についての記事は何ですか?
この記事では、Simpsonパラドックスの最も有名な例の1つを検討しながら、PandasのMultiIndexについて少し説明します。
まず最初に。
シンプソンのパラドックスは、各データグループに特定の依存関係がある場合、統計の直観に反する現象ですが、これらのグループを組み合わせると、依存関係は消滅するか、逆になります。 たとえば、さまざまなレベルの教育を受けた2000年から2012年までの25歳以上のフルタイム労働者の平均所得の変化を見ると、次の数値が得られます(すべての計算はインフレに合わせて調整されています)。
- 9年生未満 -3.7%
- 9〜12 日で終了しませんでした -6.7%
- 高校卒業 -3.3%
- 大学はあるが学位はない -3.7%
- 準学士号 -10.0%
- 学士号以上 -2.7%
これらの数値に基づいて、12年間で女性の収入が減少したと結論付けることができます。 ただし、実際には、フルタイムの女性の平均収入は2.8%増加しました(この例の詳細については、 こちらをご覧ください )。
シンプソンパラドックスの最も有名な例の1つは、カリフォルニア大学バークレー校に入学する際の性差別の事例です。 さらに検討します。
UCバークレーケース
一般統計
大学に受け入れられた男女の割合を計算します(ソースデータはwikiにあり 、すべてのコードはgithubにあります )。
import pandas as pd flat_df = pd.read_csv('berkeley_case.csv', sep = ';') total_stats = pd.pivot_table(flat_df, aggfunc = sum, index = 'gender', columns = 'param', values = 'number') total_stats['perc_admitted'] = map(round_2digits, 100*total_stats.accepted/total_stats.applied)
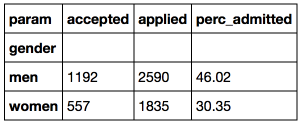
申請書を提出した男性の46%と女性の30%のみが受け取ったことがわかります。 ポイントの16%は十分に大きな差であり、これが単なるランダムな偏差である可能性は低いです。 この点で、1976年に、性差別を理由にバークレーに対して訴訟が提起されました。
ただし、データをもう少し詳しく掘り下げ、教員が受け入れた男女の割合を調べます。
教員による志願者の割合
これが、パンダのMultiIndexまたは階層インデックスが便利な場所です。 階層インデックスは、高次元のデータを表形式化し、ループを回避できるかなり便利な機能です(私の意見では、Pandasコードはループなしでより有機的に見えますが、これはもちろん上品です)。 階層インデックスを使用してDataFrameを作成する最もわかりやすい方法は、 pivot_table関数を使用することです(Excelのピボットテーブルと同様)。
df = pd.pivot_table(flat_df, index = 'faculty', values = 'number', columns = ['gender', 'param'])
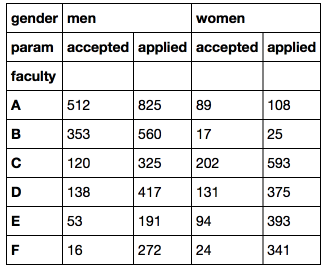
さまざまな方法で階層インデックスを使用してDataFrameをフィルタリングできます(詳細については、 ドキュメントを参照してください)
df['men']['accepted'] # df df['men'] # (level = 0) # , accepted idx = pd.IndexSlice df.loc[idx[:], idx[:, 'accepted']]
また、大学への応募者と応募者の総数を計算し、元のDataFrameにスライス「合計」を追加しましょう。
