MPI標準(Message Passing Interface)を実装するライブラリは、クラスターで計算を整理するための最も一般的なメカニズムです。 MPIを使用すると、ノード(サーバー)間でメッセージを転送できますが、1つのノードで複数のMPIプロセスを実行することを誰も気にせず、複数のコアの可能性を実現します。 HPCアプリケーションは頻繁に作成されるため、簡単です。 また、1つのノード上のコアの数は少なかったものの、「クリーンMPI」アプローチに問題はありませんでした。 しかし、今日、コアの数は、Intel Xeon-Phiコプロセッサーの場合、数十、または数百にもなります。 また、このような状況では、1台のマシンで数十のプロセスを実行することは完全に効果的ではありません。
実際、MPIプロセスはネットワークインターフェイスを介して通信します(ただし、1台のマシンの共有メモリを介して実装されます)。 これには、複数のバッファ間でのデータの冗長コピーとメモリ消費の増加が伴います。
共有メモリを備えた同じマシン内での並列コンピューティングには、スレッドとスレッド間のタスクの分散がはるかに適しています。 ここで、HPCの世界で最も人気があるのはOpenMP標準です。
どうやら-まあ、ノード内でOpenMPを使用し、ノード間通信にMPIを使用しています。 しかし、それほど単純ではありません。 1つではなく2つのフレームワーク(MPIとOpenMP)を使用すると、プログラミングがさらに複雑になるだけでなく、少なくともすぐにではなく、常に望ましいパフォーマンスが向上するわけではありません。 MPIとOpenMPの間でコンピューティングを分散する方法を決定し、場合によっては各レベルに固有の問題を解決する必要があります。
