
今日は突然 、プレゼンテーションについてではありません。 事実、過去に少しb / bのテストを行って、昨日、実験を開始する前にa / aテスト(つまり、コントロールグループが同じバージョンのサイトを見るもの)を行う必要があるという記事に再び行きました実験的として)、私はこの質問に2ペニーを追加することができ、追加する必要があると決めました。 私のブログではコアではないことが判明しましたが、できればおそらくそうでしょう。 そうでなければ、それは私を引き裂きます、はい。
壊血病の治療法を探しているときに、人命の損失という観点からのa / bテストで最も費用のかかる間違いがいくつかありました。 レモンが彼女を助けることは明らかであるように思われた後、実験は再実施され、そこで、すでに臨床現場で、患者はレモンジュース濃縮物で治療されました。 そして、18世紀にどのように濃縮物が得られましたか? もちろん、長時間の煮沸によって。 さて、あなたは理解しています:以前に得られた結果の臨床検査は確認しませんでした。 そして、ポストの写真のように扱われるだけでした。 人間の生活がa / bテストシステムのエラーに直接依存していないことを期待できますが、エラーがないと仮定することはできません。 そして、ここにいくつかのテストとの接続があります。
制御実験が悪いのはなぜですか?
用語の余談
私はときどきa /テストを対照実験または単なる対照と呼びます。 また、実際のa / b実験の場合、コントロールとは、実験バージョンではなく、実動バージョン( コントロールグループまたはコントロールサンプルでもある )を見るユーザーのセットを指します。 文脈から正確に何が議論されているかを常に明確にし、「コントロール」と「コントロール」の概念を混同しないようにします。
また、「実験によって特定の統計的有意性を持つ勝者が明らかになった」たびに書くことはできず、代わりに働いた、または発した言葉を使用します。 明らかにならない場合は、機能しませんでした。
実際には、クレーム
実際の実験を開始する前の制御は不十分です。 なぜ人々はそれを使うのですか? システムの2つの同一バージョンのいずれも勝てないことを確認する。 私たちは皆、すずめです。統計的有意性が必要であることを知っています(知っていますよね?)。そして、利用可能なユーザーに応じて、ツールでしきい値を0.95(ユーザーに関して深い絶望的な貧困がある場合)、0.99(これは通常の場合のプラスまたはマイナス)または0.999以上(GoogleまたはYandexが好きな場合、または小さなスプレッドで推定できる非常に優れたメトリックを考えた場合)。
これらの数字はどういう意味ですか? 統計的有意性のしきい値は、私たちが犯す準備ができている間違いの割合のみを示します。 0.95という数値は、0.05の場合に誤った決定を下す準備ができていることを意味します。つまり、平均で20回に1回、0.99ではすでに100回に1回などです。 つまり、一定の割合のコントロールには、システムが正常に動作しているときに勝者を表示する権利があります。 注意、修辞的な質問:システムの通常の動作を単一の開始から確認することは可能ですか? もちろん違います。 問題が実装に忍び込んだ場合、すべてのコントロールが勝者を識別する必要はありません(いわゆる誤検知を発行します)。 20個のうちの1個ではなく、2個または3個になる可能性があります。 またはさらに半分。
重要度が0.95の場合、20回の制御実験によりシステムの通常の動作を確認することは可能ですか? あなたの意見では、システムが正常に機能するためには、20の制御のうちどれだけの誤検知が必要ですか?
異なる数の応答を取得する確率は次のようになります(右側にもゼロはなく、このスケールでは表示されません)。
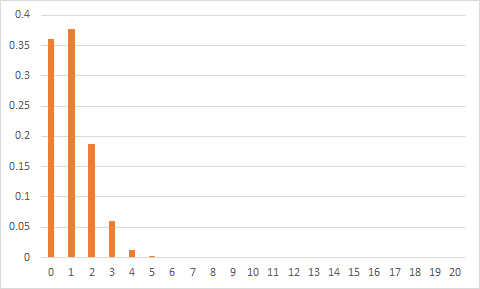
つまり、1つを取得し、何も取得しない確率は非常に近くて大きい、2つも簡単ですが、少し複雑ですが、3つは疑わしいですが、4つではシステムが正しく動作しない、5つ以上で賭けることができますすでにお金ではなく、体の一部で、すべてがごく普通に壊れているrastakとrazedakです。
単一の応答を受け取っていない場合、私たちはあまり幸せになるべきではありません。 この場合、反対方向の故障を除外することは不可能です。勝者をまったく明らかにしないシステムを取得できます。 これは個別に確認する必要があります。
20の実験のうち、5つがトリガーされ(つまり、すべてが非常に悪い)、1つだけを実行したと想像してみましょう。 動作する可能性はわずか0.25(20のうち5)です。 つまり、このような誤ったシステムに対して1つの制御を実行した場合、4つのうち3つのケースでは何も疑わないでしょう。
それでは、対照実験の代わりに何をすべきか?
