
Habréのブログでは、取引ロボットの開発とオンライン取引のためのインフラストラクチャの構築について多くのことを書いています。 以前の資料では、 FPGAとGPUの使用に関するトピックを検討しましたが、今日は、Xeon Phiコプロセッサーを使用した取引アプリケーションの作成に焦点を当てます。
現代の証券取引所は、特別なフィードハンドラーを使用して、市場の状況に関する情報をブロードキャストします。このフィードハンドラーには、株価と購入および販売の注文に関する情報が含まれています。 アプリケーションの数と取引される金融商品の数の増加に伴い、取引システムのパフォーマンスも劇的に向上するはずです。そうでなければ、取引の遅延は避けられず、しばしば受け入れられません。
さらに、多くの交換は、マルチキャストブロードキャストやTCP / IPを介したポイントツーポイント送信など、さまざまな形式でデータをブロードキャストします。 プロプライエタリな金融プロトコルでの作業の複雑さは、場合によっては金融会社や民間のHFTトレーダーが金融データフロー用に独自のソフトウェアプロセッサを開発するのではなく、商用ハードウェアソリューションを使用してアプリケーションのパフォーマンスを向上させることを好むという事実につながります。
取引アプリケーションを構築するには、2つのアプローチがあります。 1つ目は「一般」として説明できます。この場合、ソリューションは、Intel Xeonなどの一般的に使用されるプロセッサやLinuxなどの標準OSで実行されるソフトウェアアプリケーションで構成されます。 2つ目のアプローチでは、FPGAまたはASICを使用して「カスタマイズされた」ソリューションを作成します。これにより、財務データを非常に高速に処理できます。 2番目の方法は、ソリューションの開発とサポートのコストが増加することも特徴です。
金融市場で働くための高性能ソリューションの重要な側面は、処理ソフトウェアによって導入される遅延の量でもあります。 HFTの世界では、マイクロ秒の遅延でさえ取引を不採算にする可能性があります。 プロセッサの遅延は、プロセッサに割り当てることができるコアの数に依存します。通常、トレーディング操作を実行するハードウェアにもハードウェアリソースが必要なため、プロセッサの数はそれほど大きくありません。 Xeon Phiコプロセッサーを使用すると、受信速度に匹敵する速度でデータを処理できるため、挿入遅延を削減する問題を解決できます。
パッケージ処理アーキテクチャ