この記事では、ハイブリッドアプリケーションの作成については説明しません。情報を見つけるのは難しくありません。 Intel Parallel Studioツールを使用してハイブリッドアプリケーションを分析し、最適な構成を選択し、さまざまなレベルでボトルネックを排除する方法を検討します。
テストには、NASA Parallel Benchmarkを使用します。
- CPU:Intel XeonプロセッサーE5-2697 v2 @ 2.70GHz、2ソケット、各12コア。
- OS:RHEL 7.0 x64
- Intel Parallel Studio XE 2016 Cluster Edition
- コンパイラー:インテル®コンパイラー16.0
- MPI:Intel MPIライブラリ5.1.1.109
- ワークロード:NPB 3.3.1、「CG-共役勾配、不規則なメモリアクセスと通信」モジュール、クラスB
ベンチマークはすでにハイブリッドとして実装されており、MPIプロセスとOpenMPストリームの数を構成できます。 (アプリケーションの一部として)ノード間通信にはMPIに代わるものがないことは明らかです。 陰謀は、単一ノード(MPIまたはOpenMP)で実行されることです。
MPIパフォーマンススナップショット
24個のコアを自由に使用できます。 従来のアプローチから始めましょう-MPIのみ。 24 MPIプロセス、各1スレッド。 プログラムを分析するには、最新バージョンのIntel Parallel Studioでリリースされた新しいツール-MPI Performance Snapshotを使用します。 「-mps」スイッチをmpirun起動行に追加するだけです。
