あなたのことは知りませんが、RSSの「もっと読む>」という碑文にひどく悩まされています。 私はこの問題を解決することにしました(多分、私はFuturikoの正当な怒りを引き起こすでしょうが、正式にはルールに対応する禁止はありません)。
RSSを取得

ここはアドレスwww.habrahabr.ru/rss/mainであると思われます。 実際、Y!PはUTF8エンコーディングでのみRSSを理解します。 これを修正するには、すばらしいxmliconvサービスを使用します。 それを使用するのは非常に簡単です: william.cswiz.org/tool/xmliconv/?ie = encoding &url = url 。 この場合、RSSはwilliam.cswiz.org/tool/xmliconv/?ie=cp1251&url=http://habrahabr.ru/rss/mainで取得します。
ダウンロードページ
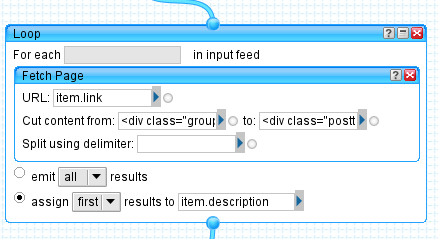
ここには2つのブロックがあります。external-すべての要素をループし、内部実行の結果がitem.descriptionに割り当てられます 。 内部ブロックはitem.linkのページを取得し 、 <div class = "groups_topic_text">と<div class = "posttags">の間のコンテンツのみを残します。 指定されたタグの間に、ページのメインコンテンツが配置されます。 Fetchページは配列を返すので(3番目の要素を入力すると、複数の要素が返されます)、 assign first resultsを設定します 。つまり、 item.descriptionは配列の最初の要素の値を取ります。
名前を変更

実際、 item.descriptionはまだ文字列ではありません。 文字列はitem.description.contentです。 つまり、 item.description.contentの名前をitem.descriptionに変更します (descriptionはRSSリーダーに表示される要素です)。
終わり

結果を出力に送信します。
このような簡単な方法で、RSSと静的ページを処理して、非常に興味深い結果を得ることができます。 ここで私のパイプを見つけることができ、 ここにそのRSSがあります。 おそらく、常に機能するとは限りません。 問題がある場合はお知らせください。 安定性は、Yahoo、William(xmliconv)およびFuturikoの信用に依存します。