IBM Watsonは、世界で最初の認知システムの1つです。 このシステムは多くのことができるため、ワトソンの機能は、料理から地域の事故の予測まで、多くの分野で使用されています。 一般に、Watsonの機能のほとんどは独自のものではありませんが、組み合わせることで、これらの機能はすべて、さまざまな問題を解決するための非常に強力なツールです。
たとえば、自然言語認識、動的システムトレーニング、仮説の構築と評価。 これにより、IBM Watsonは、オペレーターの質問に(正確度を高めて)直接正解する方法を学ぶことができました。 同時に、コグニティブシステムは、グローバルな非構造化データの大きな配列であるビッグデータを使用して動作できます。 IBM Watson言語を使用する基本的な原則は何ですか? これについて-続編。
自然言語認識の主な困難
人にとって、言語は思考を表現する手段です。 この言語を使用して、意見、データ、情報を伝えます。 予測を立て、理論を形成することができます。 私たちの意識の基礎となるのは言語です。 同時に、ここに逆説があります。人間の言語は非常に不正確です。
多くの用語は非論理的であり、コンピューターシステムが私たちを理解することは非常に困難です。 たとえば、微妙な声はどのようになりますか? どうして恥をかいて燃やすことができますか? 車の場合、これは問題です。男性の場合、それはごく普通のことです。 実際、多くの場合、質問に対する正しい答えを得るには、既存のコンテキストを考慮する必要があります。 十分な事実情報がない場合、文字通りの意味で質問の要素に対する正確な答えを見つけることができたとしても、質問に正しく答えることは困難です。
自然言語処理-始まり
多くのコンピューターシステムは言語を分析できますが、同時に表面的な分析が実行されます。 これは、たとえば、大量の情報で感情の傾向の統計的に有効な推定値を提供するために、理にかなっている場合があります。 ここでは、偽陽性の結果の数が偽陰性の結果の数にほぼ等しいと仮定しても、それらは互いに打ち消し合うため、情報転送の精度はそれほど重要ではありません。
しかし、すべてのケースが重要な場合、言語の表面的な分析で動作するシステムは、もはや正常に機能しなくなります。 言われたことの鮮明な例は、モバイルデバイスの音声アシスタントのタスクです。 「ピザを探してください」と言うと、アシスタントはピッツェリアのリストを表示します。 たとえば、「マドリードでピザを探してはいけない」と言っても、システムは検索を続けます。 このようなシステムは、特定のキーワードを特定し、特定のルールセットを使用することで機能します。 結果は、ルールの特定のシステムでは正確である場合がありますが、正しくありません。
深い自然言語処理
感情やその他の要因を考慮して、複雑な意味構造を分析するようシステムに教えるために、専門家は自然言語の深い処理を使用しました。 つまり、コンテンツ分析の質問回答システム(Deep Question * Answering、DeepQA)。 より高い精度が必要な場合は、自然言語処理の追加の方法を使用する必要があります。
IBM Watsonは、深い自然言語処理システムです。 特定の質問を分析する場合、正しい答えを出すために、システムは可能な限り幅広いコンテキストを評価しようとします。 この場合、質問の情報だけでなく、知識ベースのデータも使用されます。
自然言語の深い処理を実行できるシステムを作成することで、別の問題-毎日生成される膨大な量の情報の分析-を解決することが可能になりました。 これは、ツイート、ソーシャルメディアの投稿、レポート、記事などの非構造化情報です。 IBM Watsonは、これらすべてを使用してヒューマンタスクを解決する方法を学びました。
認知システムIBM Watson
ワトソンは、異なるレベルの計算能力です。 システムは、自然言語で特定のステートメントを分離し、これらのステートメント間の接続を見つけることができます。 同時に、多くの場合、ワトソンは人よりも優れたタスクに対処しますが、データ処理ははるかに高速ですが、作業ははるかに大容量で実行されます-人は単にこれに対応できません。

認知システムの主な特徴
システムは次の順序で機能します。
