はじめに
この記事は、 Tacal the MongoDB Replica Set Oplog with Scala and Akka Streamsで公開された以前の記事の続きです。
前に説明したように、MongoDBシャードクラスターOplog更新の追跡には、レプリカセットと比較して落とし穴があります。 この記事では、トピックのいくつかの側面を明らかにしようとします。
MongoDBチームブログには、MongoDB OplogからSharded Clustersへの更新を追跡するトピック全体を網羅した非常に優れた記事があります。 次のリンクでそれらを見つけることができます:
また、 ドキュメントでMongoDBシャードクラスターに関する情報を見つけることもできます 。
この記事に記載されている例は、実稼働環境で考慮して使用しないでください。 サンプルを含むプロジェクトはgithubで入手できます。
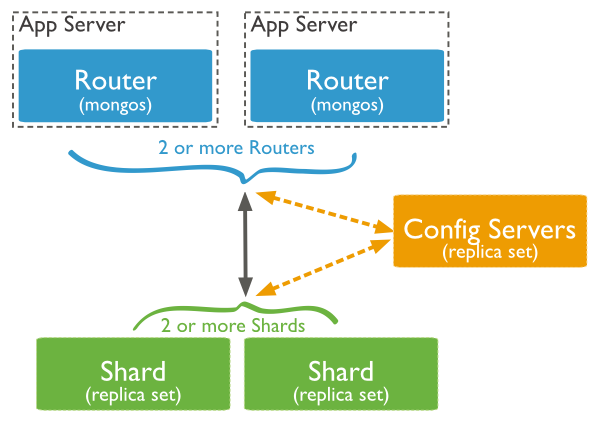
MongoDBシャードクラスター
MongoDBドキュメントから:
シャーディング 、または複数のサーバーまたはシャード上のデータの水平スケーリング、共有、および配布。 各セグメントは独立したデータベースであり、すべてのセグメントが一緒になって単一のローカルデータベースを構成します。
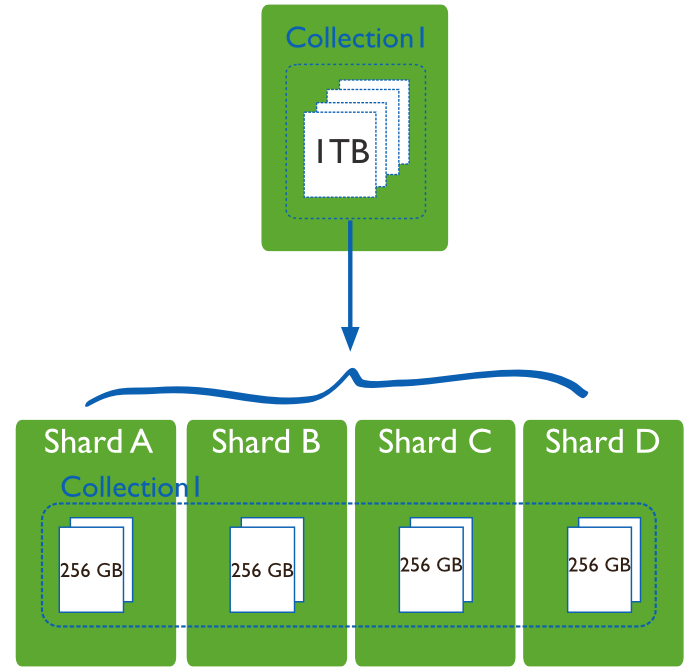
実稼働環境では、各ノードはレプリカセットです。
MongoDB内部操作
複数のセグメントにデータが分散されているため、MongoDBにはクラスター内操作があり、これは
oplog
反映され
oplog
。 これらのドキュメントには、追加の
fromMigrate
フィールドがあります。 これらの操作に関心がない場合は、
oplog
リクエストを更新して結果から除外します。
client.getDatabase("local") .getCollection("oplog.rs") .find(and( in(MongoConstants.OPLOG_OPERATION, "i", "d", "u"), exists("fromMigrate", false))) .cursorType(CursorType.TailableAwait) .noCursorTimeout(true)
ノードに関する情報を取得する
おそらく既に推測したように、
oplog
からSharded Clusterへの更新を監視するには
oplog
各ノード(レプリカセット)の
oplog
を監視する必要があります。
これを行うには、使用可能なすべてのセグメントのリストを構成データベースから要求できます。 コレクション内のドキュメントは次のようになります。
{ "_id" : "shard01", "host" : "shard01/localhost:27018,localhost:27019,localhost:27020" }
Document
オブジェクトの代わりに
case
クラスを使用することを好むため、クラスを宣言します。
case class Shard(name: String, uri: String)
Document
を
Shard
に変換する関数:
def parseShardInformation(item: Document): Shard = { val document = item.toBsonDocument val shardId = document.getString("_id").getValue val serversDefinition = document.getString("host").getValue val servers = if (serversDefinition.contains("/")) serversDefinition.substring(serversDefinition.indexOf('/') + 1) else serversDefinition Shard(shardId, "mongodb://" + servers) }
これでリクエストを行うことができます:
val shards = client.getDatabase("config") .getCollection("shards") .find() .map(parseShardInformation)
最終的に、MongoDBシャードクラスターのすべてのセグメントのリストが作成されます。
各ノードのソース宣言
Source
を示すには、セグメントのリストをたどって、前の記事のメソッドを使用するだけです。
def source(client: MongoClient): Source[Document, NotUsed] = { val observable = client.getDatabase("local") .getCollection("oplog.rs") .find(and( in("op", "i", "d", "u"), exists("fromMigrate", false))) .cursorType(CursorType.TailableAwait) .noCursorTimeout(true) Source.fromPublisher(observable) } val sources = shards.map({ shard => val client = MongoClient(shard.uri) source(client) })