1回の対照実験の代わりに、最初にそのような実験を絶えず(これが理想的です)または少なくとも定期的に実施し、蓄積された統計を監視する必要があります。 最も無害なものであっても、実験システムに変更を加えた場合、最新バージョンに蓄積された統計を個別に考慮することは理にかなっています。 制御実験が、与えられたレベルの重要性を持っていると想定されるよりも頻繁に発火する場合、これは何かが間違っているという強いシグナルです。
これが正確にどのように役立つか
もちろん、継続的な監視実験は万能薬ではありません。その助けを借りても、起こりうるすべての問題から安全に遊ぶことはできません。 しかし、時間の経過とともにかなりの数のことに気付くでしょう。例を以下に示します。
分類分類
まず、実験システムのエラーは次の2つの場所のいずれかに隠れている可能性があることに注意してください。
- 実験打ち上げシステム。 ユーザーを分割し、どのユーザーに何を表示するかを決定するだけです。
- 実験結果の計算。 メトリックの計算、統計テストの実装。
間違いは、実装、アルゴリズム、または決定方法の概念にあります。
結果を計算する際のエラーはわずかにトラウマが少なくなります。ユーザーアクティビティログ ( ログ?他のログ? )を保持する場合、エラーを修正し、影響を受けたすべての実験を遡及的に再計算して画像を復元できます。 もちろん、ユーザーは、実験の誤った結果のために本番環境に移行することを決めたものを見ることはありませんが、少なくともそれがどれほど悪いかは理解できます。 実験を開始するためのシステムが壊れている場合、すべてが悪化します。 この6か月間で何がロールアウトされたかを理解するには、正しく機能していなかったので、影響を受けるすべての実験をやり直す必要があります。 動的に開発しているサイトが6か月前のバージョンを復元することは、現実では不可能なファンタジーであることは明らかです。
より説得力を持たせるために、実験と計算システムの概念的な問題の一例を挙げます。
ユーザー分割の問題
プロジェクトが成長すると、開発者とデザイナーが増え、ある時点で、実験システムのスループットが、彼らが生み出す改善の
これにより、社内での実験の量を標準化することができ(一定の時間、この一定の量で改善が得られない場合、変更は十分ではありません)、ユーザーのダウンタイムを回避できます。 利点はコンテナ輸送の場合とほぼ同じで、実験の実行と追跡は非常に簡単です。
そのため、失敗した実験(非アクティブなボタン、壊れたレイアウト、または非常に貧弱なコンテンツ集約アルゴリズム)に本当にひどいものを見せて、すぐにこれに気付かない場合、そのようなバケツのユーザーは長い間不幸になります。また、彼らの行動は、拷問を受けていない一般ユーザーの行動とは異なります。 ビングからの仲間は、悪い実験の後、空になったバケツがコントロールグループにされたときに、故意に状況を捉えました。 この不幸なバケツのユーザーあたりのセッション数は、主な指標であり(これは実際にユーザーの忠誠心の良い尺度です)、まだ他のコントロールのバケツよりもずっと低くなっています:
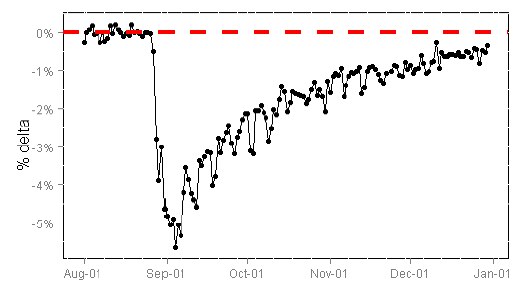
ここからの画像: www.exp-platform.com/documents/puzzlingoutcomesincontrolledexperiments.pdf
現実はこの写真よりもはるかに劇的であることに別に注意してください:人々はクッキーからのハッシュコードによってバケットに分割され、3か月間、おそらくかなりの割合のユーザーがおそらくクッキーの崩壊のためにバケットで更新されています。 つまり、3か月の終わりまでには、破壊的に暴露されていないユーザーが
私自身の経験は、実験からのポストエフェクトの存在を確認しています。
