ブログでは、適応フィルタリングアルゴリズムを使用した株価予測のテーマについて既に触れました。 ニューヨークの投資家であるVatsal Shahは、これらの目的で機械学習アルゴリズムを使用する可能性を検討しました。 このドキュメントの主な考えに注目してください。
はじめに
株価を予測するには2つの方法があります。
- 基本分析 -この場合、アナリストは、株式自体よりも株式取引所で取引されている会社に関連する情報を評価します。 市場での特定のアクションに関する決定は、会社の以前の活動の分析、収益と利益の予測などに基づいて行われます。
- テクニカル分析 -この場合、株価の振る舞いが調べられ、そのさまざまなパターンが明らかにされます(時系列の分析が使用されます)。
取引データの処理に機械学習法を使用する場合、使用されるのはより多くの場合、技術分析法です-目標は、アルゴリズムが時間の経過に伴う株式行動のパターンを正確に決定できるかどうかを理解することです。 それでも、機械学習を使用して企業の結果を評価および予測し、さらに基本的な分析に使用することができます。 最終的に、自動化された株価予測と投資推奨の生成のための最も効果的な方法は、基本的および技術的分析アプローチを組み合わせたハイブリッドアプローチです。
効果的な市場仮説
Efficient Market Hypothesis(EMH)仮説は、すべての重要な情報が証券の市場市場価値に直ちに完全に反映されることを前提としています。 市場効率には、弱、中、強の3つの形式があります。 弱い形式は、市場資産の価値が過去の情報を完全に反映することを意味し、強い形式は、価値が過去、および公共または内部のすべての情報を反映することを意味します。
ランダムウォーク仮説
ランダムウォークの数学モデル(ランダムウォーク仮説)は、各ステップでの株価の変化が以前の株価や時間に依存しないことを示唆しています。 したがって、価格行動のパターンを特定して使用することは不可能です。
インジケータ機能
市場価格のテクニカル分析には、さまざまな属性と指標が使用されます。 後者には、たとえば以下が含まれます。
- 移動平均(MA)-現在の瞬間までのn個の過去の値の平均を表示します。
- 指数移動平均(EMA)-最新の値により大きな重みを与えますが、古い値を完全には破棄しません。
- モーメンタムまたは変化率 (Rate of Change、RoC)は最も単純な技術指標の1つであり、現在の価格とn期間前の価格との比率または差として計算されます。
- 相対強度指数(RSI)-一定期間(通常9〜14日)にわたるトレンドの強度とその変化の可能性を決定します。
説明したプロジェクトでは、EMAがメインインジケータとして選択されました。これにより、時系列を使用した分析に非常に重要な履歴データをほぼ無制限に処理できます。 ただし、他の指標を使用すると、分析された株式の予測の精度が向上することに注意してください。
EMA (t) = EMA (t-1) + alpha * (Price (t) - EMA (t-1))
ここで、alpha = 2 /(N + 1)、N = 9の場合、alpha = 0.20
理論的には、株価を予測する問題は、t-1、t-2 ... tnの間のFの以前の値に基づいて、各瞬間Fに対応する重み関数wを割り当てる、時間Tにおける関数Fの推定と考えることができます。
F (t) = w1*F (t-1) + w2*F (t-2) + … + w*F (tn)
