよりも悪くありません。
通常 、最新のブラウザのようにWebページをレンダリングして理解できます。
なぜなら Googleが決定した時点では、Googleはこの方法を放棄したばかりで、GoogleクローラーがJSで作成されたサイトを実際にインデックスする方法を確認する時間はありませんでした。 私たちは、チャンスを利用して、ボット用の追加レンダリングページなしでSPAサイトを作成することにしました。
なんで?
サーバーの負荷が不均一であり、ページを柔軟に最適化できないため、サイトをバックエンド(Drupalの現在のバージョン)とフロントエンド(AngularJSのSPA)に分割することが決定されました。
Drupalは、コンテンツを管理し、あらゆる種類のメールを送信するためにのみ使用します。
AngularJSは、サイトユーザーが利用できるはずのすべてを描画します。
技術的な詳細
フロントエンドのサーバーとして、 Node.js + Expressを使用することが決定されました。
RESTサーバー
新しいプレフィックス/ v1 /を作成するだけで、DrupalからRESTサーバーを作成しました。 / v1 /に着信するすべてのリクエストは、RESTへのリクエストとして認識されました。 他のすべてのアドレスは変更されませんでした。
ページアドレス
すべての公開ページが以前と同じアドレスに存在することは、私たちにとって非常に重要です。 そのため、SPAバージョンを開発する前に、すべてのページが共通のプレフィックスを持つように構造化しました。 例:
すべてのフォーラムページは/ forum / *に存在する必要がありますが、フォーラムにはカテゴリとトピック自体があります。 それらの場合、URLは/forum/{category}/{topic}
ます。 ランダムなアドレスにはランダムなページがなく、すべてが論理的に構造化されている必要があります。
リダイレクト
このサイトは2007年から利用可能になっており、この間に多くの変更が行われました。 ページアドレスを含む。 あるアドレスから別のアドレスにページがどのように移動したかのストーリー全体を保存しました。 そして、古いアドレスを要求しようとすると、新しいアドレスにリダイレクトされます。
新しいフロントエンドもリダイレクトするために、ページをnodejsに送信する前に、リクエストをDrupalに送り返し、リクエストされたアドレスの状態を尋ねます。 次のようになります。
