制御システムでの信号形成(ローカルオートメーション信号の遅延)の特徴により、動作時間の計算にいくつかの困難が生じます。
タスクの本質は非常に単純です。定期的な技術検査とタイムリーなメンテナンスを必要とする非常に高価な機器がたくさんあります。 過去10年間に、たとえば6か月に1回、3か月に1回など、実際の稼働時間と相関することなく、機器の保守が行われてきました。 要点は、機器に事故が発生し、同時に機器が実際にサービス前よりも長く働いていた場合、マネージャーは座るということでした。
誰も座りたくなかったので、彼らはそれを大きなマージンで考えました。 一方、必要以上に頻繁にメンテナンスを行う-修理、作業、ダウンタイムで余分なお金を失う。 したがって、正確な会計が必要でした。
ハイテク産業では、方法の1つは、各稼働時間を考慮する必要のある各技術オブジェクトに特別なコントローラーを配置することです。 かなり高いです。 マシンやその他のハイテク機器は彼ら自身が検討していますが、単にデータを正しく収集することが重要です。 私たちの場合、稼働時間は、「機械が3日間プラスまたはマイナス4時間働いた」などのメカニズムを使用して、ジャーナルに手動で記録されました。 その結果、管理ソフトウェアを選択して、そこからデータを削除することが決定されました。 次に、次に何が起こったのか、上の写真が何に関係するのかを説明します。
建築
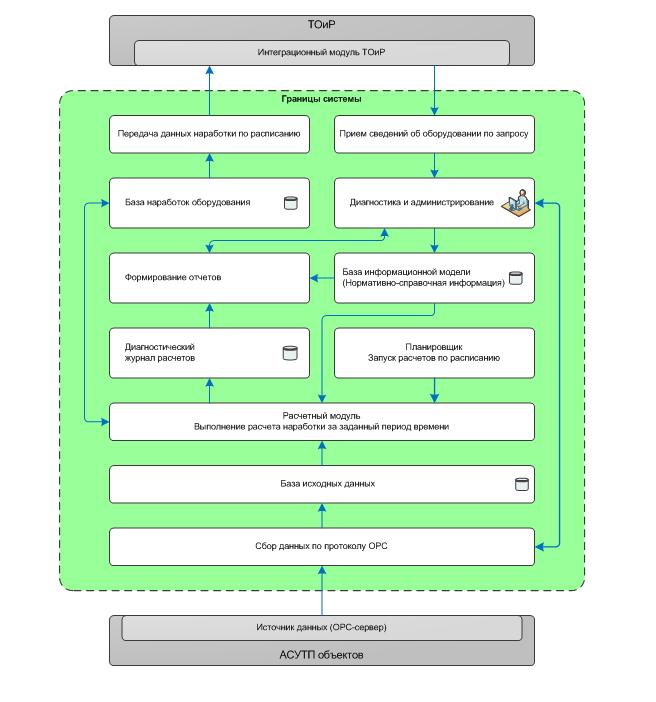
機械稼働時間計算システムの機能アーキテクチャ
作業の本質-すでに産業制御システムからのものである生産のすべてのイベントに関するデータを取得します。 理想的な世界では、すべての信号回路は理想的には何とどのように表示されます-機器の画像(それが何であり、どのように動作するか)を1レベル高いシステムから取得して信号回路を適用し、アルゴリズムを使用して動作時間を計算し、それをMROシステムに戻すだけです。 しかし、私たちは現実の世界にいるので、それはうまくいきませんでした。 まず、理想的な世界では、各マシンには詳細な指示があり、現実に正確に対応しています。 私たちの世界では、多くのことの仕事の性質を経験的に特定する必要がありました。
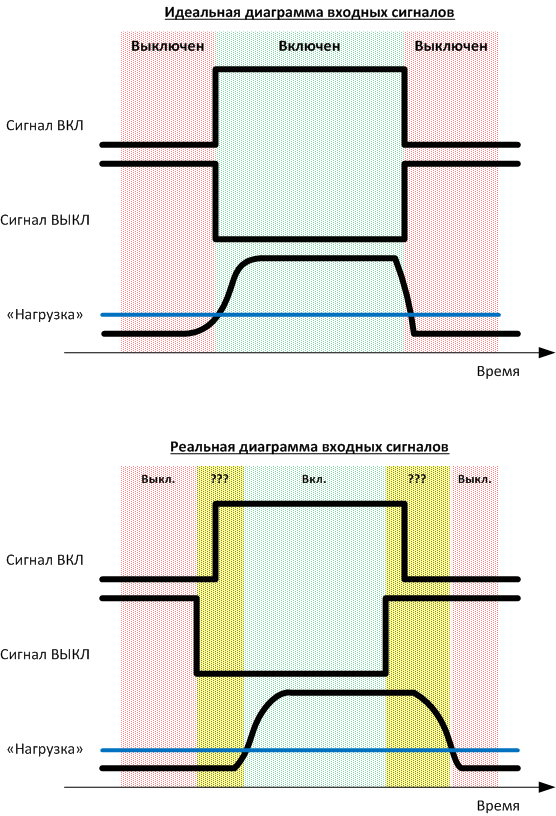
たとえば、katの前の写真では、サービスシグナリング(2ビット-「ON」信号と「OFF」信号)が突然トリガーから非常に怪しいものに変わる最も単純なケースを見ることができます。 それが人生です。 そして、与えられた信号ではなく、(この特定のケースでは)負荷によって機械の動作時間を考慮する必要があります。 他の状況はもっと面白かったですが、悲しいかな、私は深く行く権利がありません。それはあまりにも具体的な制作です。
仕事はどうでしたか
そのため、自動化されたプロセス制御システム(監視制御および管理)からのデータを分析し、稼働時間(より正確には、さまざまな状態スイッチ、および最終的に稼働時間になるその他のイベント)をカウントし、さらにERP(MRO)に送信するサーバーがあります。予防修理が計画されています。 おおまかに言って、機器の状態に関するデータを下に、そしてその上に-その階層を取得します。