source /opt/intel/vtune_amplifier_xe/amplxe-vars.sh source /opt/intel/itac/9.1.1.017/intel64/bin/mpsvars.sh --vtune mpirun -mps –n 24 ./bt-mz.B.24 mps -g stats.txt app_stat.txt _mps
最初の2行は目的の環境を設定し、3行目はMPSプロファイリングでプログラムを開始します。 最後の行は、html形式のレポートを生成します。 -gを指定しない場合、レポートはコンソールに表示されます-クラスターですぐに表示するのに便利ですが、HTMLではより美しくなります。


MPSは、トップレベルのパフォーマンス評価を提供します。 実行のオーバーヘッドは非常に小さく、大規模(テスト済みの32,000プロセス)でもアプリケーションを迅速に評価できます。
開始するには、MPI時間と計算時間のシェアを見てください。 時間の32%をMPIに費やしていますが、そのほとんどは負荷の不均衡によるものです。一部のプロセスは他のプロセスの検討を待っています。 右側のブロックには推定値があります-MPI時間はHIGHとマークされています-通信に無駄が多すぎます。 MPIの問題を詳細に分析するための別のツール、Intel Trace Analyzer and Collector(ITAC)への参照もあります。 OpenMPについては、問題は特に強調されていませんが、実際には無効にしたため、驚くことではありません。
MPSは、GFPLOS、CPI、および「メモリバウンド」メトリックなどのハードウェアパフォーマンスメトリックも考慮します。これは、メモリパフォーマンスの全体的な評価です。 また、メモリ消費(1つのMPIプロセス)-最大および平均。