Intex Xeon Phiコプロセッサを使用すると、非常に高いレベルの同時実行性を持つアプリケーションを作成できます。 コンピューティングプラットフォームは、次のコンポーネントで構成されています。
- 最適なシステムパフォーマンスのために多数の独立したデータストリームを処理する多数のシーケンシャルキャッシュコアとスレッド。
- より狭いMMX、SSEまたはAVX2を使用する代わりに、512ビットのベクトルを使用するSIMDサポート。
- 平方根、指数、戻り値を計算するための高性能命令のサポート。
- メモリーに使用可能な大量の帯域幅。
- 高性能通信ツール-レシーバーへ、ホストと接続されたコプロセッサー間のPCIバス。
その結果、ホストマシン上の1つ以上のストリームは、標準ネットワーク機器(NIC)を使用した外部ソースからのソケット接続を介して、パケット(これは市場データである可能性があります)を受信します。 ホストは、さらに処理するためにパケットからFIFOキューを形成します。 コアで実行されるコプロセッサー側の関連スレッドは、FIFOを介して受信した各パケットを処理し、各パケットをフロー処理アルゴリズムに渡します。 その後、彼の作業の結果がFIFOに再度コピーされ、さらに処理されます。
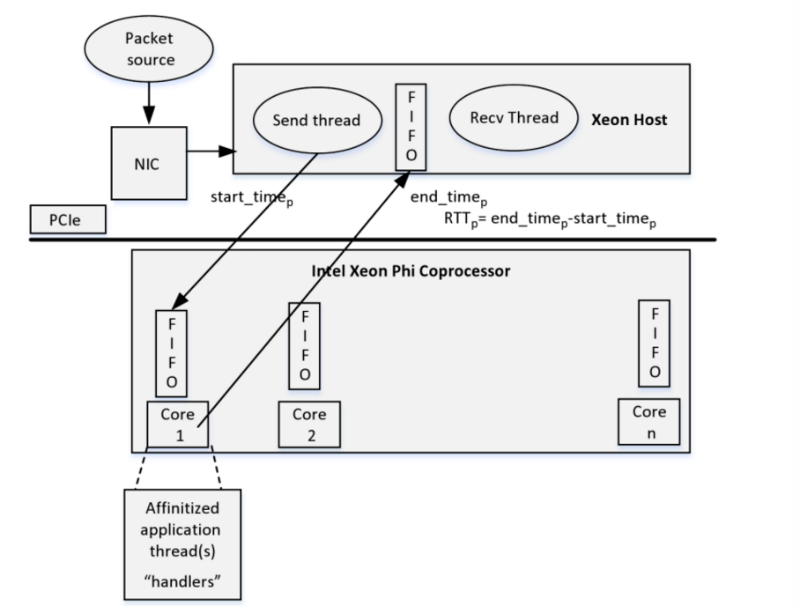
コプロセッサを使用したパケット処理アプリケーションのアーキテクチャ
2つの隣接するプロセス間の効果的なクロスサイト通信は、対称通信インターフェース(SCIF)を使用して実現されます。 その結果、アプリケーションはSCIF APIを使用してデータを送信します。SCIFAPIは、Berkeley Sockets APIと同様に機能します。 SCIFドライバーとライブラリは、PCIバスの両側に対称的に配置されます。接続セットアッププロセスはソケットAPIに似ており、一方は着信接続をリッスンして受信し、もう一方はリモートプロセスに接続します。
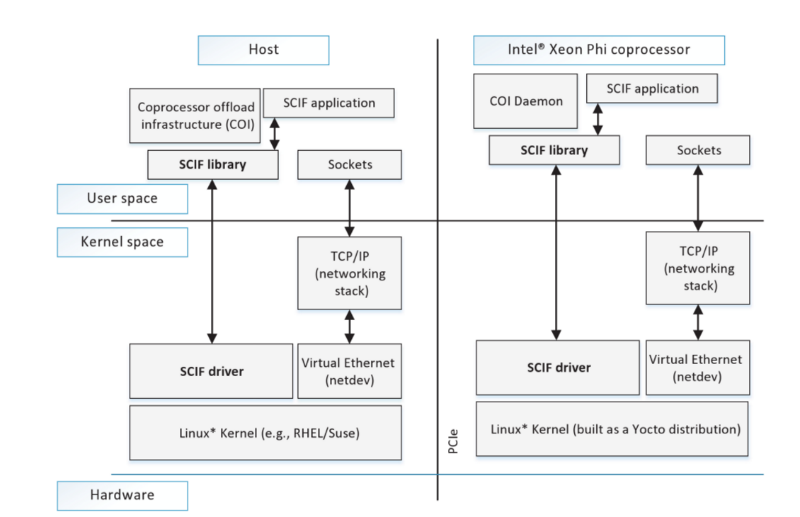
ユーザーモード用のSCIFドライバーとライブラリを含むIntelメニーコアプラットフォームソフトウェア(MPSS)スタック
Xeon Phiを使用したメモリの操作と取引アプリケーションの最適化の詳細については、「 高性能並列処理の真珠第2巻:マルチコアおよびメニーコア」を参照してください。
次に、Xeon Phiでのアプリケーションのテスト実装を調べます。
モンテカルロ法を使用したLIBOR金利スワップの計算
高頻度取引ソリューションの開発者であるXceleritは、モンテカルロ法を使用して金利スワップを処理するLIBORアプリケーションの実装の説明をブログで公開しました。 この資料のハイライトを活用します。
