はじめに
実際、私はこのcmsを、多くのオープンソースおよび商用システムに存在するものの例にすぎないと考えています。 フリーランサーとして、私は最近までほとんど常にウェブサイトの開発をより安く、より速くする必要がありました-他のフリーランサーは多くの「脂肪」クライアントを持っているかもしれません、私は知りませんでした、私はしませんでした。 そのため、この状況はmodxでの良い経験につながりました。 しかし、私たち自身の会社の開設と、実際のプログラミングとデータベースの構築における私たちのレベルを思い出して改善するために必要な個々のリクエストでクライアントをさらに引き上げました。 そしてここで、MODxと他のオープンシステムの両方の構造を思い出すと、多少の不快感、または少なくとも恥ずかしさを感じました。 さらに、奇妙に見えたが興味深いものを詳細に説明します。
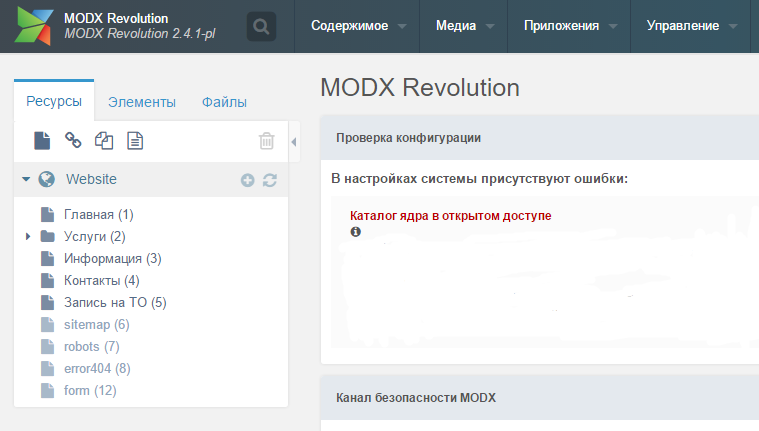
事実、MODx Revoでは、サイト構造を構築するための主要な概念はリソースです。 正確には、たとえば、同じWordPressには、サイトの個別のページ、個別のブログエントリなどはありません。 すべてのページと投稿、さらにはサイトのリソースモデルを介して実装されます。 実際、これは特に、これがcmf / cmsであるという事実を考慮すると便利です。つまり、システムはテーマと技術の両方で完全に異なるサイトを開発するように設計されています。 したがって、1つのリソースコントロールパネルでサイトの構造全体を監視すると便利です。 一般に、リソースシステムを使用すると、次のサイトエンティティを作成および管理できます(オブジェクトを作成したかったのですが、OOPではこの単語は既に使用されているため、 "エンティティ"とします)。
•通常のhtmlページ。
•ブログまたはカタログのさまざまなカテゴリとセクション。
•商品とそのカテゴリ。
•XMLドキュメント。たとえば、検索ロボット用のsitemap.xml。
•たとえば、robots.txtなどのテキストドキュメントは、ファイルをアップロードするだけでなく、リソースを正しく作成します。
•私が同じajaxに個人的に使用するJSONページ。
•独自のテキストファイル形式を作成します。
問題文
私の興味をそそったのは、1つのリソースモデルのオブジェクト内のサイトの多くの異なる「エンティティ」のこの組み合わせでした。 哲学者の心は動揺し、多くの仮定と疑問を提起し始めました。
まず、ユーザーとリソースとは完全に分離されているため、ユーザーに注目しました。 一見論理的に見えるかもしれませんが、一方で、すべてのヒープを統合してこのようなダンスを始めたのであれば、すべてを最後までやらないでください。 はい、行動の最大主義。 さらに、ユーザーを一種のリソースとして作成することは大きな問題ではありません。 modxの場合、これはほとんどの場合、目的に応じてリソースの一部を割り当てることを可能にするリソース属性と「コンテキスト」の数を増やすことができるプレースホルダーを使用して実装されます。 フレームワーク(PHPフレームワークを意味します)またはスクリプトの裸の束とリレーショナルデータベースで同様の何かを実装することは、まったく複雑ではありません。
第二に、完全に独立したモデルは、テンプレートとプレゼンテーションおよびサイト設定のシステム全体を実装します。 実験のためだけに、それらを1つのモデルに結合してはどうでしょうか。 トマトが飛んでくるのを感じます。
プライベートから一般へ
汎化は、個々のオブジェクトの特定のクラスを単一の名前付きオブジェクトとして一般的に表すことを可能にする抽象化です。
ジョン・M・スミス、ダイアナ・C・スミス
実際、これは自然哲学者の仕事の続きであり、データストレージのプレーンに移されただけです。「What is one」であり、データベースを設計するときに一般化する価値はありますか。 一般化、または特定から一般への移行とは、プロジェクトのMVCレベルのいくつかのモデルと、それに応じてmodxで気づいたデータベースレベルのテーブルの合併を意味します。 データベースの状況では、結合されるのはテーブルではなく、キー属性(いわゆる主キー)であり、これもテーブルの結合につながります。 しかし、これは、そのような構造を通常の形にすることができないという意味ではありません。
