VTune Amplifier 2016を使用して、OpenCLプログラムを分析できます。 この記事では、このソリューションの使用方法と、Microsoft Visual StudioおよびIntel OpenCLコードビルダーを使用してHelloOpenCLと呼ばれる簡単なOpenCLプログラムを作成する方法を学習します。
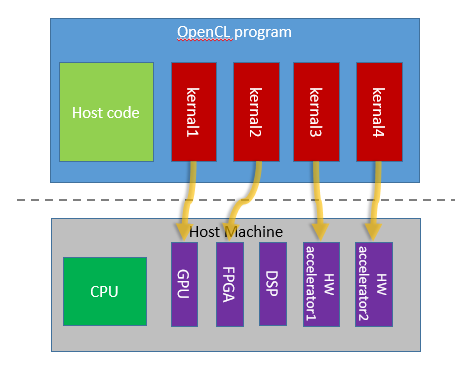
OpenCLは、異種システム、たとえばCPU、GPU、デジタルシグナルプロセッサ、FPGA、その他の物理デバイスを搭載したシステムで並列プログラミングを実装するために設計されたオープンスタンダードです。 OpenCLアプリケーションには通常、ホスト用とデバイス用(「デバイスカーネル」または「カーネル」)の2つのバージョンのコードが含まれています。 ホストAPIには2種類のAPIが含まれています。 プラットフォームAPIは、OpenCLデバイスを選択して初期化するために、利用可能なデバイスとその機能をテストするように設計されています。 ランタイムAPIは、選択したデバイスでカーネルを構成および実行するために使用されます。 OpenCLランタイムで実行されているデバイスのコードを開発するには、Intel OpenCL開発環境のコードコレクターを使用できます。 さまざまなハードウェアベンダーが、OpenCLランタイムの独自の実装を持っています。 したがって、適切な環境がインストールされていることを確認してください。
VTune OpenCLの分析は、どのOpenCLコアが最も時間を費やし、これらのコアが呼び出される頻度を判断するのに役立ちます。 さらに、ハードウェアコンテキストの切り替えのため、異なるハードウェアコンポーネント間でデータをコピーするのにも時間がかかります。 VTuneでは、OpenCLメモリの読み取りおよび書き込みメトリックスを使用して、メモリアクセスに起因するレイテンシを分析できます。 以下のセクションでは、単純なHelloOpenCLプログラムを作成し、VTune OpenCL分析を新しいアーキテクチャスキーマ機能とともに使用する方法を説明します。
GPUの最初のOpenCLプログラム-HelloOpenCLを実行します
HelloOpenCLプログラムの開発を開始する前に、いくつかのコンポーネントをダウンロードする必要があります。 カーネルコードをコンパイルしてプラットフォームの互換性を確認するには、INDEパッケージに含まれるIntel OpenCLコードビルダーをダウンロードできます。 次に、ターゲットデバイスにOpenCLランタイム実装をインストールする必要があります。 Intel OpenCL実装は、Intelグラフィックパッケージの一部です。 ここからドライバをダウンロードできます。 手順およびその他のダウンロードオプションについては、 このページをご覧ください。
Intel OpenCLコードビルダーをインストールした後、サポートするOpenCLデバイスを確認できます。 このテスト対象システムには、第4世代Intel®Core™プロセッサー(Haswell)が搭載されています。
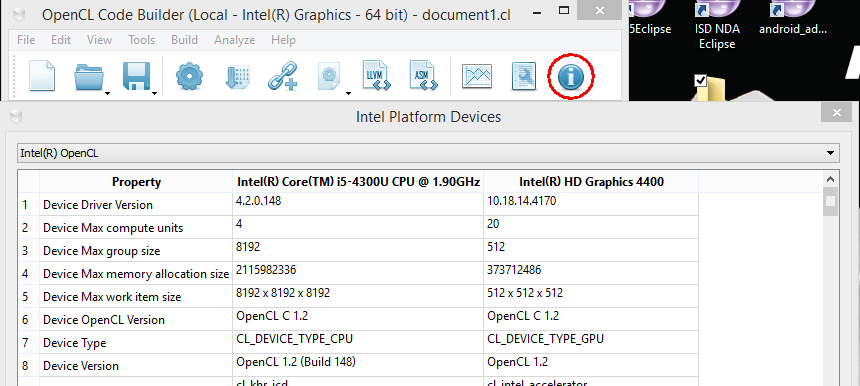