1.質問を受け取った後、Watsonは解析を実行して、質問の主な特徴を強調します。
2.システムは、ある程度の確率で必要な回答を含む可能性のあるフレーズを探してコーパスを調べて、いくつかの仮説を生成します。 非構造化情報のフローで効果的な検索を行うためには、完全に異なる計算機能が必要です*それらは認知システムと呼ばれます。 (最後の文とアスタリスクの役割を本当に理解していない)
3.システムは、さまざまな推論アルゴリズムを使用して、質問の言語と可能な回答のそれぞれの言語の詳細な比較を実行します。
これは難しい段階です。 数百の推論アルゴリズムがあり、それらはすべて異なる比較を実行します。 たとえば、一致する用語と同義語を検索するものもあれば、時間的および空間的特徴を調べるものもあれば、コンテキスト情報の適切なソースを調べるものもあります。
4.各推論アルゴリズムは、このアルゴリズムで考慮される領域で、質問から可能な回答がどの程度続くかを示す1つ以上の評価を設定します。
5.得られた各評価には、統計モデルに従って重み係数が割り当てられます。このモデルは、「ワトソントレーニング期間」中にこのフィールドからの2つの類似フレーズ間の論理接続の識別にアルゴリズムがうまく対処したことを記録します。 次に、この統計モデルを使用して、ワトソンシステムの全体的な信頼レベルを判別できます。これは、質問から可能な回答が続くことを示しています。
6.ワトソンは、残りの回答よりも正しいと思われる回答が見つかるまで、考えられる回答ごとにプロセスを繰り返します。
前述のように、質問に対する正しい答えを得るには、システムは追加のデータソースを使用する必要があります。 教科書、マニュアル、FAQ、ニュースなどがあります。 Watsonは膨大な量の情報を数秒で処理して、正しい答えを導き出します。 同時に、見つかったコンテンツもチェックされ、古くて無駄なデータが選別されます。
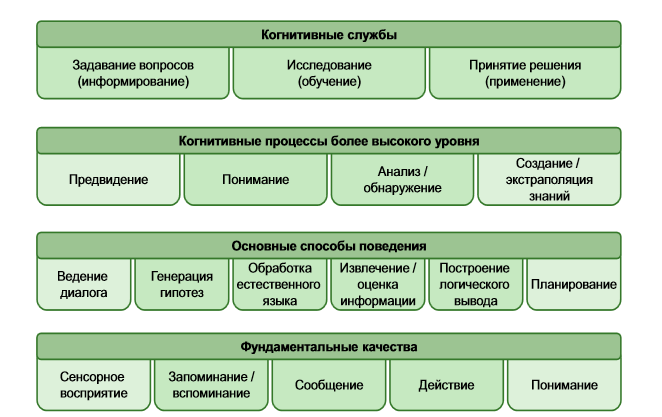
認知システムの要素
Watsonは、追加のデータベースから受信した情報からテキストの一般的な意味を推測します。 これは、ドキュメントのタイトル、ドキュメントのテキストの一部、またはテキスト全体を使用します。
認知システム、情報の収集、保存、抽出の方法は、人が情報を分析する方法に似ています。 そうすることで、認知システムは情報を伝達して行動することができます。 この場合に使用される動作構造の例を次に示します。
-仮説を作成およびテストする機能。
-コンポーネントに分解し、言語に関する論理的な結論を構築する機能。
-有用な情報(日付、場所、特性など)を取得および評価する機能。
これらの能力がなければ、コンピューターも人も、質問と回答の正しい関係を判断できません。
高次の認知プロセスは、主要な行動に焦点を合わせて、高いレベルの理解を達成できます。 何かを理解するためには、情報を、問題のレベルで合理的に順序付けられた小さな要素に分割できる必要があります。 人間の物理的プロセスは、宇宙規模のプロセスや素粒子レベルのプロセスとはまったく異なります。 同様に、認知システムは人間レベルで機能するように設計されていますが、それらは膨大な数の人々を表しています。
この点で、言語の理解は、言語のより単純な規則の理解から始まります-正式な文法だけでなく、日常の使用で観察される非公式の慣習も。
なんでこんなこと?
現在、IBM Watson認知システムは、長年のトレーニングと改善のおかげで、さまざまな分野で作業を行うことができます。 ここでは、医学、料理、言語学、およびビジネス上の問題と科学的な問題の解決策があります。
当初、専門家には選択肢がありました-システムをユニバーサルにするか、専門にするか。 オプションにはそれぞれ長所と短所がありますが、普遍性に向かって選択が行われました。
同社は何度も完璧な選択の正しさを確信してきました。IBMWatsonの前に膨大な数の機会が開かれました。 たとえば、認知システムは、癌の治療のための個々の方法を見つけたり、オリジナルのレシピを作成したり、会社でビジネスプロセスを確立したりするのに役立ちます。 多くの問題は解決されましたが、さらに多くの問題はまだ解決されていません。