モンテカルロシミュレーションは、LIBORスワップポートフォリオの価値を決定するために使用されます。 その助けにより、興味のあるLIBORインディケータの開発のための数千の可能な将来のオプションがシミュレートされます-これには正規分布乱数が使用されます。 LIBORは、Mike Giles教授が説明したメカニズムを使用して、LIBORのレートとリターンを計算します。
ポートフォリオの感度は、Adjoint Algorithmic Differentiation(AD)を使用して計算されます。 ポートフォリオのスワップとギリシャ文字のギリシャの合計値は、さまざまな値の変化に対するオプションプレミアムの感度を示しています。
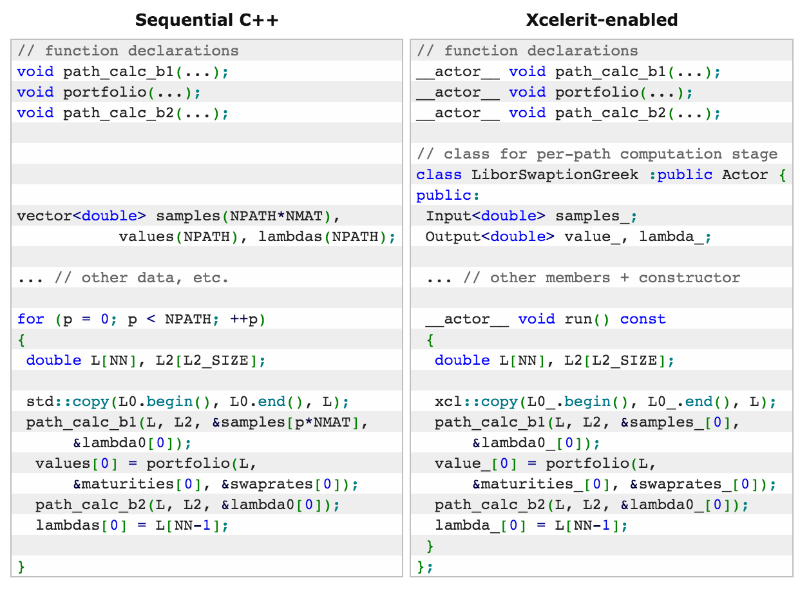
実装ではXcelerit SDKを使用します。 正規分布のランダムサンプルを取得するには、乱数ジェネレーター、LIBORレート計算モジュール、ポートフォリオ、およびギリシャ語の定義が必要です。 次に、ポートフォリオとギリシャ人の価値の最終的な識別が来ます。

次の表は、このようなアプリケーションの2つの可能な実装を比較しています。1つはシリアルC ++を使用し、2つ目はSDKを使用してXeon Phiを操作する場合です。
アプリケーションは、メインプロセッサを使用せずにネイティブXeon Phiモードを使用します。 テスト環境の構成は次のとおりです。
- CPU :Haswell Xeon E5-2697 v31(14コア、2x HT)およびXeon Phi 7120P1(61コア、4x HT)
- HT :ハイパースレッディングを有効化
- OS :RedHat Enterprise Linux 6(64ビット)
- RAM :64GB
- 開発ツール :Xcelerit SDK 3.0.0b / ICC 15.0
実験では、2つのプロセッサでのテストアプリケーションの計算時間と、Haswell CPUの同じコアでの順次実装を比較しました。 計算時間とは、上記のアルゴリズムのすべての段階の実行を意味します。

以下のグラフは、倍精度と単精度の数値について、Haswellで起動された実装の速度を比較しています。
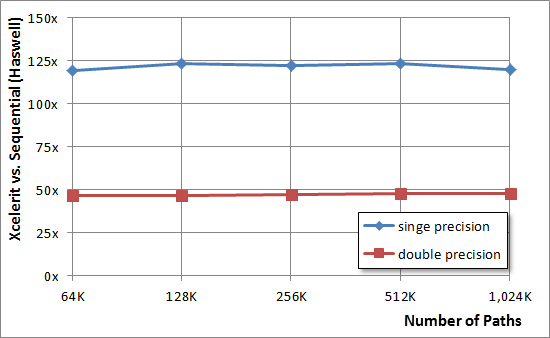
Xeon Phiを使用すると、結果は次のようになります。

前のケースで、単精度と倍精度で50倍と125倍の処理加速を達成できた場合、コプロセッサを使用して、これらの値をそれぞれ75倍と150倍に増やしました。