df_total = (df['men'] + df['women']).T # dataframe df_total['gender'] = 'total' df_total.set_index('gender', append = True, inplace = True) # df_total = df_total.reorder_levels(['gender', 'param']).T # df = pd.concat([df, df_total], axis = 1) # df
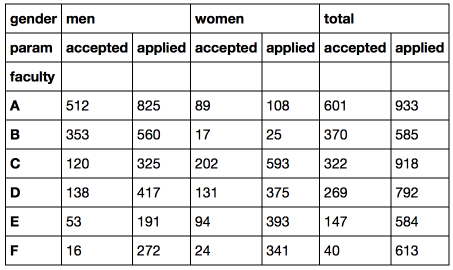
これで、男性、女性、一般の入場率を簡単に計算できます。
df_inv = df.reorder_levels(['param', 'gender'], axis = 1).sort_index(level = 0, axis = 1) # admitted_perc = (100*df_inv.accepted/df_inv.applied) admitted_perc[['total', 'men', 'women']].plot(kind = 'bar', title = 'Percentage of admitted to UC Berkeley')
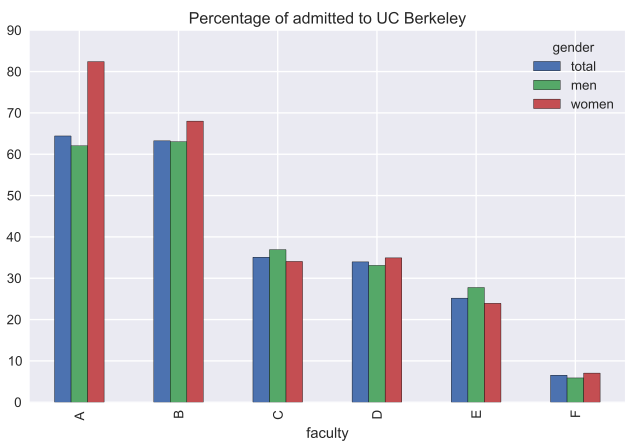
判明したように、ほとんどの学部では、入学する女性の割合は男性よりも高くなっています(学部Aでは、女性に有利な差は約20%です)。 学部CおよびEでは、登録されている女性の割合は少ないが、有意ではない。 したがって、女性に対する性差別の仮説は支持されません。 このパラドックスを理解するために、どの学部が男性と女性に応募したかを考えてみましょう。
男女間の学部の人気
異なる学部の男女のアプリケーションの分布を計算し、これをこの学部で受け取った平均パーセンテージと比較しましょう。
gender_faculty_applications = pd.pivot_table(flat_df[flat_df.param == 'applied'], index = 'faculty', values = 'number', columns = 'gender') gender_faculty_applications = gender_faculty_applications.apply(lambda x: 100*x/gender_faculty_applications.sum(), axis = 1) gender_faculty_applications.columns += '_faculty_share' faculty_stats = admitted_perc[['total']].join(gender_faculty_applications) faculty_stats.columns = ['total_perc_admitted', 'men_faculty_share', 'women_faculty_share'] faculty_stats.plot(kind = 'bar', title = 'Statistics on UC Berkeley faculties')
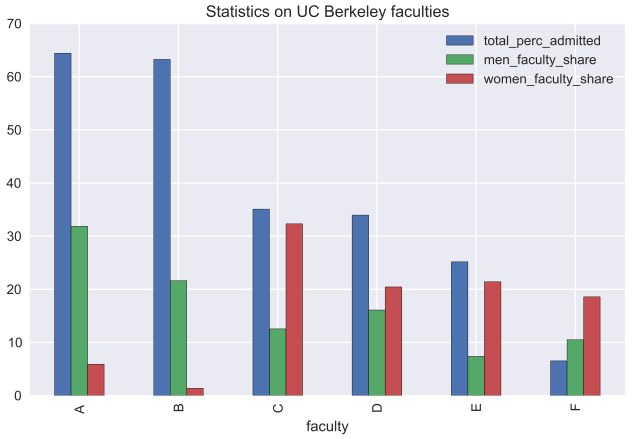
パラドックスの説明は次のとおりです。ほとんどの男性(50%以上)がAとBの学部に応募し、応募者の割合が高いのに対し、ほとんどの女性はより「複雑な」学部に入ることを決めました。
結論として
シンプソンのパラドックスの例を調べて、オブジェクトの個々のグループに関する結論をこれらのグループの結合に転送できない理由を見つけました。
さらに、パンダの階層インデックスに精通しました。これにより、場合によっては、サイクルを回避し、多次元データの操作を簡素化できます。
興味のある方は、 この記事をご覧になることをお勧めします。シンプソンのパラドックスを説明するインタラクティブな視覚化を見つけることができます。