計算スキームは上記です。 一般に、これはよく知られた技術プロセスであり、抽象化の形で4つの異なる産業ソフトウェアメーカー(オープンソースソリューションを含む)によってサポートされていますが、通常-特定のオブジェクトに関しては、ファイルで変更する必要があります。 すでに述べたように、制御システムの機能はソフトウェアのロジックを完全に破壊することができるため、共通のアーキテクチャだけでなく、特定のデータ修正アルゴリズムも作成しました。 ここで、機器の状態に関するデータは、「オン」信号、「オフ」信号、および現在の機器負荷の3つの信号の形式で提供されることを明確にする必要があります。 負荷の場合、しきい値が設定され、それを超えると、機器の電源がオンになり、公称モードで動作すると見なされます。 理想的には、これらの信号は互いに調和して変化する必要があります。 しかし、現実には、信号が予想どおりに常に変化するとは限らないことが判明しました。 これにより、さらに困難が生じます。 さらに、説明が不十分であるか、実装が異なるか、プロトコルで最初にサポートされていなかったため、信号の一部を追加する必要がありました。
次に、システムコンポーネント間の通信障害が発生した場合に履歴データを復元し、この接続の長期中断時の動作時間の計算スキームを開発する必要がありました。 そのような状況に対応するためのツールを記録、再集計、作成しました。 物理的な接続が切断されたため、イベントが表示されなかっただけで、信号損失の事実を知らなかったことが問題です。 これらはプロトコルの機能です。 その結果、自動プロセス制御システムのレベルで、「パルス」を作成する必要がありました。これは、1秒間に1回移動する一種の仮想バルブです。 この「センサー」のおかげで、信号が来ていることがわかりました。 彼が誤って、または歪みを伴って「クリック」した場合、その期間を信頼できないものとしてマークしました。 信頼できない期間にわたってログからデータを回復できない(または手動でカウントする)ことが不可能な場合、メインタスクはメンテナンスなしで制限を超えることはないため、レベルが高いほど動作時間としてマークされている可能性があります。
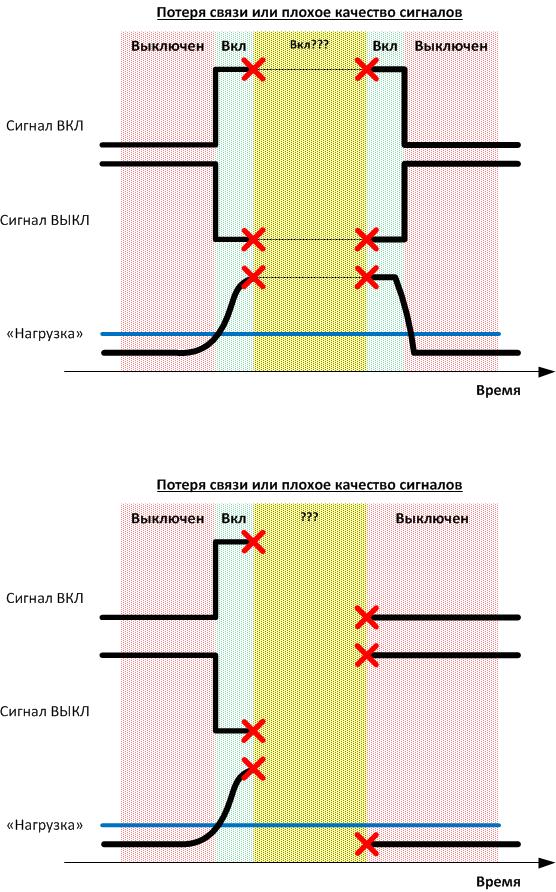
データ伝送の問題により、可用性と品質に影響する追加の問題が発生しました。 データソースとの通信が短期的に失われると、機器の状態はこの期間にわたって変化しなかったという合理的な仮定を立てることができますが、データが長い間存在しないと機器の状態が変化する可能性があり、この場合システムはその質問に対して明確な回答を与えることができません-その間に何が起こったのかデータが利用できない場合。 プロジェクトの結果、アルゴリズムが開発され、これらの状況やその他の非標準的な状況に対処できる顧客と合意しました。
その後、過小評価エラーが発生しないように、「不良」データを処理する別の反復がありました。 その後-すでに試運転。 2段階のテストの後に開始しました。 各生産サイトには独自の特性がありました。 最も興味深いのは、医師の仕事で探偵を半分で演奏することでした-信号の写真を取得し、機器の機能に関するデータを取得し、すべての派遣者と話をしなければなりませんでした...レベルと彼らの鉄の手、そして経験を共有し始めました。 システムの計算を手動で多数チェックし、各不一致の原因を追跡しました。 その結果、さまざまな非標準的な状況を処理できるアルゴリズムが開発され、合意されました。 さまざまなタイプの機器に対応するため、デッドタイム、許容誤差などの追加の調整パラメーターがアルゴリズムに導入されました。 新しい機器の場合、ユーザーはシステム全体のレベルと、機器またはグループの個々のユニットのレベルの両方でアルゴリズムを微調整できます。個々のユニットの動作も異なるためです。
その結果、精度はほんの一瞬であり、私たちにとっても生産にとっても非常にクールです。 次のステップは、直接関与せずに、ディスパッチャによって独立してスケーラビリティをチェックすることです。