Intel Trace Analyzer and Collector
MPSは、主な問題がMPIの「24x1」構成であることを示しました。 理由を調べるために、ITACプロファイルを収集します。
source /opt/intel/itac/9.1.1.017/intel64/bin/itacvars.sh mpirun -trace -n 24 ./bt-mz.B.24
ITAC GUIでトラックを開きます-Windowsバージョンを使用しました。 定量的タイムライングラフは、MPIの割合が大きく、通信が一定の周期性で分散されていることを明確に示しています。 一番上のグラフは、MPIアクティビティの周期的なバーストを示しています。
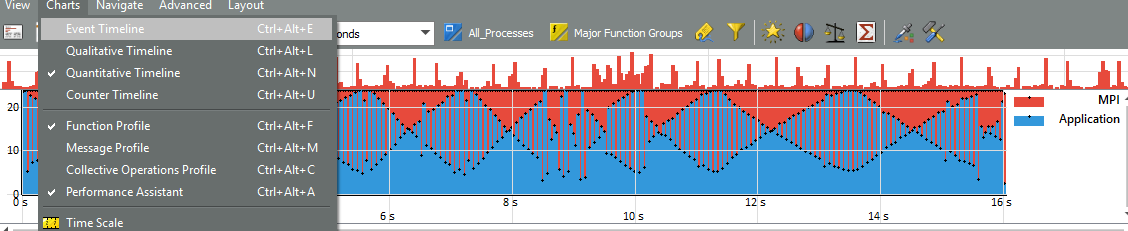
イベントタイムラインでこのようなバーストが複数強調表示されている場合、通信が均等に分散されていないことがわかります。 ランク0〜4のプロセスはさらにカウントされ、ランク15〜23のプロセスはさらに多くなります。 負荷の不均衡は明らかです。
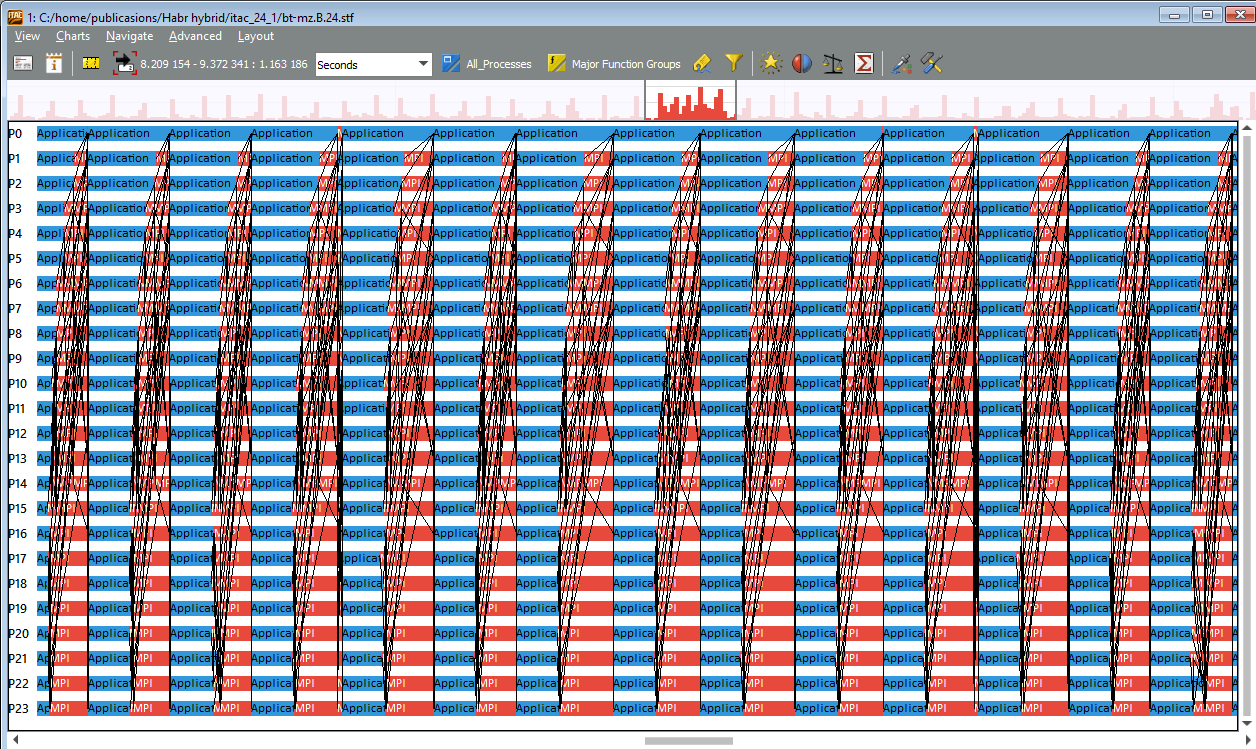
メッセージプロファイルグラフでは、どのプロセスがメッセージを交換しており、通信が最も長い場所を正確に評価できます。
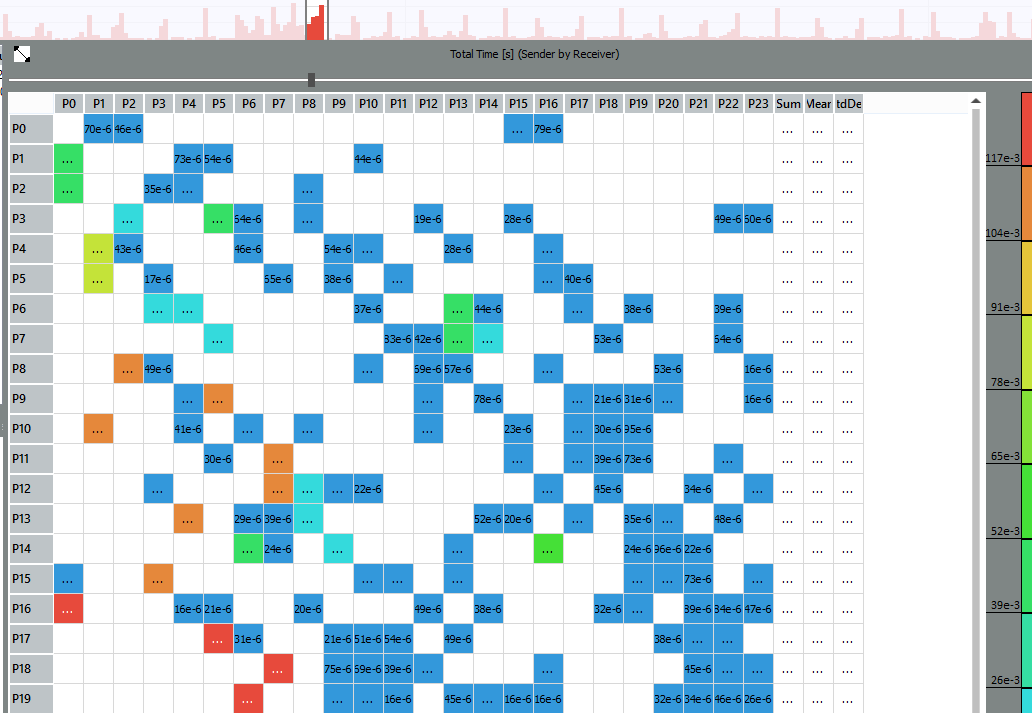
たとえば、ランク17と5、16と0、18と7などのプロセス間のメッセージは、他のメッセージよりも長く続きます。 イベントタイムラインをさらに強化することで、ランク17の黒い線をクリックして、転送の詳細(誰から、誰へのメッセージサイズ、通話の送受信)を確認できます。
