かつて、メデューサのニュースを読んでいると、FacebookとVKontakteで好きなものの割合が違うということに気づきました。 fbで大人気のニュースもあれば、VKontakteでのみ共有しているニュースもあります。 これらのデータを見て、それらの中から興味深いパターンを見つけたいと思いました。 katの下で私が招待する利害関係者!
データスクレイピング
最初のステップは、分析用のデータを取得することです。 Python + BeautifulSoupの素早い発見を期待して、ページのソースコードを読み始めました。 失望は非常に早く待っていました。このデータはすぐにhtmlでロードされるのではなく、延期されます。 私はJavaScriptを知らないので、ページのネットワーク接続に足を探し始め、すぐに素晴らしいクラゲAPIハンドルに出会いました。
https://meduza.io/api/v3/social?links=["shapito/2016/05/03/poliem-vse-kislotoy-i-votknem-provod-v-rozetku"]
ハンドルは素敵なjsonを返します。

そしてもちろん、 links
は配列なので、すぐに複数のレコードを一度に置き換えてみたいと思いlinks
そして、私たちは興味のあるリストを取得します。
何も解析する必要さえありませんでした!
次に、ニュース自体に関するデータを取得します。 ここで、彼が別のペンを見つけた記事について 、sirekanyan habrozhitelに感謝したいと思います。
https://meduza.io/api/v3/search?chrono=news&page=0&per_page=10&locale=ru
per_page
パラメーターの最大値が30であり、執筆時点で約752 page
ことを実験的に確立することができました。 social
ペンが30のドキュメントすべてに耐えるという重要なチェックが成功します。
アンロードするだけです! シンプルなpythonスクリプトを使用しました
stream = 'https://meduza.io/api/v3/search?chrono=news&page={page}&per_page=30&locale=ru' social = 'https://meduza.io/api/v3/social' user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.3411.123 YaBrowser/16.2.0.2314 Safari/537.36' headers = {'User-Agent' : user_agent } def get_page_data(page): # ans = requests.get(stream.format(page = page), headers=headers).json() # ans_social = requests.get(social, params = {'links' : json.dumps(ans['collection'])}, headers=headers).json() documents = ans['documents'] for url, data in documents.iteritems(): try: data['social'] = ans_social[url]['stats'] except KeyError: continue with open('res_dump/page{pagenum:03d}_{timestamp}.json'.format( pagenum = page, timestamp = int(time.time()) ), 'wb') as f: json.dump(documents, f, indent=2)
念のため、有効なUser-Agentを置き換えましたが、これがなければすべてが機能します。
さらに、前の同僚であるalexkukuのスクリプトは、プロセスの並列化と視覚化に本当に役立ちました。 彼の投稿でアプローチの詳細を読むことができます、彼はこの種の監視を行うことを許可しました:

データは非常に迅速にアップロードされ、10分もかからず、キャプチャもスローダウンもありませんでした。 アドオンなしで、1つのIPから4つのストリームをダウンロードしました。
データミニニング
そのため、出力では、データを含む大きなjson'kaを取得しました。 これをパンダのデータフレームに組み込み、Jupyterに変換します。
必要なデータをダウンロードします。
df = pd.read_json('database.json').T df = df.join(pd.DataFrame(df.social.to_dict()).T) df.pub_date = pd.DatetimeIndex(df.pub_date) df['trust']=df.source.apply(lambda x: x.get('trust', None) if type(x) == dict else None)
箱ひげ図を作成
df[['fb', 'tw','vk']].plot.box(logy = True);
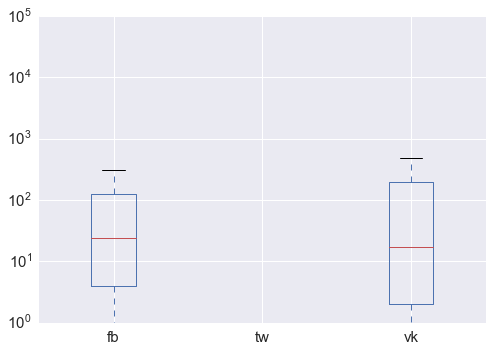
一度にいくつかの結論:
- Twitterは、ニュースをツイートしている人の数を見る機能を無効にしました。 :-(それなしでやらなければならない
- 予想どおり、分布は非常に異常です。ログスケール(数十万件の再投稿)でも顕著である非常に強い外れ値があります。
- 同時に、再投稿の平均数はかなり近いことが判明しました。中央値24と17(以下、それぞれfacebookとVKontakte)では、vkの分布はやや「不鮮明」です。
それでは、これらの再投稿されたクラゲのニュースは誰ですか? 何だと思う?