特定の生産では、マシンはSAPに表示された直後に質問され始めます。 一般に、そのようなシステムは、ERPにまったく触れることなく構築できます。ご覧のように、システムには独自のレポートがあります。 単純に、この場合、顧客がERPで負荷と修理を再配分する方が便利です。 ちなみに、MROデータの送信要件は数回変更されましたが、計画的なアップグレードがありましたが、これは一般に正常です。
もちろん、サービスアラームが物理ノードに送られる下位レベルに登らなかったのは非常にクールです。これにより、プロジェクトが通常のノードよりもはるかに安くなりました。
結果を金銭的に評価することは困難ですが、顧客は計画に従って無駄な修理がなくなることを確実に知っています。
まとめ
一般に、このような実験はどの生産でも繰り返すことができます。 このプロジェクトでは、PI Systemプラットフォームをデータ交換の基礎として使用し、さらに多くの開発を行いました。 たとえば、私たちはシステムとMROの相互作用のためのサービスと、診断情報を視覚化し、レポート(AWP)を作成するためのツールを開発する必要がありました。
しかし、一般に、WonderWare(Wonderware System Platform)、Iconics(ICONICS Genesis)、Tibbo(台湾系ロシアのベンダー、プラットフォームはAggregateと呼ばれる)などのベンダーのソリューションに基づいて、同様のことを行うこともできます。 しかし、主な特徴は、もちろん、プロジェクトを正常に完了するために、必ずしも完全ではない一貫したサービスシグナリングデータのアルゴリズム化の経験と、大規模生産での実際の経験が非常に望ましいことです。
繰り返しますが、施設にはすでにMROモジュールがありました。 ただし、一般的にこれは必要ありません。たとえば、データをアップロードする代わりに、Webレポートを使用することもできます(ユーザーはシステムのステータスを監視し、レポートを生成し、データを受信およびダウンロードし、収集するタグの存在を制御し、手動送信を実行し、システムを構成できます)-ソリューションのこの部分は、ASP.NET、C#に基づいたMicrosoft .NET Frameworkで作成されました。 フロントエンド-HTML5。
結果:
- 計算の実行に必要な初期データの収集。
- ACS TPから収集されたデータに基づく稼働時間の計算。
- 確立された規制時間枠内の稼働時間パラメーターの送信。
- システムの構成に必要なMROシステムからデータを取得します。
- システム管理者に、ACS TPおよびSAPからデータを受信する際のエラーを制御し、システムのソフトウェアとハードウェアを診断し、レポートを生成し、統計を収集および表示するためのインターフェースを提供します。
一般に、サーバーをサーバーの隣に置き、マシンの稼働時間に関する正確な計算を受け取りました。 次-データの統合、処理などに関するすべて-概して、探偵小説とアルゴリズム。 その結果、必要な生産自動化およびエンタープライズ管理システムと相互作用する稼働時間データの正確なソースが得られます。 これは依然として必要な官僚的な機能を備えた大規模な生産グループであるという事実に関連する多くの苦痛がありましたが、これは私たちのプロジェクトによると、むしろおなじみのワークフローです。 一般的に、機器の多くの兆候と、実際には元に戻さなければならない技術文書の不在を除いて、驚きはありませんでしたが、これは最初から想定されていました。
そんな感じです 生産の詳細に関係のない質問がある場合(植物がどこにあるかを話す権利さえありません)、喜んでコメントに答えます。 質問がコメント用でない場合は、sbannikov @ croc.ruに連絡してください。