
最近では、モスクワ証券取引所の過去のデータに基づいて、一杯の見積もりを作成する問題を解決しました。 私はオープンソースでこのようなものを見つけられませんでした。私はゼロから始めて自分でそれを掘らなければなりませんでした。 知っておく必要のあるニュアンスがあります。 途中でそれらについて言及します。
株式取引、インフラストラクチャ、および履歴データのテストアルゴリズムについて、 IT Investは彼に感謝します。 OrderLogsデータでは、市場の深さ、流動性、スプレッドなどを分析することを自分から付け加えます。 取引アルゴリズムで結果を使用します。
ほとんどの質問があるため、株式市場を特別に選択しました。 外国為替およびデリバティブ市場には独自の特性がありますが、それはより簡単です。 Javaでのアルゴリズムの実装、 GitHubのコード。
目標:いつでも引用符を入手します。
入り口は何ですか?
Exchangeから1日で受け取ったすべての注文/取引(完全注文ログ)を含むファイル、シンプルなCSV形式、最大1 GBの容量。 形式の説明とサンプルデータは、Exchange Webサイトにあります。 ファイルのスニペットは次のとおりです。

- 紙のコード-楽器の取引コード
- 売買-売買するアプリケーションの方向
- 時間-HHMMSSZZZ形式(101738829 = 10時間17分38秒829ミリ秒)
- アプリケーションID-アプリケーションの寿命を追跡するために使用します。
- イベントのタイプ-{1-アプリケーションを受信、0-アプリケーションを削除、2-トランザクション}
- 価格-ルーブルの価格。 1枚
- ボリューム-証券数における注文/トランザクションのボリューム
- トランザクションID-イベントタイプ= 2の場合に記入
- 取引価格-イベントタイプ= 2の場合に入力
データは取引システムから直接取得されるため、「時間」フィールドは取引システムでイベントを修正する時間です。 これに注意する必要があります。 FASTを介して市場の日付を受け取る人は、データが遅れて到着します(コロケーションゾーンでの待ち時間は0.1ミリ秒)。 つまり、Exchangeデータでアルゴリズムをテストする場合、現実の時間遅延は考慮されません。 そのため、このような時間が重要でない場合は、待ち時間を「スコアリング」できます。
株式市場は9:50に始まり18:50に終了し、3つのフェーズを通過します。
09:50-10:00-オープニングオークション(開始価格が形成されます)
10:00-18:40-メインオークション
18:40-18:50-終了オークション(終了価格が形成されます)
ファイルには、「メイン入札」とオープニングオークションからの未決注文のみが含まれます。
ビルドアルゴリズム
「Orders」と「OrderBook」の2種類のオブジェクトが必要です。 注文は個別の注文です(ファイル内の行)。 OrderBookオブジェクトは、価格と数量の2つのフィールドを持つ注文集約注文です。 同じ価格ですべてのボリュームを合計します。
時点AABBCCDDDでツール「XXXX」のガラスを組み立てましょう。 最初の行から、コレクション内の紙「XXXX」に関連する注文(Ordersオブジェクト)の収集を開始します。 あるアプリケーションを購入し、別のアプリケーションを販売します。 そして、時間<= AABBCCDDDの間にすべてのアプリケーションを繰り返し処理します。
イベントタイプが1の場合(注文する)、注文の方向に応じて、注文をBuyまたはSellコレクションに追加します。
イベントタイプ= 0(アプリケーションを削除)の場合、アプリケーション番号によってコレクション内でそれを見つけて削除します。 論理的には、そうでないものを削除することは不可能だからです。 適切なアプリケーションが見つからなかった場合は、アラームを鳴らす必要があります(データ自体にエラーがあるか、自分でミスをしました)。