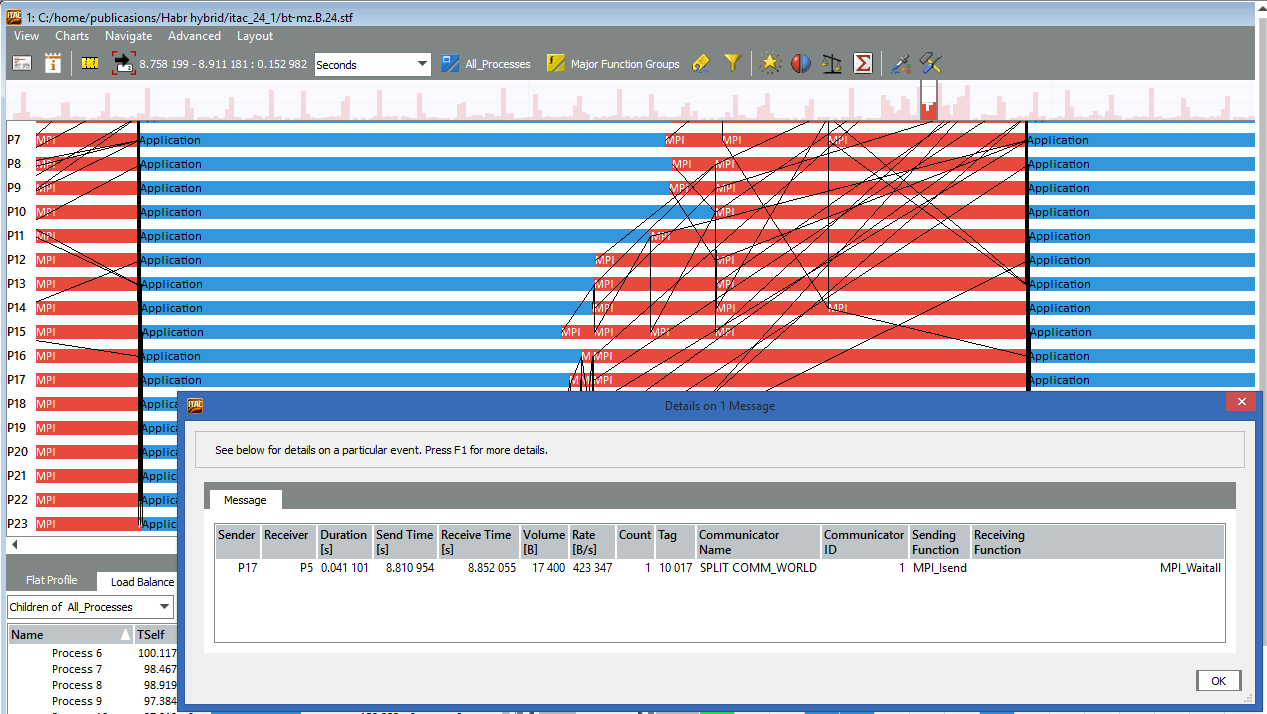
パフォーマンスアシスタントパネルには、選択した領域でツールによって検出された特定の問題が表示されます。 たとえば、「遅延送信」:
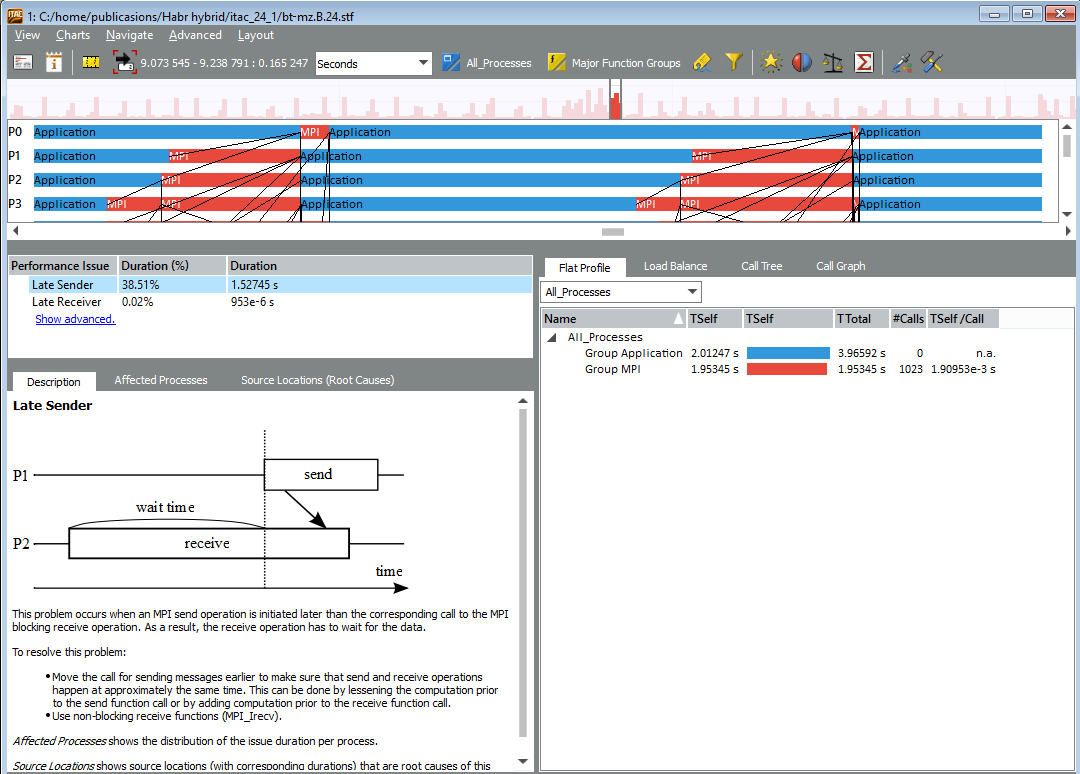
MPIの不均衡は、通信スキームの欠陥だけでなく、一部のプロセスが他のプロセスよりも遅いと見なされる有用なコンピューティングの問題によっても発生する可能性があります。 このアプリケーションがプロセスの1つの内部で時間を浪費していること、および問題の可能性に関心がある場合、ITACはこのランクのIntel VTune Amplifierを起動するコマンドラインを生成できます(2番目など)。

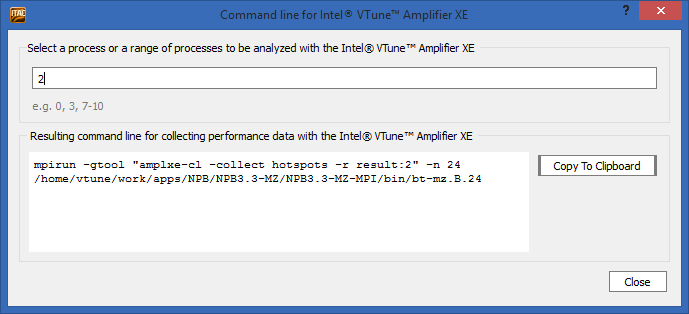
ただし、後でVTune Amplifierに戻ります。 とにかく、ITACはMPI通信の詳細な研究のための多くの機会を提供しますが、私たちの仕事はOpenMPとMPIの間の最適なバランスを選択することです。 このため、24ランクのMPI通信をすぐに修正する必要はありません。他のオプションを最初に試すことができます。
その他のオプション
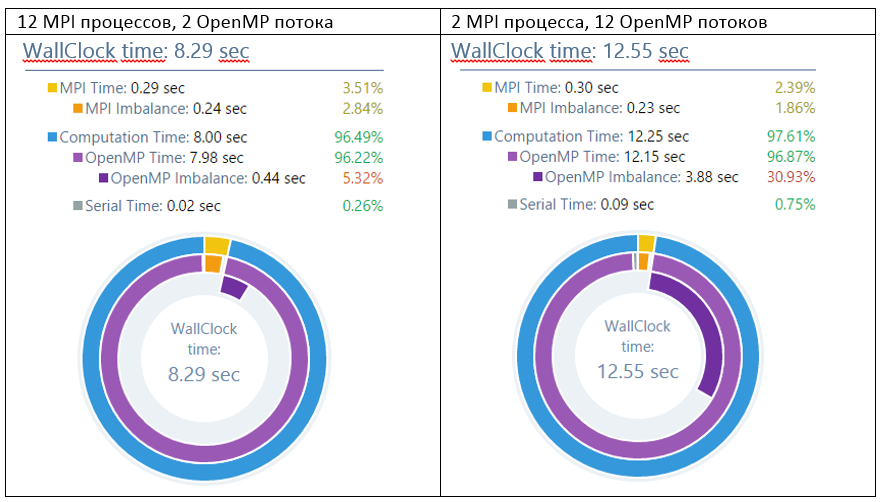

