
この出版物は、Intelエンジニアのステンシル計算に適用される特性評価と最適化の方法論の記事の第2部の翻訳です。 前のパートでは、3D音響等方性波動方程式を解くために使用されるかなり一般的なコンピューティングカーネルの例を使用して、特定のプラットフォームで任意のアルゴリズムを使用して取得できる最大パフォーマンスを推定する方法について説明しました。 このパートでは、パフォーマンスがほぼ期待できるようにソースコードを最適化する一連の手順について説明します。
次のパートでは、自動チューニングの遺伝的アルゴリズムについて説明します。これにより、最適な起動およびコンパイルパラメーターを選択することで、実装のパフォーマンスを向上させることができます。
標準的な最適化
標準最適化とは、データの並列性、ベクトル化、および局所性を改善することを目的とした最適化です。 これらの3つの領域は、最新のマルチコアアーキテクチャの最適化の最も重要な側面を反映しています。 次のステップごとに実装しました。
dev00:結果を検証するための3D音響等方性波動方程式ソリューションの標準実装。
dev01:dev00実装では、領域の境界でのデータアクセスエラーを回避するために、内部ループに条件分岐がありました。 AVXからは、このような遷移はマスク(VMASKMOVPD-約Translatorなどのマスクされた命令)を使用して実装されます。 したがって、サイクルの境界を変更しても2S-E5のパフォーマンスに実際の影響はありませんでしたが、Xeon Phiは2倍の加速を受けました(図7)。
dev02:キャッシュブロッキングは、キャッシュ内のミスの数を減らし、3つの新しいループのみを必要とします(図1)。 この最適化の欠点は、ブロックサイズを制御する3つの新しいパラメーターが追加されることです。
for(int bz=HALF_LENGTH; bz<n3; bz+=n3_Tblock) for(int by=HALF_LENGTH; by<n2; by+=n2_Tblock) for(int bx=HALF_LENGTH; bx<n1; bx+=n1_Tblock) { int izEnd = MIN(bz+n3_Tblock, n3); int iyEnd = MIN(by+n2_Tblock, n2); int ixEnd = MIN(n1_Tblock, n1-bx); int ix; for(int iz=bz; iz<izEnd; iz++) { for(int iy=by; iy<iyEnd; iy++) { float* next = ptr_next_base + iz*n1n2 + iy*n1 + bx; float* prev = ptr_prev_base + iz*n1n2 + iy*n1 + bx; float* vel = ptr_vel_base + iz*n1n2 + iy*n1 + bx; for(int ix=0; ix<ixEnd; ix++) { float value = 0.0; value += prev[ix]*coeff[0]; for(int ir=1; ir<=HALF_LENGTH; ir++) { value += coeff[ir] * (prev[ix + ir] + prev[ix - ir]) ; value += coeff[ir] * (prev[ix + ir*n1] + prev[ix - ir*n1]); value += coeff[ir] * (prev[ix + ir*n1n2] + prev[ix - ir*n1n2]); } next[ix] = 2.0f* prev[ix] - next[ix] + value*vel[ix]; } }}}
図1.キャッシュブロッキングを備えたコンピューティングカーネルのソースコード。
dev03:変数が各スレッドでプライベートであることを保証するために、個々の反復でだけでなく、#pragma omp parallelと#pragma omp forディレクティブを分離し、それに応じて2つのOpenMP修飾子(節)の間でプライベート変数を宣言しました。