イベントのタイプが2(トランザクション)の場合、注文番号によってコレクション内でそれを見つけ、そのボリュームを確認します。
- V1 = V2(V1はコレクション内の注文量、V2はトランザクション量)の場合、注文はコレクションから削除されます。 これは、アプリケーションが完全に完了したことを意味します。
- V1> V2の場合、コレクションでV1のボリュームをV1-V2に変更します。 これは、アプリケーションが部分的に実行されたことを意味します。 そして、一部がグラスに残った。
- V1 <V2(はい、はい、可能です。つまり、注文のボリュームは10で、トランザクションは20で発生しました)の場合、これは注文の氷山サインです。 この場合、アプリケーションはコレクションから削除されます。
イベントタイプ= 2は常にペアになります-トランザクションの両側。 条件時間<= AABBCCDDDに違反するとすぐに、ループを終了します。 この時点で、コレクションにはAABBCCDDDの時点でアクティブなアプリケーションがすべて含まれています。 コレクションアイテムを価格で並べ替えます。 OrderBookタイプのオブジェクトを作成するときが来ました。これらは価格レベル(集約された価格ボリュームインジケータ)、つまり 引用符で見ることに慣れているもの。 すべての入札を循環し、同じ価格の入札のボリュームを合計します。 これがアルゴリズム全体です。
成行注文
成行注文の場合、価格フィールドは「0」を示します。 このようなアプリケーションも通常どおり処理されます。 それらは現時点で満たされています。
氷山アプリケーション
Icebergアプリケーションは、オーダーログにもあります。 実践が示しているように、それらを確実に識別することは不可能です。 データを生成するとき、Exchangeは独自のアルゴリズムを使用して、氷山を隠します。 それでも、場合によってはちらつきます。たとえば、ボリュームが10の注文がハングし、取引になったときに、ボリュームがすでに100になっています。
この情報を知ることは、眼鏡を収集し、スプレッドと市場の深さを分析するのに十分です。
そして今、最良の部分:実際にアルゴリズムをテストしましょう。 2016年2月2日は、ブルームバーグターミナルからグラスで特別にスクリーンショットを作成し、時間を修正しました。 彼は時間の同期の難しさを避けるために、ほとんどの液体の楽器、Yandex(YNDX)、KamAZ(KMAZ)を取りませんでした。 並行して、上記のアルゴリズムを使用して、Exchangeデータに関するグラスを収集しました。 16:56:21の結果は次のとおりです。
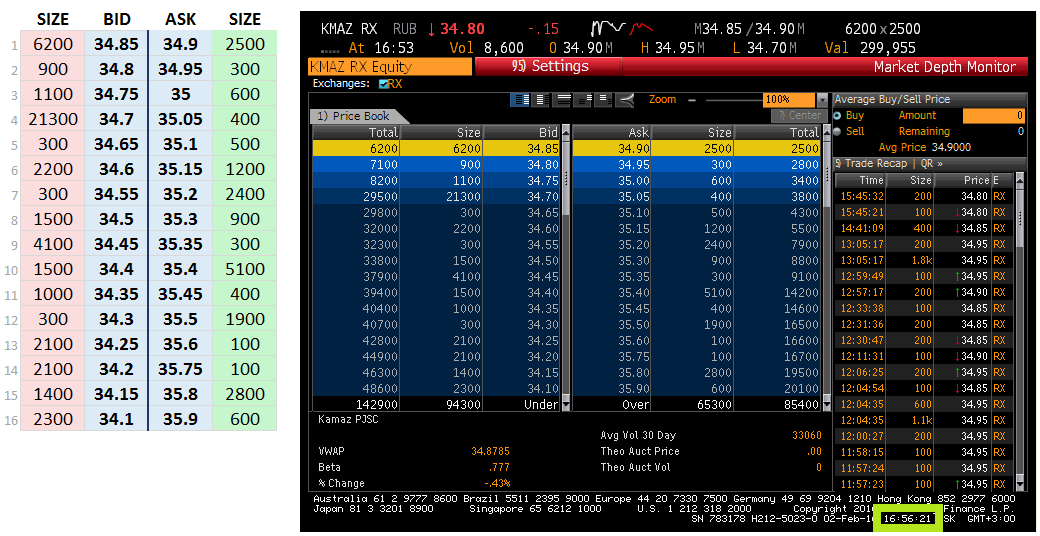
データは同一です。
速度に関するいくつかの言葉
ストリームには約1500万のレコードが含まれ、約300の楽器が含まれます。 取引全体で最も流動性の高いSBERは20秒で実行されます。 SBERの場合、1方向または別の方向のガラスの深さは500〜600の価格レベルです。 各「時間」後にガラスの状態を維持する場合、処理時間は1秒に短縮され、私にぴったりです。 また、目的の楽器を別のストリームで録音する場合、時間は10分の1秒に短縮されます。
したがって、1秒未満でいつでも任意の楽器のグラスを入手できます。 誰かがより効率的なアルゴリズムを提案できると確信しています。嬉しいです。
PS:履歴データの一部は、Exchange Webサイトで無料で取得できます。 2月2日のデータが必要な場合は、Ya.Disk(〜1Gb)にアップロードします。 教えてください。