したがって、経験的に、12x4および6x4ディストリビューションは他のディストリビューションよりも優れていることが判明しました。 プロセスあたり2つのOpenMPストリームでさえ、2つのMPIプロセスよりも大幅に高速です。 ただし、スレッド数の増加に伴い、動作時間が再び増加し始めます。2x12は「純粋なMPI」よりもさらに悪化し、1x24は意味がありません。 そして、欠点は作業の不均衡であり、これは多数のOpenMPストリームに十分に分散されていません。 オプション2x12には最大30%の不均衡があります。
ここで停止するかもしれません、なぜなら 妥協点は12x4または6x4に達しました。 しかし、さらに深く掘り下げることができます-OpenMPスケーリングの問題を調査するために。
VTuneアンプ
OpenMPの問題の詳細な分析には、インテルVTuneアンプXEが最適です。これについてはすでに詳しく説明しました。
source /opt/intel/vtune_amplifier_xe/amplxe-vars.sh mpirun -gtool "amplxe-cl -c advanced_hotspots -r my_result:1" -n 24 ./bt-mz.B.24
VTune AmplifierやIntel Advisor XEなどのアナライザーを実行するには、gtoolオプション構文(Intel MPIのみ)を使用すると非常に便利になりました。 MPIアプリケーションの起動ラインに組み込まれているため、選択したプロセス(この例ではランク1のみ)でのみ分析を実行できます。
「2 MPIプロセス、12 OpenMPストリーム」オプションのプロファイルを見てみましょう。 最も高価な並列ループの1つでは、1.5のうち0.23秒が不均衡になります。 さらに表では、スケジューリングのタイプは静的であり、作業の再分配は行われないことがわかります。 さらに、ループには41回の反復があり、隣接するループには10〜20回の反復があります。 つまり 12スレッドでは、各スレッドは3〜4回の反復しか取得しません。 どうやら、これは効果的な負荷分散には不十分です。