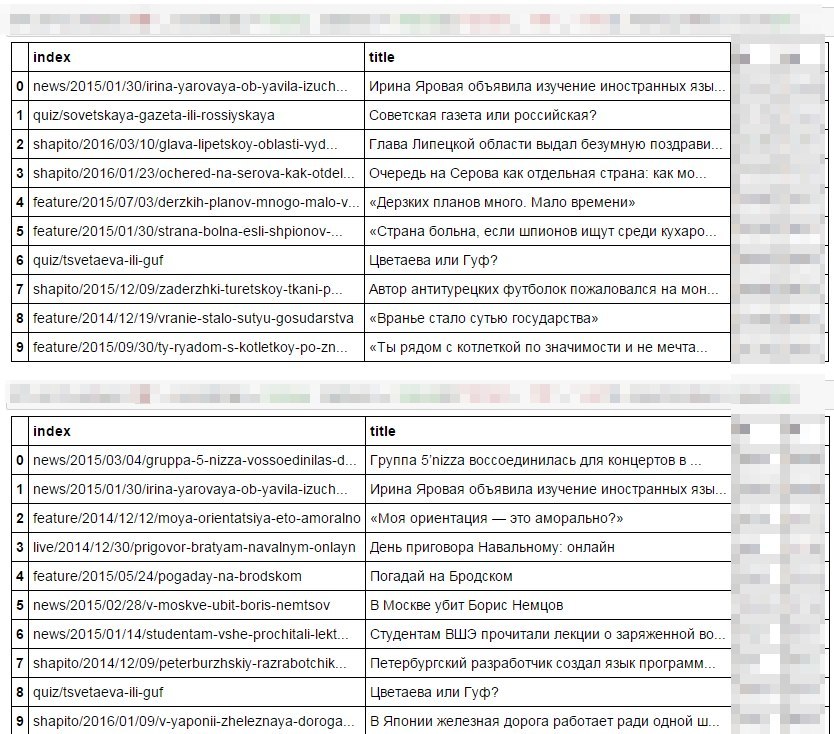
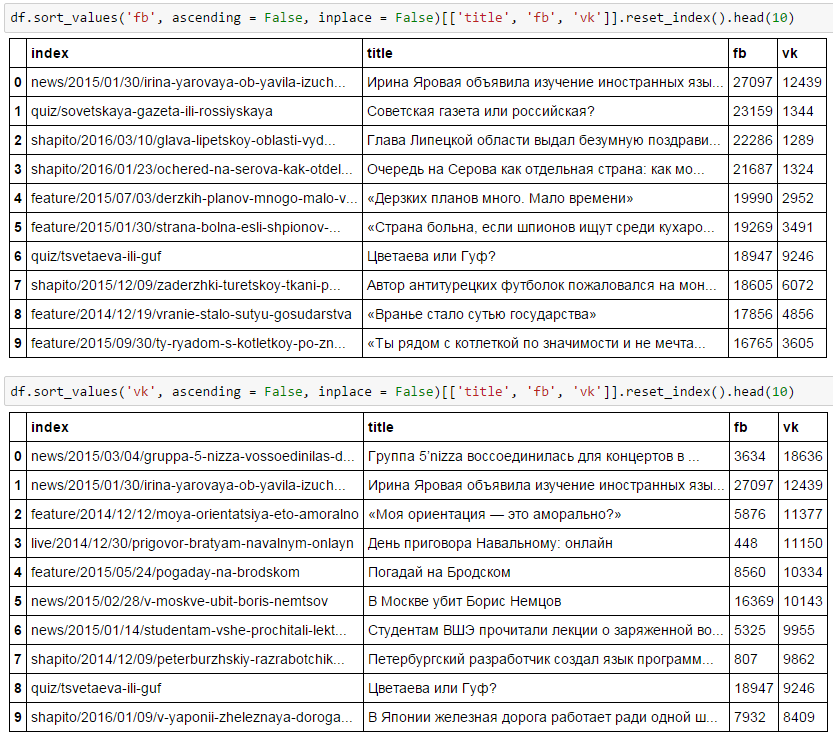
もちろん、最初はFBです。外国語、ソビエトの新聞、セロフがあります。 そして2番目の5nizzaでは、「私のオリエンテーション」、政治。 私は、すべてがとても明白だとは知りません!