dev04:#pragma ivdepディレクティブを使用して、ループ内の配列の要素が交差しないことをベクトライザーに伝えることができます(つまり、C / C ++コンパイラーでデフォルトで想定されるいわゆるポインターエイリアシングはありません)。 この場合のベクトル化の使用は、特別なコンパイルキー(-fno-alias)を使用するか、C / C ++プラグマまたはFortranディレクティブを使用して容易にすることもできます。
dev05:コンパイラーがベクトル化されたループを報告したとしても、AVX命令セット拡張機能の使用(およびymmベクトルレジスターの使用)は非効率的です。 したがって、__assume_alignedなどのディレクティブと一緒に手動でループを展開すると(配列が整列していることをコンパイラーに伝えるため-約トランスレーター)、自動AVXベクトル化を改善できます(図2)。
__assume_aligned(ptr_next, CACHELINE_BYTES); __assume_aligned(ptr_prev, CACHELINE_BYTES); __assume_aligned(ptr_vel, CACHELINE_BYTES); #pragma ivdep for(int ix=0; ix<ixEnd; ix++) { v = prev[ix]*c0 + c1 * FINITE_ADD(ix, 1) + c1 * FINITE_ADD(ix, vertical_1) + c1 * FINITE_ADD(ix, front_1) + c2 * FINITE_ADD(ix, 2) + c2 * FINITE_ADD(ix, vertical_2) + c2 * FINITE_ADD(ix, front_2) + c3 * FINITE_ADD(ix, 3) + c3 * FINITE_ADD(ix, vertical_3) + c3 * FINITE_ADD(ix, front_3) + c4 * FINITE_ADD(ix, 4) + c4 * FINITE_ADD(ix, vertical_4) + c4 * FINITE_ADD(ix, front_4) + c5 * FINITE_ADD(ix, 5) + c5 * FINITE_ADD(ix, vertical_5) + c5 * FINITE_ADD(ix, front_5) + c6 * FINITE_ADD(ix, 6) + c6 * FINITE_ADD(ix, vertical_6) + c6 * FINITE_ADD(ix, front_6) + c7 * FINITE_ADD(ix, 7) + c7 * FINITE_ADD(ix, vertical_7) + c7 * FINITE_ADD(ix, front_7) + c8 * FINITE_ADD(ix, 8) + c8 * FINITE_ADD(ix, vertical_8) + c8 * FINITE_ADD(ix, front_8) next[ix] = 2.0f* prev[ix] - next[ix] + v*vel[ix]; }
図2.最適化dev04およびdev05を使用したカーネルソースコードの計算 ここで、FINITE_ADDはタイプv [ix + off] + v [ix-off]の対称有限差分(FD)のマクロです。
dev06:FD係数(c1、c2、...)の因数分解により、各係数の2つの乗算演算を削除できます。 2S-E5では、乗算と加算の不均衡が増加するため、この変更によりパフォーマンスが低下する可能性があります。 ただし、Xeon Phiのインオーダーマイクロアーキテクチャでは、「冗長な」命令を削除すると、パフォーマンスの向上に直接的な影響があります(図7を参照)。
dev07:一貫性のないメモリアクセスは、マルチソケットプラットフォームでの既知の影響です。 現在のオペレーティングシステムでは、一般的なメモリ割り当て(たとえば、mm_mallocを使用)が必要なスペースを予約しますが、物理的にメモリは変数への最初の書き込み/読み取り時に割り当てられます。 このルール(いわゆるファーストタッチポリシー)とスレッドの固定(明確に定義されたスレッドまたはプロセスのアフィニティ化)により、開発者は、将来の計算でスレッドがこれらのメモリページを使用する同じNUMAノードにメモリページを物理的に割り当てることができます。 これは、並列領域内の最初の初期化中にデータを配置することで実現され、将来的にはデータが計算に使用されます。