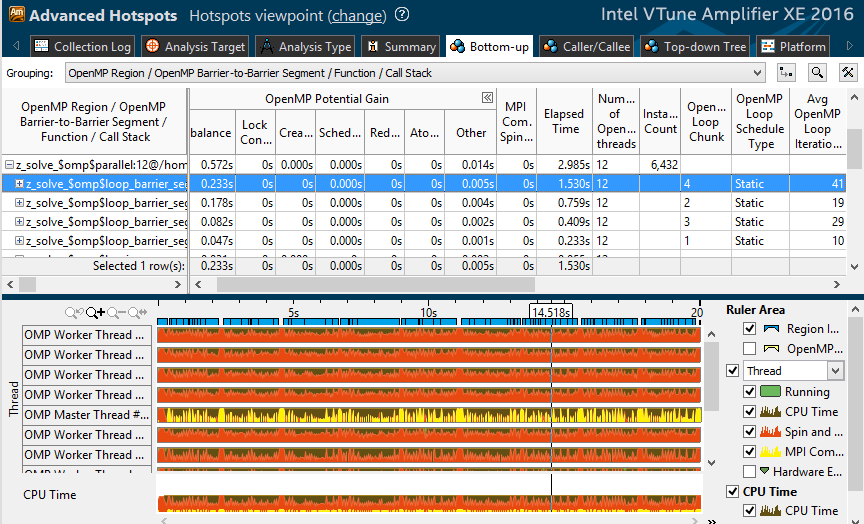
2〜4個のスレッドを使用すると、各スレッドの処理量が増え、不均衡によって発生するアクティブな待機の相対時間が短縮されます。 「6x4」プロファイルで確認されること-不均衡ははるかに低くなります。
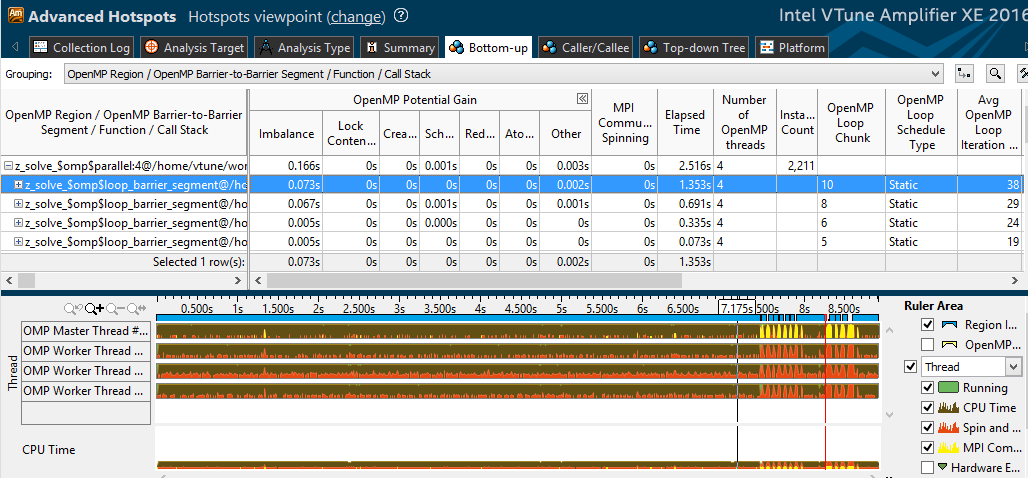
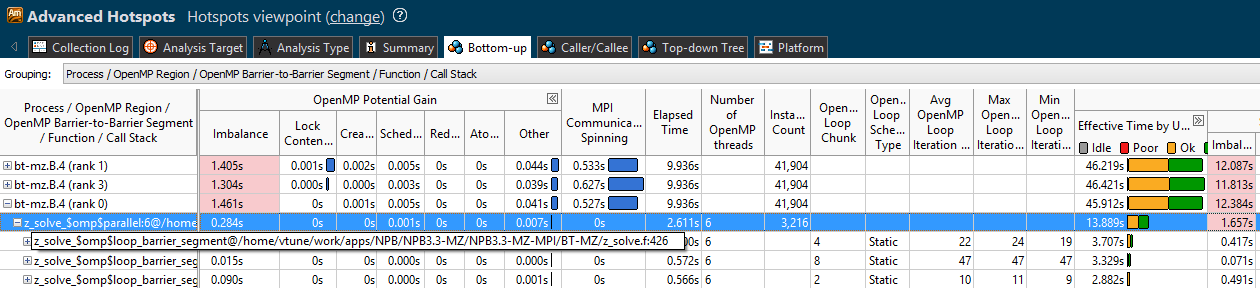
さらに、Intel VTune Amplifier 2016では、MPI時間が表示されました-「MPI Communication Spinning」列とタイムライン上の黄色のマーク。 1つのノードで複数のプロセスのVTuneプロファイルを一度に実行し、それぞれのOpenMPメトリックとともにMPIの回転を観察できます。

Intel Advisor XE
クラスタースケール(MPI)から1つのノードのフロー(OpenMP)まで、並列処理のレベルを下げると、同じフロー内のデータ(SIMD命令に基づくベクトル化)に従って並列処理が行われます。 ここでも、最適化の重大な可能性がある可能性がありますが、最後に到達したのは無駄ではありませんでした。まず、MPIおよびOpenMPレベルで問題を解決する必要があります。 潜在的に勝つことができる可能性があります。 Advisorについての記事は2つ前( 1つ目と2つ目 )でしたので、ここではローンチラインに限定します。