すべてを管理する1つのソース
各
Source
個別に処理できますが、もちろん、それらを単一の
Source
として使用する方がはるかに簡単で便利です。 これを行うには、それらを結合する必要があります。
Akka Streamsには、いくつかの
Fan-in
操作があります。
- マージ[入力] -(N入力ストリーム、1出力ストリーム)着信ストリームから要素をランダムに選択し、それらを一度に1つずつ出力ストリームに送信します。
- MergePreferred [In]-Mergeと似ていますが、優先ストリームで要素が利用可能な場合、そこから要素を選択します。そうでない場合は、** Mergeと同じ原則で選択します
- ZipWith [A、B、...、Out] -(N個の入力ストリーム、1個の出力ストリーム)は、N個の入力ストリームから関数を受け取り、各着信ストリームの要素に対して1つの要素を出力ストリームに返します。
- Zip [A、B] -(2つの入力ストリーム、1つの出力ストリーム)は、ストリームAおよびBの要素をペア値のストリーム(A、B)に接続するように設計されたZipWithと同じです。
- Concat [A] -(2つの入力ストリーム、1つの出力ストリーム)2つのストリームを接続します(最初のストリームから要素を送信し、次に2番目のストリームから要素を送信します)
Mergeには簡易APIを使用し、ストリームのすべての要素を
STDOUT
出力し
STDOUT
。
val allShards: Source[Document, NotUsed] = sources.foldLeft(Source.empty[Document]) { (prev, current) => Source.combine(prev, current)(Merge(_)) } allShards.runForeach(println)
エラー処理-切り替えとクラッシュロールバック
Akka Streamsは、 監視戦略を使用してエラーを処理します。 一般に、エラーを処理するには3つの異なる方法があります。
- 停止 -ストリームはエラーで終了します。
- 再開 -エラーのある要素はスキップされ、ストリーム処理が続行されます。
- 再起動 -エラー要素はスキップされ、現在のステージがリロードされた後、ストリームの処理が続行されます。 ステージを再起動すると、蓄積されたすべてのデータが消去されます。 これは通常、新しいステージパターンを作成することで実現されます。
デフォルトでは、 停止が常に使用されます。
しかし、残念なことに、上記のすべてがコンポーネント
ActorPublisher
および
ActorSubscriber
に適用されるわけではありません。そのため、
Source
エラーが発生した場合、ストリームの処理を正しく復元することはできません。
この問題はすでにGithub#16916で説明されており、まもなく修正されることを願っています。
または、 MongoDBシャードクラスターでOplogをテーリングするための落とし穴と回避策の記事で提案されているオプションを検討することもできます。
最後に、レプリカセット内のほとんどまたはすべてのノードの更新に従う場合、まったく異なるアプローチになります。ts & h
フィールド値のペアは各トランザクションを一意に識別するため、アプリケーション側で各oplog
の結果を簡単に組み合わせて、ストリームの結果がほとんどのMongoDBノードによって返されたイベントになるようにすることができます。 このアプローチでは、ノードがプライマリであるかセカンダリであるかを心配する必要はありません。すべてのノードのoplog
するだけで、ほとんどのoplog
によって返されるすべてのイベントは有効と見なされます。 ほとんどのoplog
に存在しないイベントを受け取った場合、そのようなイベントはスキップされて破棄されます。
次のいずれかの記事でこのオプションを使用してみます。
おわりに
MongoDB Sharded Clusterで
orphan
ドキュメントを更新するトピックは取り上げませんでした。 私の場合、私は
oplog
からのすべての操作に興味があり、
_id
フィールドで
oplog
等であると考えているため、これは干渉しません。
ご覧のとおり、Akka Streamsを使用すると簡単に解決できる多くの側面がありますが、解決が難しい側面もあります。 一般的に、このライブラリには二重の印象があります。 ライブラリには、Akka Actorsのアイデアを新しいレベルに引き上げる優れたアイデアがたくさんありますが、それでも未完成に感じます。 個人的には、今のところAkka Actorsに固執します。