定期的に管理を実施している場合、この問題に気づき修正する機会があります 。 いいえ、可能性は100%ではありません。一部のバケットが永久に制御下にあると、そこに表示されません。 しかし、まだ。 たとえば、修正のために、すべてのユーザーCookie(またはハッシュにCookieの代わりに使用するもの)に同じ修飾子を追加することで、バケット間でユーザーを定期的に混在させることができます。
実験計算システムの問題
コンバージョンに直接焦点を当てない場合(オンラインストアでない場合、これは正常です)、ユーザーのアクションから計算された何らかの種類のインジケーターが必要です。 クリック、サイトへの訪問、何でも。 危険は、すべてのユーザーのすべてのアクションを1つの大きな山に集め、その平均値を読み取ることにあります。
対照サンプルと実験サンプルの特定の測定基準で得られた平均値の差の統計的有意性の計算は、 中央極限定理 (以降-CLT)に基づいています。 彼女は、平均が正規分布を持っていることを教えてくれます。つまり、信頼区間を十分に評価し、対照群と実験群で平均が異なるかどうかの判定を行うことができます。
ここでの問題は、TSCが平均化された測定値の独立性を必要とすることです。
忘れた人のためのイベントの独立の指
1つの既知の結果が別の可能性に影響しない場合、イベントは独立していると見なされます。 依存イベントの鮮明な例は、同じ人が80歳から90歳まで生存することです。 人が90歳まで生きたことがわかっている場合、80歳まで生き残る確率は1です。逆の方向では、人が80歳に達していなければ、90歳まで生きることはできません。 1つのイベントの結果のいくつかは、2番目のイベントの結果の確率に影響します。 対照的に、互いに関係のない2人の見知らぬ人にとって、同じ年齢まで生き残ることは独立した出来事です。 もちろん、世界のすべてが相互に接続されており、そのような人々のいくつかのペアについては依然依存がありますが、実際にはそれは無視されなければなりません。
そのため、一般的な場合のサービスに対する同じユーザーのアクションは、 独立したイベントではありません 。 私に近い例から、次のようなものを常に検索する人がいるとします。
カラシニコフアサルトライフルPrice
カラシニコフ突撃銃を購入する
買う本当のカラシニコフ
カラシニコフ突撃銃
キラーを雇う
たとえば、各リクエストのクリックの事実(放棄率、検索の前日ですが、何らかの理由で必要な場合など)を考慮すると、上記の例のようなユーザーでもクリックしない可能性が高くなります以前のリクエストの発行から来た文書によると。 まあ、そうでなければ、彼はそのようなリクエストを直接設定した場合よりも低い確率でクリックします。 そしてもちろん、彼は以前の結果についてではないとしても、直接彼に尋ねたことはなかっただろう。 彼は、「レイアウトではない」と言うことは、レイアウトを得るための確実な保証であることに特に怒っていますが、彼はこれを理解していません。
私は、誰もが望んでいる人なら誰でも、1人のユーザーからではなく、数桁の平均を取る他のメトリックを思い付くと確信しています。 新しいメトリックを作成し、依存関係の要素があることに気付かないようにするのは非常に簡単です。 そのため、このような状況では、コントロールが有意のしきい値を設定するはずであるよりもはるかに頻繁に機能し始めます。 これは間違いなく、a / b実験が偶然にうまくいくことを意味し、その結果に基づいて決定を下すことは危険です。
まとめると
恒久的なa / a実験(または複数の実験)と、実施するa / b実験に同じ量のユーザーを割り当てることをお勧めします。 蓄積された統計に従うと、ユーザー実験の結果を実行および計算するシステムで発生するいくつかの問題に気付くのに役立ちます。 コントロール実験では、平均して、与えられたレベルの有意性を与えるよりも頻繁に勝者を特定するべきではありません。 20、2、3個のうち1回の実験ではなく、体系的に機能することがわかった場合、これは考える機会です。 このような監視は万能薬ではないため、そこで壊れる可能性のあるすべてが見えるわけではありませんが、間違いなく有用です。