curl -X GET --header 'Accept: application/json' 'https://api.example.com/v1/path/lookup?url=node/1'
Drupalの答え:
{ "status": 301, "url": "/content/industry/accountancy-professional-services/accountancy-professional-services" }
その後、nodeJSは、現在のアドレスが200であれば現在のアドレスに留まるか、別のアドレスにリダイレクトするかを決定します。
app.get('*', function(req, res) { request.get({url: 'https://api.example.com/v1/path/lookup', qs: {url: req.path}, json: true}, function(error, response, data) { if (!error && data.status) { switch (data.status) { case 301: case 302: res.redirect(data.status, 'https://www.example.com' + data.url); break; case 404: res.status(404); default: res.render('index'); } } else { res.status(503); } }); });
画像
Drupalからのコンテンツには、フロントエンドバージョンには存在しないファイルが含まれている場合があります。 そのため、nodejsを介してDrupalで単純にストリーミングすることにしました。
app.get(['*.png', '*.jpg', '*.gif', '*.pdf'], function(req, res) { request('https://api.example.com' + req.url).pipe(res); });
sitemap.xml
なぜなら sitemap.xmlは常にDrupalで生成され、ページアドレスはフロントエンドと同じであり、sitemap.xmlをストリーミングするだけでした。 写真と同じように:
app.get('/sitemap.xml', function(req, res) { request('https://api.example.com/sitemap.xml').pipe(res); });
注意を払う価値があるのは、Drupalがフロントエンドで使用されているサイトの正しいアドレスを代用することだけです。 管理パネルに設定があります。
robots.txt
- Googleクローラーボットのコンテンツで利用可能なコンテンツは、2つのサーバー間で複製しないでください。
- Drupalからフロントエンドを介して要求されたすべてのコンテンツは、ボットが表示できるようにする必要があります。
その結果、robots.txtは次のようになります。
Drupalで、/ v1 /を除くすべてを無効にします。
User-agent: * Disallow: / Allow: /v1/
フロントエンドでは、すべてを許可します。
User-agent: *
リリース準備
リリース前に、フロントエンドバージョンをhttps://new.example.comのアドレスに配置しました。
また、Drupalの場合、バージョンは追加のサブドメインhttps://api.example.com/を予約しました
その後、フロントエンドをリンクしてhttps://api.example.com/アドレスで動作するようにしました。
発売日
リリース自体は、DNS内のサーバーの単純な再配置のように見えます。 現在の@アドレスをフロントエンドサーバーにポイントします。 次に、座ってすべてがどのように機能するかを確認します。
CNAME
レコードを使用すると、サーバーが即座に置き換えられることに注意してください。 レコードは、最大48時間DNSによって解決されます。
性能
サイトがフロントエンドとバックエンドに分割された後、サーバーの負荷が測定されました。 また、SQLクエリを特に最適化せず、すべてのクエリがキャッシュなしで実行されることにも注意してください。 すべての最適化はリリース後に計画されました。
リリース前にメトリックはありませんでしたが、ロールバックした後にメトリックがあります:)


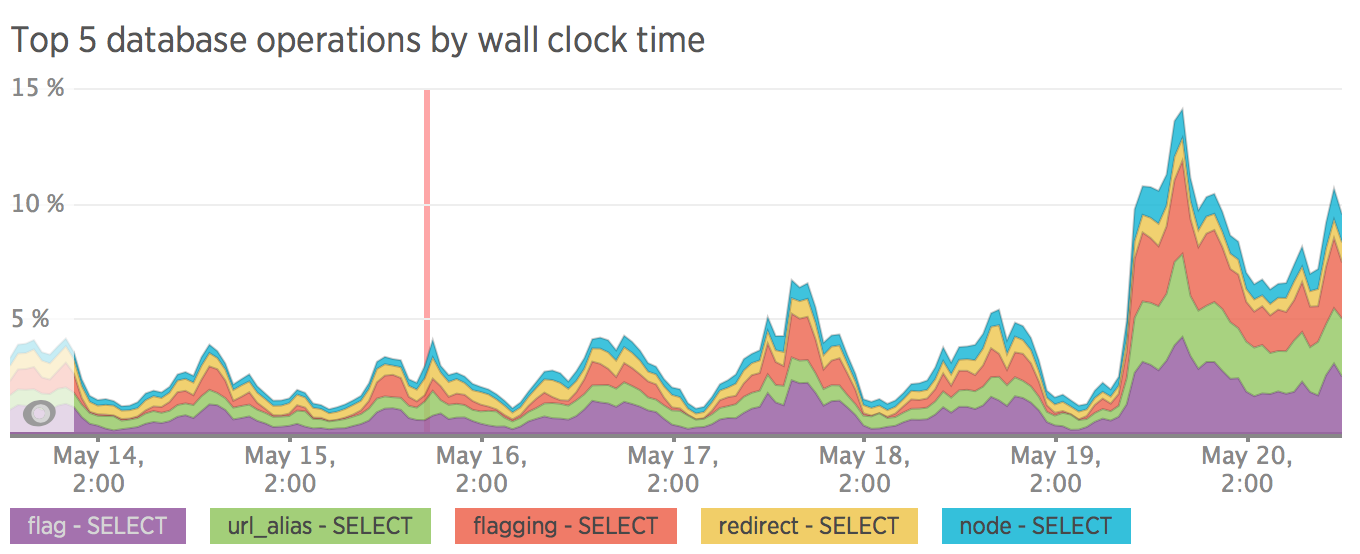
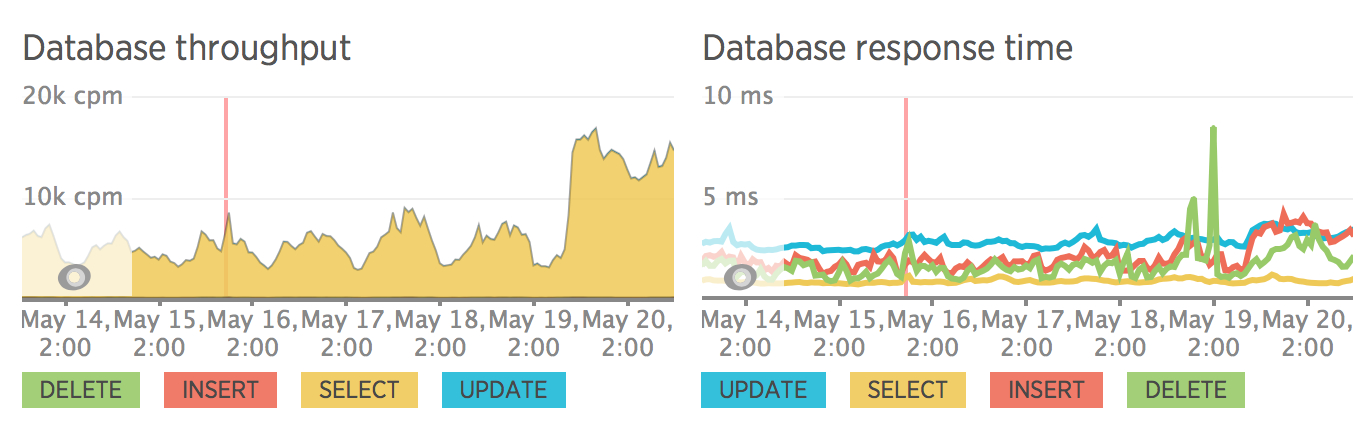
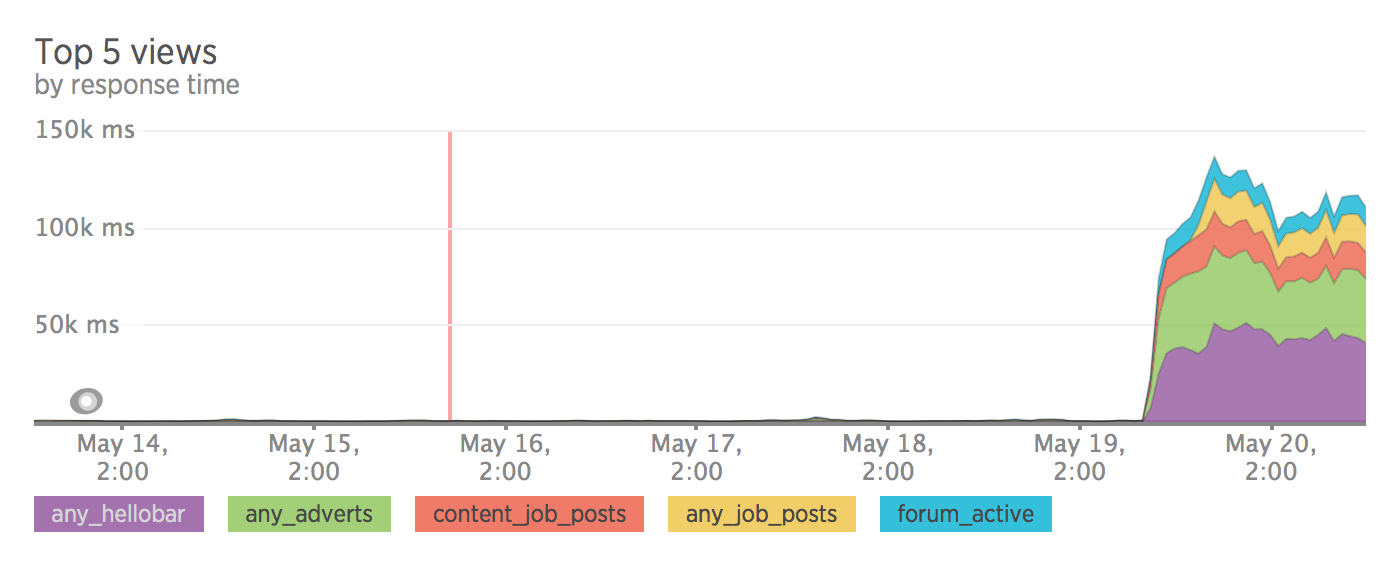
SEO