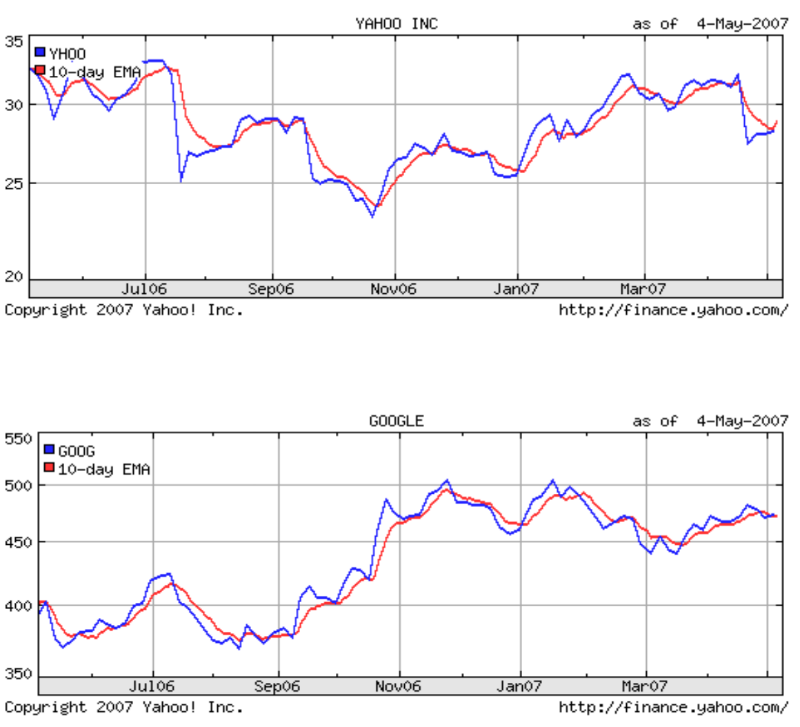
以下のチャートは、EMAが現在の株価をどのようにモデル化するかを示しています。
学習環境
プロジェクトでは、WekaとYALEのデータマイニング環境が使用されました。 設定は次のようになりました。

一部の機械学習メソッドの属性選択手順は、合計数が10未満だったためスキップされました。
履歴データの前処理
この実験では、Google Inc.の株価に関する履歴データがYahoo Financeからダウンロードされました。 (ティッカーGOOG)およびYahoo Inc. (YHOO)。 データセットには、次の属性がありました。 閉じる
EMAインジケーターは、取引の前日の株価が現在の価格で最高値になることを示唆しています。 したがって、時点が現在の瞬間に近いほど、その日の価格の値が大きくなります。 一時的な分析中に、研究者は日付をX軸として取りました-各日付は整数値でした。 別の属性が既存の属性に追加されました-インディケーター、この特定のケースではEMA。
機械学習のテクニック
このセクションでは、さまざまな機械学習アルゴリズムを適用した結果を示します。
決定切り株アルゴリズム
EMAの予測に単純なアルゴリズムを使用すると、次の結果を得ることができました。
- 相関係数0.8597
- 平均絶対誤差46.665
- Root Mean Square Error 57.8192
- 相対絶対誤差46.8704%
- 二乗平均平方根相対誤差50.9763%
- 期間の総数681
線形回帰
EMA予測に単純な線形回帰(数値属性のみを使用)を使用すると、次の結果が得られました。
- 相関係数0.9591
- 平均絶対誤差12.9115
- ルートエラールート32.0499
- 相対絶対誤差12.9684%
- 二乗平均平方根相対誤差28.2568%
- 期間の総数681
サポートベクター法
512から65536の範囲の設定パラメーターCを持つカーネルの動径基底関数を使用してサポートベクトル法(Cクラス)を使用すると、価格変動予測の以下の精度を得ることができました。
二乗平均平方根誤差:0.486±0.012
精度:60.20±0.49%
ブースティング
C-SVCアルゴリズムを使用した後、AdaBoostM1ブースティングアルゴリズムがデータセットに適用されました。これにより、精度が大幅に向上しました。
二乗平均平方根誤差:0.467±0.008
精度:64.32%±3.99%
次の不正確なマトリックスがYALE出力から抽出されました。

金融ニュースのテキスト分析に基づく株価予測
現在、市場の状況に影響を与える可能性のある大量の貴重なデータがネットワーク上で利用可能です(この効果については、記事で書きました)。 この情報のほとんどは、金融ニュース、会社の報告書、専門家の推奨事項に含まれています(このような推奨事項のソースは、インサイダーやアナリストのブログなどです)。 このデータのほとんどはテキスト形式で表示されるため、使用が困難です。 したがって、新しい問題は、時系列分析の実行と同時にテキスト文書を分析する必要があることです。
研究者は、特定の株式に対するニュースの影響度を判断する方法を使用しました。肯定的(否定的)、否定的(否定的)、または中立的(中立的)のいずれかです。
公表直後の期間に株価が大幅に上昇(または下落)した場合、ニュースはプラスの効果(またはマイナス)を持つと考えられています。 ニュースの発行後に株価が大幅に変化しない場合、その影響は中立と見なされます。