純粋に仮説的な例を見てみましょう。 データベースを設計するとき、Webアプリケーションのいくつかの「エンティティ」へのアクセスを保存し、提供する必要がありました。異なるロールと権限を持つサイト管理者。 顧客 サイトページ; タグ 商品; カテゴリー。 データベースを構築するにはいくつかの方法があります。 また、データベースの正規化についても話しているわけではありません。データベースの正規化を行う必要があり、3番目の形式に移行します。 私は数、またはあなたが言うことができる、 主キーの多様性を意味します 。
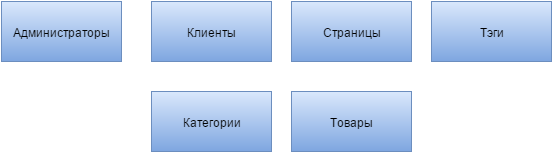
最も自然で広範なソリューションは、「言われたとおりに」すべてを行うことです。つまり、「エンティティ」ごとに独自の主キーと、正規化されたときに個別のテーブルに割り当てることができる非キー属性のセットです(上記の図を参照)。 しかし、このソリューションでは、いくつかの質問と問題が発生します。 また、「管理者とクライアントを異なるアクセスレベルのユーザーに統合しないのはなぜですか」などの質問がある場合は、単純にスコアリングできます。 それは問題に対処する必要があります。 管理者に関しては、その役割とアクセス権を決定する方法を決定する必要があります。 オプションとして、これはさらに別の「エンティティ」または権利と役割のための2つの別個の作成です。 さらに、ロール定義の重要な属性が表示されます。これは、これらの「エンティティ」によって解決されるか、データベースレベルで作成されず、PHPで定義されている場合(サイトおよびアプリケーションを別の言語で記述している場合、ここで言及していると想像してください。 php)、この属性は別のフィールドに作成する必要があります。
別の解決策があります。これは、データベースの一般化のレベルを正確に上げることです。 すべてのユーザーを1つのキー属性に結合できるため、すべての管理者とすべてのクライアントがユーザーであることがわかります。 しかし、何らかの方法でそれらを区別する必要があります。そのためには、ロールの非キー属性を導入する必要があります。これは一般に、最初の方法ではありましたが、顧客には適用しませんでした。 同様に、サイトのページ、カテゴリ、製品、タグを「リソース」オブジェクトに結合できます。 また、ここで追加の非キー属性が必要になります。これにより、どの「エンティティ」がこれまたはそのリソースであるかを判断できます。 繰り返しますが、これはすべて正常に戻すことができます。
このような推論から、データの一般化のレベルがどれほど高くなるかを理解したいという願望が生まれます。 ユーザーは単なるリソースの一種であると想定できます。 modxの経験を思い出して、そのような考えに至った場合、上記の「エンティティ」に加えて、ユーザーロール、アクセス権、テンプレート、およびその他のいわば、システム設定などの関連データを追加する必要があります。 そして、それらすべてを共通の一般化レベルである「オブジェクト」に組み合わせることができます。 「リソース」に完全に適合します。 ここで、オブジェクトレベルの各要素に、それが参照する「エンティティ」を決定する属性が必要です。
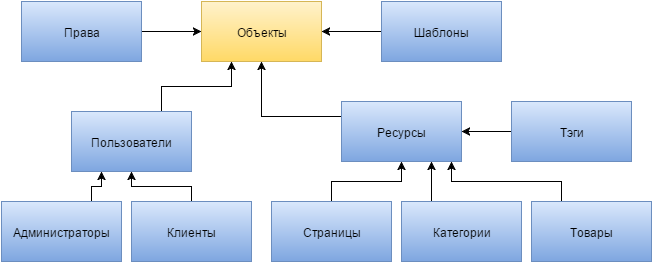
これは、一般化のレベルを上げると確認できます。 まず、実装のために、現在判明しているように、下位レベルの「エンティティ」の位置を決定するキー属性、つまり「一般化属性」も必要です。 可能性のある最低レベルの値を反映する必要があります。 たとえば、サイト管理者の1人には「コンテンツマネージャ」の意味があり、他の人には「プログラマ」などの意味があります。 次に、データベースのすべてのデータがオブジェクトと属性に分割されるという結論に達しました。 本質的に、オブジェクトは同じテーブルフィールドですが、キーであり、一般化属性の値を反映しています。
第三に、おそらく最高レベルを除くすべてのレベルの一般化により、ベースを通常の形に戻すことができますが、それは単なるクレイジーなソリューションのように思えるかもしれません。 また、そうかもしれません。 合計で1,000のページがある場合でも、1000のページ、タグとクライアント、管理者と設定があるとします。 オブジェクトレベルでは、正規化を行って属性を他のテーブルに移動した場合でも、すべてが1つのテーブルに格納されることがわかります。 そして、オブジェクトが数十倍大きい場合はどうなりますか?