ここでは、すべてが私たちが望むほど良くないことが判明しました。 わずか1週間のテストの後、サイトへのトラフィックは30%減少しました。

いくつかのページはグーグルのインデックスから外れ、いくつかはメタ記述なしで非常に奇妙なインデックスに登録されました。
Googleがこのページをインデックスに登録した方法の例。

また、新しいサイトのリリース後、Googleはこれに気付き、パニックでサイト全体のインデックスを再作成し始めたことにも気付きました。 これにより、キャッシュ全体が更新されます。

その後、Crawlerは膨大な数の古いページを検出しましたが、これは昔はインデックスに登録されていなかったはずです。
以下のグラフは、404ページで見つかったグラフを示しています。 リリース前にコンテンツを削除し、Googleが古いページを徐々に削除したことがわかります。 しかし、リリース後、彼はこれをより積極的に行い始めました。
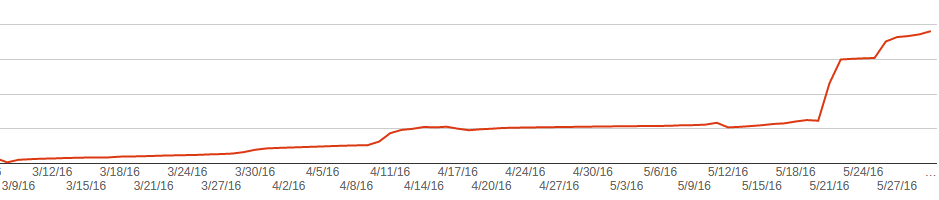
結果/結論
インデックス作成の問題により、Drupalにロールバックし、間違ったことをしたと判断しました。
Googleは一種のブラックボックスであり、何か問題が発生してもインデックスからページが削除されるだけではないため、すべてが複雑になっています。 また、どの実験でも検索結果に反映するには数日かかります。
最も可能性の高いバージョンの1つは、Googleクローラーに特定の制限があることです。 これは、メモリ、またはページが描画された時間です。
ストップウォッチ付きのページを作成して少しテストを行い、Google Search Consoleでクローラーとしてレンダリングしようとしました。 スクリーンショットでは、ストップウォッチは5.26秒で停止しました。 クローラーはページを約5秒間待機してからスナップショットを実行し、その後ロードされたすべてがインデックスに入らないと思います。
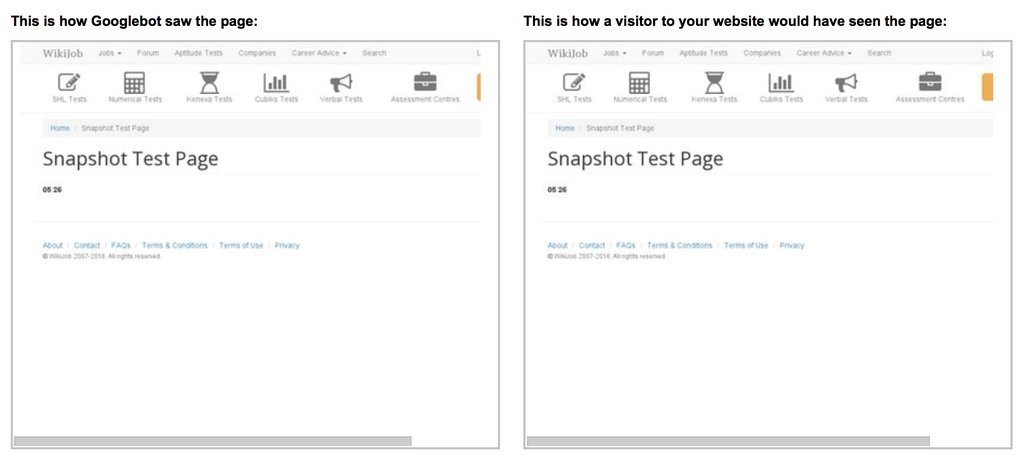
便利なリンク
更新する
- トラフィックがどのように低下したかを示すGoogleアナリティクスのグラフを追加しました。
- Google Crawlerがページをレンダリングするのに約5秒かかることがわかりました。
- Google Crawlerは、サイトがいつ更新されるかを理解し、インデックスを再作成することがわかりました。