2つのソーシャルネットワークの好みが似ている唯一のものは、イリーナ・ヤロバヤ、はいツベタエバとグフです。
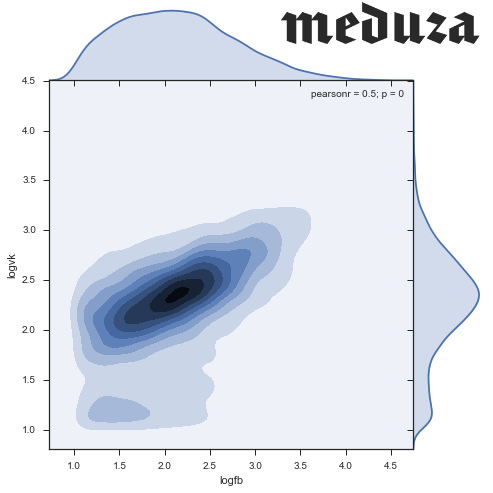
ここで、2つの量の散布図を見たいと思います。データは互いによく相関することが期待されます。
df['logvk'] = np.log10(df.vk) df['logfb'] = np.log10(df.fb) # sns.regplot('logfb', 'logvk', data = df )
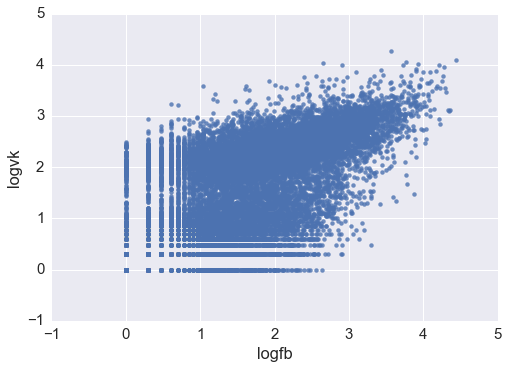
sns.set(style="ticks") sns.jointplot('logfb', 'logvk', data = df.replace([np.inf, -np.inf], np.nan).dropna(subset = ['logfb', 'logvk']), kind="hex")

2つのクラスターが表示されているようです。1つは(2.3、2.4)に中心があり、2つ目はゼロ近くに塗りつぶされています。 一般に、低頻度のニュース(ソーシャルネットワークで面白くないことが判明したニュース)でさえ分析する目的はないので、両方のネットワークで10以上のいいね!を記録することに限定しましょう。 少数の観測値を取り除いたことを確認することを忘れないでください。
stripped = df[(df.logfb > 1) & (df.logvk > 1)] print "Working with {0:.0%} of news, {1:.0%} of social network activity".format( float(len(stripped)) / len(df), float(stripped[['vk', 'fb']].sum().sum()) / df[['vk', 'fb']].sum().sum() ) # Working with 47% of news, 95% of social network activity
密度:
sns.jointplot('logfb', 'logvk', data = stripped, kind="kde", size=7, space=0)
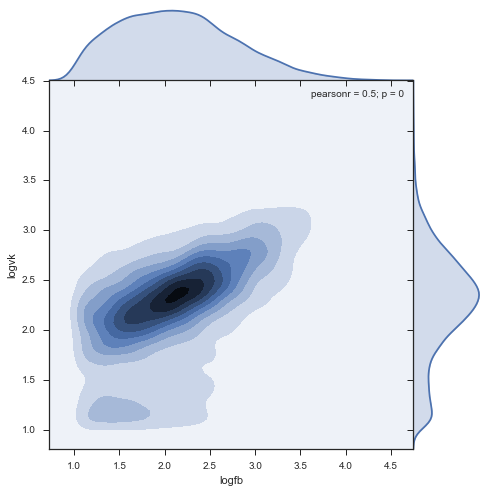
結論
- コメント率の密集したクラスターが見つかりました:Facebookで220、VKで240。
- クラスターはFacebookでさらに引っ張られます。このソーシャルネットワークでは、人々はVCよりも広範囲に再投稿します。
- 150 fbと約70 vkでFacebookアクティビティのミニクラスターがあり、非常に珍しい
次に、ダイナミクスでこの関係を確認します。変更されている可能性があります。
by_month = stripped.set_index('pub_date').groupby(pd.TimeGrouper(freq = 'MS')).agg({'fb':sum, 'vk':sum}) by_month.plot( kind = 'area')
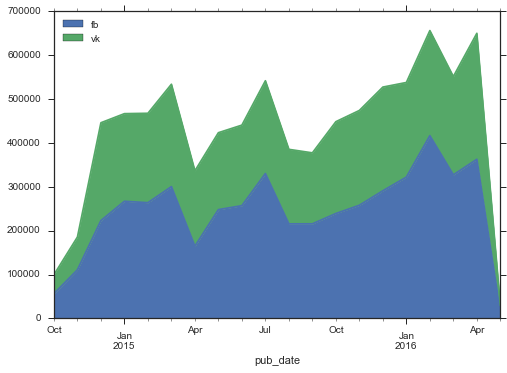
興味深いことに、ソーシャルネットワークでのアクティビティの量が一般的に増加しているため、Facebookは急速に成長しています。 さらに、メデューサで見られる爆発的な成長は見られません。 最初の数か月は、活動はかなり低かったが、2014年12月までにレベルは安定し、わずか1年後に新しい成長が始まった。
2つのソーシャルネットワークからのコメントの分布密度のダイナミクスを見てみましょう。
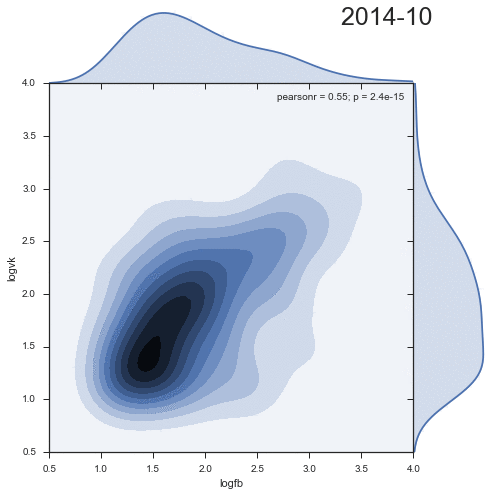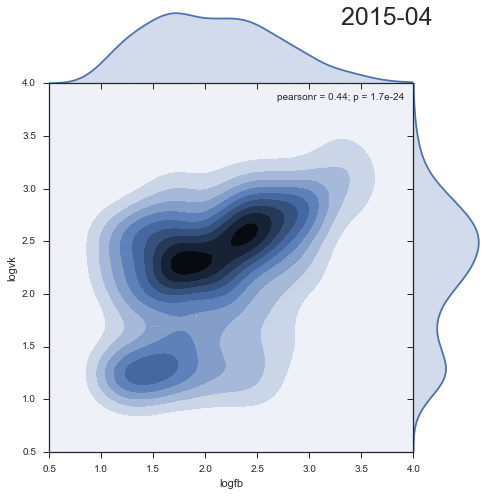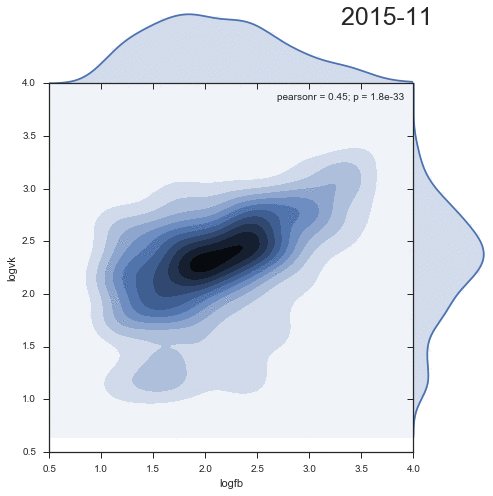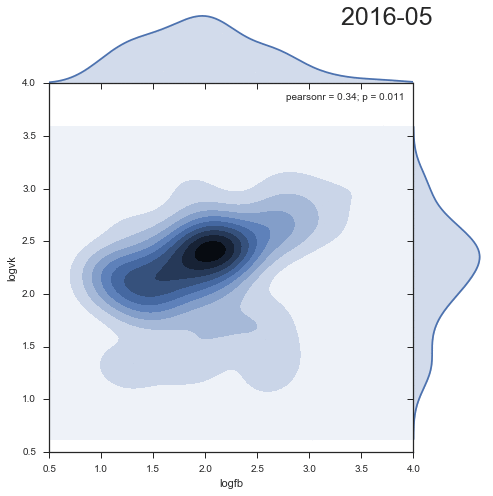
興味深いことに、2番目のクラスターは時間とともに減少し、むしろ過去の成果物です。