最小限の一般化
もちろん、レベルを上げながら、一部を決定しました。 そして、これには、高レベルの抽象化、空の高さなどの利点がありますが、マイナス面はまだあります。 私の意見では、特に高負荷を行う場合は、それらが多すぎます。 一般化のレベルをどれだけ低くすることができるか、そしてそれが「通常の」レベルと比較してどのような賛否両論を負うことができるかを提案します。 実際、一般化のレベルがどれだけ低いかを判断することは、特定のタスクでのみ可能であり、結果は間違いなくそれだけになります。
この例で何ができるか見てみましょう。 もちろん、クライアントはユーザーに帰属しません。 次に、管理者を必要な役割に分割し、それによってそれらを削除し、それぞれの属性として権限のみを残します。 コンテンツマネージャー、seo管理者(おそらく1人)、プログラマーのようなものになると思います。 また、リソースを個別の部分に分割することで、それぞれの「本質」を示す必要がなくなります。 ご覧のとおり、汎化属性は不要になり、データ自体がその役割を果たしていることがわかりました。 また、リソースとユーザーの属性の数がかなり多くなる可能性があるため、属性だけでなくテーブルも削除できます。
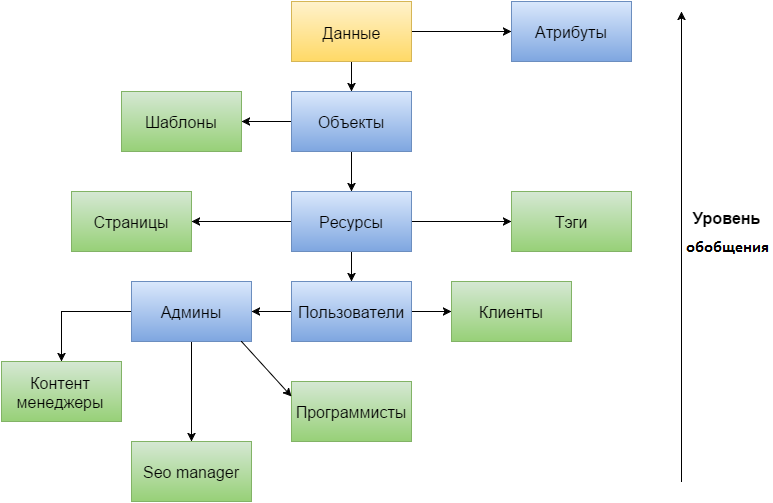
すべての人とすべてを細分化することで、テーブルを増やします。 現在、ユーザーは追加の属性を持つテーブルを除き、1つのテーブルを占有しませんが、この例では4つを占有します。 1つのテーブルであるリソースでも同じことが起こります。 また、一方ではテーブルの数が増えていますが、他方では、正規化後にデータベースがどのように変化するかを考慮しないことに注意する価値があります。 また、ロードされたアプリケーションを開発する際に特に心地よい2つのプラスの効果にも注意してください。 各テーブルの行数が少なくなり、一般化のレベルとテーブルのワークロードの間に直接的な関係があるのはここです。 しかし、正規化ではそのような依存性はなく、さらにその逆もあります。 そしてもう1つプラス、もちろん、正しく使用する場合は、各テーブルを使用する特定の目的があります。 データベースの一般化の高レベルのような曖昧さはありません。 また、一見すると、テーブルの数が多くなるとプロジェクトが複雑になりますが、テーブルの適切な命名、コメントの説明を伴うモデル(使用する場合)が付随しますが、これはデータベース操作の透明性を高めるのに役立ちます。
一方、データベース実装の抽象化レベルは低下し、これは貧弱なサービスを提供する可能性があります。 したがって、たとえば、新しいタイプの管理者が表示された場合、高いレベルで、一般化属性に1つの値を追加するだけで十分です。 その後、この値を割り当てることにより、新しいユーザーを作成できます。 一般化の最小限の抽象化では、このような美しさは機能しません。このタイプの管理者とさまざまな追加の管理者用に新しいメインテーブルを作成するか、既存の管理者と接続する必要があります。 そして、「新しいタイプのユーザーが追加されたのではなく、新しいレベルが下がったらどうなるのか」という疑問が生じます。たとえば、プログラマーは突然バックエンドとフロントエンドに分割されます。
おわりに
ここでは、トピック「What if ...」に関する理論的考察のみを示しますが、実用的なアプリケーションはほとんどありません。 私が見つけたこのトピックで最も堅実で有用なのは、ジョンとダイアナ・スミスの記事「データベースの抽象化:集約と一般化」です。 彼らは私がここで伝えようとしていることを専門的に説明しました。 さまざまなレベルの一般化の負荷テストを試してみたい。 すべての平和と愛。