dev08:レジスタの最適な使用のために、この実装はC / C ++機能を使用して、特定のプロセッサアーキテクチャに固有の組み込み関数をサポートします。 このアプローチの明らかな欠点は、選択された一連の命令のみの実装の複雑さと操作性です。 ただし、Cマクロのおかげで、図5に示すようにコードは読みやすくなっています。この最適化は、図9に示すように、2S-E5よりもXeon Phiに大きな影響を与えます。 32ビット変数の右シフト(単精度)。 したがって、図4および5に示すように、わずか3回のダウンロードで、1つのベクトルについて可能な限り高速な次元の最終要素を計算できます。
#pragma ivdep for(TYPE_INTEGER ix=0;ix<ixEnd; ix+=SIMD_STEP){ SHIFT_MULT_INIT SHIFT_MULT_INTR(1) SHIFT_MULT_INTR(2) SHIFT_MULT_INTR(3) SHIFT_MULT_INTR(4) SHIFT_MULT_INTR(5) SHIFT_MULT_INTR(6) SHIFT_MULT_INTR(7) SHIFT_MULT_INTR(8) MUL_COEFF_INTR(vertical_1, front_1, coeffVec[1]) MUL_COEFF_INTR(vertical_2, front_2, coeffVec[2]) MUL_COEFF_INTR(vertical_3, front_3, coeffVec[3]) MUL_COEFF_INTR(vertical_4, front_4, coeffVec[4]) MUL_COEFF_INTR(vertical_5, front_5, coeffVec[5]) MUL_COEFF_INTR(vertical_6, front_6, coeffVec[6]) MUL_COEFF_INTR(vertical_7, front_7, coeffVec[7]) MUL_COEFF_INTR(vertical_8, front_8, coeffVec[8]) REFRESH_NEXT_INTR }
図3. dev08の組み込み関数を含むマクロを使用した計算コアのソースコード。
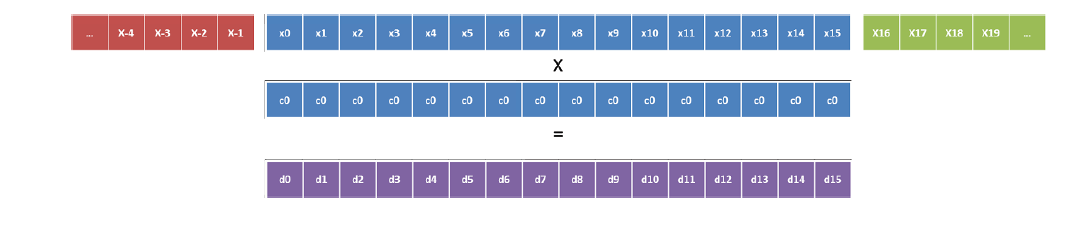
図4. Xeon Phiの最速次元によるベクトル化(係数c0)。

図5. Xeon Phiの最速次元によるベクトル化(係数c1)。
現在、AVX2命令を使用して、新しいアーキテクチャに同等の最適化を実装する可能性を調査しています(記事の発行時-約Translator)Intel Xeon E5 2600 v3。 他の2次元については、ベクトル化がより簡単です。 1つの係数に対して4回のダウンロードが必要なだけで、ベクトルが合計されてこの係数が乗算されます(図6)。 これは、マクロMUL_COEFF_INTRの一部として実装されます。
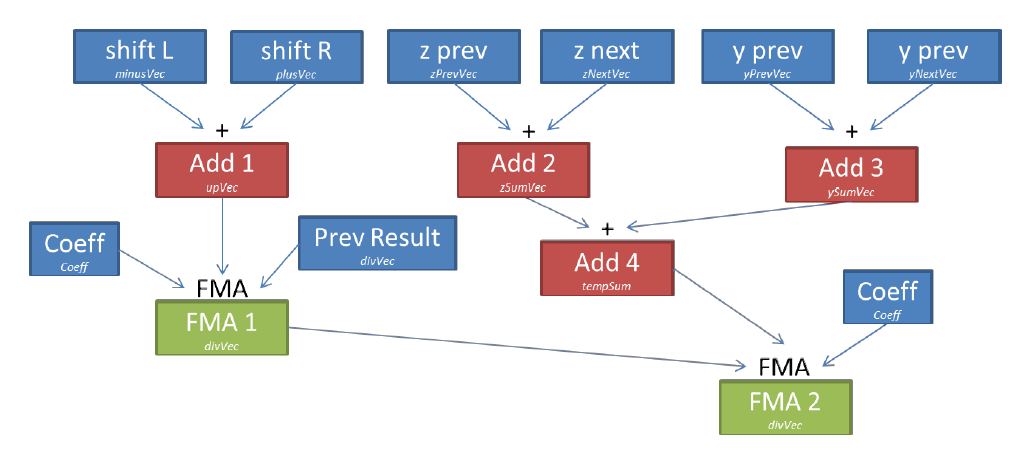
図6. dev08での単一係数の操作。

図7. Xeon PhiのECCオフ/ターボオンおよびIvy BridgeのターボオンでのGFlop / sのパフォーマンス
dev09:Xeon Phiでは、一時変数の数を減らすことができるため、FMA命令(融合乗算加算)を使用して、必要なレジスターの数を減らすことができます(いわゆるレジスター圧と呼ばれる、流出/フィルレジスターになります-約トランスレーター)。 係数はすべての計算中に同じレジスタに書き込むことができ(6 FMA)、各FMA命令の結果は次の計算セットに直接使用され、レジスタ間のデータ移動を制限します(図8)。
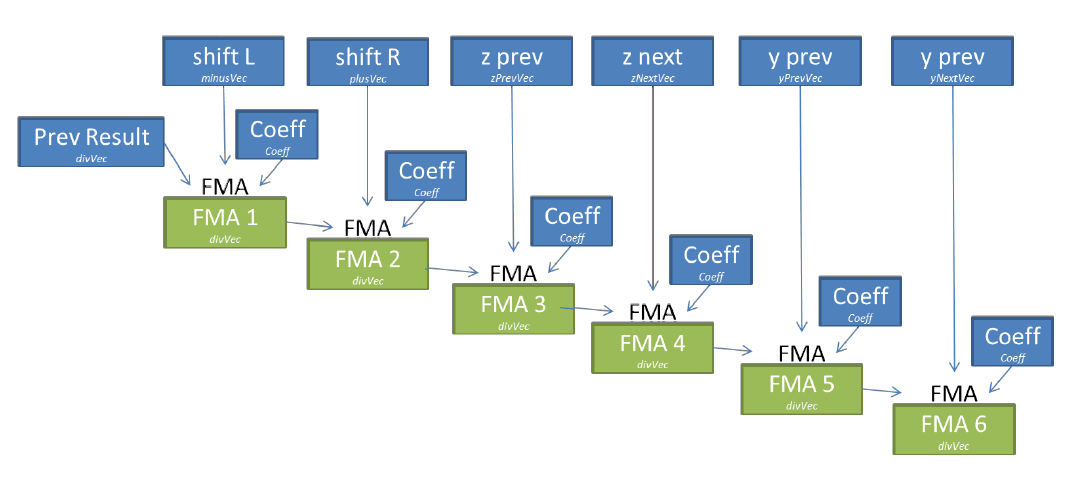
図8. dev09での1つの係数の操作。

図9. 2S-E5 Ivy BridgeおよびXeon Phiでのさまざまなバージョンのパフォーマンス。 遺伝的自動調整アルゴリズムを適用した後、dev09の最も最適化されたバージョンも改善されました。
続行するには...