使用される別の方法には、株価の上昇または下降と直接相関するニュース記事のパターンを定義することが含まれます。 次のように機能します。
特別な検索ロボットがニュース記事を調べて、特定の株式ポートフォリオのインデックスを作成します。 学習環境は、インデックス作成の瞬間からT分間、ニュースを要求します。 この環境は、ニュース記事のテキストまたは専門家ブログの資料で必要な情報を探すいくつかのトレーニングモジュールで構成されています(たとえば、「石油の価格が下がる」)。 分析ディクショナリには、ポジティブ(正の予測用語)またはネガティブな動き(負の予測)の条件に影響を与える語句が含まれます。 肯定的な予測用語のセットからのフレーズが記事のテキストに現れるたびに、肯定的な評価(肯定的な投票)が割り当てられます。
次の図は、このようなシステムのアーキテクチャを示しています。

ご覧のとおり、この方法では、かなり大雑把な仮定のみを行うことができます。 それらの精度を高めるには、たとえば、公開する情報源のランキングに基づいて、記事にさらに重みを加える必要があります。 さらに、正または負の予測用語のフレーズを含むテキスト見出し形式を検討する必要があります。
ニュースの重みとして専門家の権威を使用する
また、研究者は、特定の観点を表現する専門家の信頼性の評価、テキスト資料の追加計量への使用についても説明しています。 たとえば、Googleの株式について、彼はこの会社について長い間書いているアナリストのリストを取り上げ、予測の質の程度をアスタリスクで書きました。

株式市場の専門家の意見がシステムの入力に提出され(意見は必ずしも正しいとは限りません)、その後、予測に基づいて、可能な価格変動の予測が繰り返し行われます。 各反復で、予測が真実であることが判明した専門家の重みは増加しますが、間違いを犯した人の場合は逆に減少します。 この方法の別のバリエーションには、誤った専門家のリストから完全に削除することも含まれますが、それは最も効果的ではありません。結局のところ、最高で最も尊敬される金融アナリストでさえ間違っています。
エキスパートの重み付けアルゴリズムは、次のように説明できます。
与えられた:金融の専門家とその予測のベクトルE = {e1、e2、... .eN}。
各エキスパートe(i)に重みW(e(i))= 1を割り当てます。
ラウンドt in 1 ... T
重み付き多数決アルゴリズムに基づいて予測を行います 。
正しい予測を行ったエキスパート向けW(e(i))(t)= 2 * W(e(i))(t-1)
間違った予測を行った専門家の場合W(e(i))(t)=½* W(e(i))(t-1)
さらに計量するために専門家の評価を保存します。
専門家の意見に基づくこの計量手法は、ファンダメンタル分析とテクニカル分析を組み合わせたハイブリッドアプローチと見なすことができます。エキスパートはファンダメンタル分析に基づいて予測を行い、その後アルゴリズムはそれらを使用してテクニカル分析手法を使用して独自の予測を生成します。
おわりに
使用されたすべてのアルゴリズムの中で、サポートベクター法とブースティングアルゴリズムの組み合わせのみが、満足のいく予測精度の結果を達成することができました。
別の有望な分析方法は、専門家による計量です。 ただし、現時点では、株価の動きの予測を生成するための言語分析法の有効性は今後の研究の主題であり、実際の適用性について明確な結論を引き出すことはできません。