最後に、ドキュメントの種類によってソーシャルネットワークの比率が変わらないことを確認します。メデューサには、ニュースに加えて、カード、ストーリー、ビッグトップ、ギャラリー、トレーニンググラウンドがあります。
def hexbin(x, y, color, **kwargs): cmap = sns.light_palette(color, as_cmap=True) plt.hexbin(x, y, gridsize=20, cmap=cmap, **kwargs) g = sns.FacetGrid(stripped.loc[::-1], col="document_type", margin_titles=True, size=5, col_wrap = 3) g.map(hexbin, "logfb", "logvk", extent=[1, 4, 1, 4]);

一般に、データはクラス間で非常に均一であることが明らかであり、顕著な歪みはありません。 上位からより多くの社会活動を期待していますが、この効果は見られません。
しかし、ソースの信頼レベルによる内訳を見ると、信頼できないソースはソーシャルネットワーク、特にFacebookであまり人気がないことがわかります。

次は?
これで私の夜は終わり、私は寝ました。
- 記事タイトルからのword2vecデータの単純なRidle回帰をトレーニングしようとしました。 githubを見ると、特別な予測力はありません。 いいねの数を適切に予測するためには、少なくともニュースの全文についてモデルを教育する価値があるようです。
- これらのデータに基づいて、人々を大いに興奮させる「明るい」出来事を非常によく捕らえることができます。 同時に、fb / vk比は、ニュースの種類を予測するのに適しています。
- ソーシャルネットワークでの活動は、ニュースレターにとって出席と同じくらい重要なKPIになり得るようです。 人気のある投稿の著者/ソースを見て、これに基づいて作品を評価できます。 情報源の信頼性の対比は、この考えを支持するものです:偽のニュースはFacebookにあまり投稿されません。 何らかの形で、これはすでにジャーナリズムに適用されていると思います。