source /opt/intel/advisor_xe/advixe-vars.sh mpirun -gtool "advixe-cl -collect survey --project-dir ./my_proj:1" -n 2 ./bt-mz.2
次に、前に書いたように、コードのベクトル化を分析します。 アドバイザーは、エコシステム分析クラスターMPIプログラムの重要な部分です。 Advisorは、コードベクトル化の詳細な調査に加えて、マルチスレッド実行のプロトタイプを作成し、メモリアクセスパターンを検証します。
まとめ
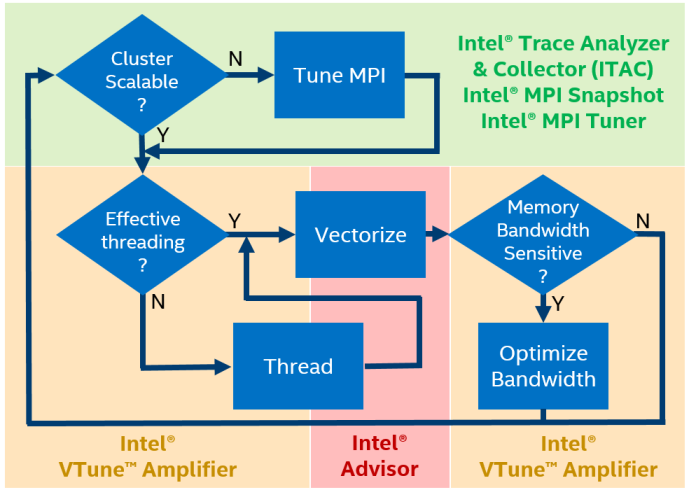
Intel Parallel Studioは、ハイブリッドHPCアプリケーションのパフォーマンスを分析するための4つのツールを提供します。
- MPIパフォーマンススナップショット(クラスターレベル)-迅速なパフォーマンス評価、最小限のオーバーヘッド、最大32000 MPIプロセスのプロファイリング、MPIとOpenMPの不均衡の迅速な評価、一般的なパフォーマンス評価(GFLOPS、CPI)。
- Intel Trace Analyzer and Collector(クラスターレベル)-MPIの詳細な調査、通信パターンの識別、特定のボトルネックのローカリゼーション。
- Intel VTune Amplifier XE(シングルノードレベル)-ソースコードとスタック、不均衡などのOpenMPの問題、キャッシュとメモリ使用量の分析などの詳細なプロファイル。
- インテル®Advisor XE(シングルノードレベル)-ベクトル命令の使用の分析と非効率の理由の特定、マルチスレッド実行のプロトタイピング、メモリーアクセスパターンの分析。