上の図に示すように、環境が必要なOpenCLデバイスをサポートしていることを確認した後、Microsoft Visual Studio Professional 2013を使用して、インストールされたHelloOpenCLテンプレートを使用して最初のOpenCLプログラムを作成するか、この記事に含まれているサンプルコードを直接使用できます。 このサンプルコードは、GPUに2つの2次元バッファーで数学的加算演算を実行するように要求します。 合計は2次元の出力バッファーです。 このようなシナリオは、標準の画像フィルターを使用して適用できます。 HelloOpenCL コードのサンプルを次に示します 。
VTune Amplifier 2016を使用したHelloOpenCLのプロファイリング
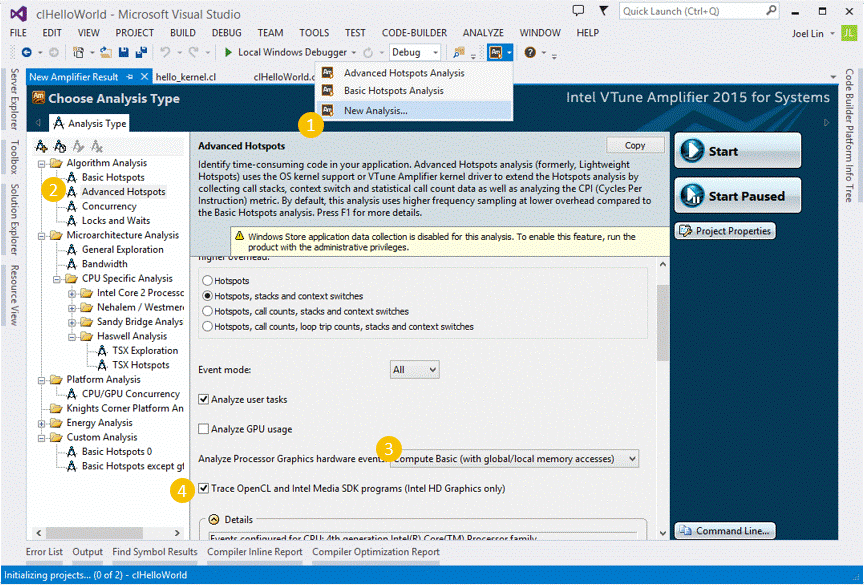
HelloOpenCLプログラムを正常にビルドしたら、VTuneを起動して、Visual Studio開発環境でアプリケーションのプロファイルを作成できます。 VTuneでOpenCLプロファイリングを構成する方法の詳細については、次の図を参照してください。
- VS 2013開発環境でVTuneを起動します。
- 分析のタイプホットスポットを選択します。
- グラフィックハードウェアメモリアクセスイベントを選択します。
- OpenCLプログラムのチェックボックスを選択します。
VTuneログを正常に収集すると、グラフィックタブに移動して、以下に示すVTune分析グラフが表示されます。 機能の詳細については、次のポインターを参照してください。

- VTuneには、関数呼び出しリストのグループビューがいくつか含まれています。 GPUのopenCLプログラムには、グループビューComputing Task Purpose / *があります。これにより、OpenCLをサポートするメトリックを使用して、OpenCL APIの有効性をより詳しく説明できます。
- これらの注釈は、CPU側で実行されるOpenCLシステムAPIコードを記述しています。 また、CPUがタスクの1つの機能を実行する時間に関する情報も提供します。 clBuildProgramは、カーネルコードをOpenCLランタイムで実行できるプログラムに解釈します。 clCreateKernelは、以前にコンパイルされたOpenCLプログラムで1つのカーネル関数を選択します。これには、いくつかのカーネル関数が含まれている場合があります。 clEnqueueNDRangeは、GPUがこのコマンドを受信して処理するOpenCLコマンドキューに特定のカーネル関数を配置します。
- このIntel®HD Graphics 4 ...タイムラインは、AddがIntel GPUでのランタイム環境の実装で計画されているカーネル機能であることを示しています。
- GPUハードウェアで実際の追加アクションが発生すると強調表示されます。 カーネル関数の計画実行時間と、特定の準備およびコンテキストの切り替えに起因する実際の実行時間の間にギャップがあります。
- これは、VTune Amplifier 2016の最新バージョンで利用可能な新機能です。次の図に示すように、静的データ形式を使用したデータ転送の効率を示し、GPUアーキテクチャの一般的なスキームにおけるデータフローの速度に関するデータを示します。 型なしメモリの読み取り速度は、書き込み速度の2倍です。これは、HelloOpenCLアプリケーションの動作と一致しています。

このアーキテクチャスキームを使用すると、HelloOpenCLアプリケーションの第3レベルキャッシュに割り当てられているバッファーの動作を監視することもできます。 ほとんどの場合、GPUはアイドル状態であるため、GPUの使用率は大幅に向上します。 つまり、Intel OpenCLデバイスはより複雑なタスクを実行できます。