
Habrには、ニューラルネットワーク、参照ベクトルマシン、ランダムツリーなど、機械学習法によるパターン認識に関する記事が既に多数あります。 それらはすべて、パラメータのトレーニングと調整のためにかなりの数の例を必要とします。 適切なボリュームの画像のトレーニングおよびテストデータベースを作成することは、非常に簡単な作業です。 これは、100万枚の画像を収集して保存することの技術的な問題ではなく、システム開発の最初の段階で1.5枚の画像があるという永遠の状況に関するものです。 さらに、トレーニングベースの構成は、他のすべての要因よりも結果として生じる認識システムの品質に影響を与える可能性があることを理解する必要があります。 それにもかかわらず、ほとんどの記事では、この重要な開発段階は完全に省略されています。
このすべてについて学ぶことに興味があるなら、猫へようこそ。
サンプル画像のデータベースを作成し、ニューラルネットワークをトレーニングする前に、技術的な問題を特定する必要があります。 手書きテキストの認識、人間の顔の感情、または写真の場所がまったく異なるタスクであることは明らかです。 また、使用するニューラルネットワークのアーキテクチャがプラットフォームの選択によって影響を受けることも明らかです。クラウド、PC、モバイルデバイスなど、利用可能なコンピューティングリソースは規模によって異なります。
さらに興味深いことになります。 高解像度カメラから取得した画像やオートフォーカスのないウェブカメラからのぼやけた画像の認識には、トレーニング、テスト、検証にまったく異なるデータが必要です。 これは、「無料データの欠如に関する定理」によって示唆されています。 そのため、無料で配布される教育用画像データベース([ 1、2、3 ]など)は学術研究には優れていますが、「一般性」のために実世界の問題にはほとんど適用されません。
トレーニングサンプルがシステムに入力される画像の一般的なセットをより正確に近似すればするほど、結果の最高の達成可能な品質が高くなります。 正しくコンパイルされたトレーニングサンプルは、まさに最も具体的な技術タスクであることがわかりました! たとえば、モバイルデバイスで撮影した写真の印刷された文字を認識したい場合、サンプルのベースには、異なるモデルの電話やカメラで撮影した、異なる照明の異なるソースからのドキュメントの写真を含める必要があります。 これはすべて、認識エンジンのトレーニングに必要な数のサンプルの収集を複雑にします。
ここで、認識システムを作成するために画像のサンプルを準備するいくつかの可能な方法を考えてみましょう。
自然画像からトレーニング例を作成します。
自然画像から学習する例は、実際のデータに基づいて作成されます。 それらの作成は、次の手順で構成されます。
- グラフィックデータのコレクション(対象オブジェクトの撮影、カメラからのビデオストリームの削除、Webページ上の画像の一部の強調表示)。
- フィルタリング-多くの要件について画像をチェックします:それら上のオブジェクトの十分なレベルの照明、必要なオブジェクトの存在など。
- マーキング用ツールの準備(独自の作成または完成品の最適化)。
- マークアップ(四角形の選択、必要な知識、画像の関心領域)。
- 各画像にラベルを割り当てる(画像内のオブジェクトの文字または名前)。
これらの操作には作業時間の多大な投資が必要であるため、トレーニングベースを作成する同様の方法は非常に高価です。 さらに、照明、電話のモデル、調査が行われるカメラ、さまざまな文書ソース(印刷所)など、さまざまな条件でデータを収集する必要があります。
これはすべて、認識エンジンのトレーニングに必要な数のサンプルの収集を複雑にします。 一方、このようなデータでシステムをトレーニングした結果によれば、実際の条件での有効性を判断できます。
人工画像からのトレーニング例の作成。
トレーニングデータを作成する別のアプローチは、その人工生成です。 いくつかのテンプレート/「完璧な」サンプル(フォントセットなど)を取得し、さまざまな歪みを使用して、トレーニングに必要な数のサンプルを作成できます。 次の歪みを使用できます。
- 幾何学的(アフィン、射影、...)。
- 明るい/色。
- バックグラウンド置換。
- 解決される問題に特徴的な歪み:グレア、ノイズ、ぼかしなど
文字認識タスクの画像の歪みの例:
シフト:
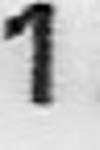
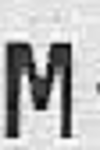
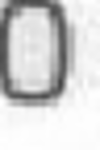

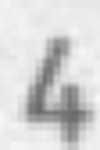

ターン:





画像の追加行:






グレア:








ピンぼけ:






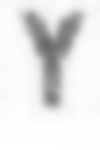
軸に沿った圧縮と張力:



画像[ 1、2、3 ]を操作するためのライブラリ、または人工的なドキュメントやオブジェクト全体を作成できる特別なプログラムを使用して、歪みを生成できます。
このアプローチは、大量の人的資源を必要とせず、マークアップとデータ収集を必要としないため、比較的安価です。画像データベースを作成するプロセス全体は、アルゴリズムとパラメーターの選択によって決定されます。
この方法の主な欠点は、生成されたデータに関するシステムの品質と実際の状態での作業の品質との関係が弱いことです。 さらに、この方法では、必要な数のサンプルを作成するために大きな計算能力が必要です。 特定のタスクのベースを作成する際に使用される歪みの選択も、特定の困難です。
以下は、完全に人工的なベースを作成する例です。
初期フォント文字画像セット:


背景の例:




歪みのない画像の例:





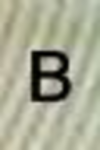

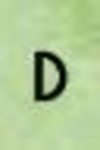
少し歪みを加える:

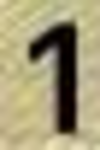

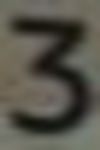



自然画像から生成された人工トレーニングの例を作成します。
前の方法の論理的な継続は、テンプレートと最初の「理想的な」例の代わりに実際のデータを使用した人工的な例の生成です。 歪みを追加することにより、認識システムの大幅な改善を実現できます。 どの歪みを適用する必要があるかを正確に理解するには、検証に実際のデータの一部を使用する必要があります。 これらを使用して、最も一般的なタイプのエラーを評価し、対応する歪みのある画像をトレーニングベースに追加できます。
このトレーニングサンプルの作成方法には、上記の両方のアプローチの利点が含まれています。高い材料費を必要とせず、レコグナイザーのトレーニングに必要な多数のサンプルを作成できます。
最初の例からトレーニングサンプルの「膨張」パラメータを選択するのが難しいと、問題が生じる可能性があります。 一方では、ニューラルネットワークがノイズの多い例を認識することを学習するのに十分な数のサンプルが必要であり、他方では、他のタイプの複雑な画像の品質が低下しないことが必要です。
完全に人工的で、自然な画像を使用して生成された自然な画像の例を使用して、ニューラルネットワークのトレーニングの品質を比較します。
MRZシンボル画像でニューラルネットワークを作成してみましょう。 機械可読ゾーン(MRZ)は、 Doc 9303-国際民間航空機関の機械可読旅行文書に記載されている国際的な推奨事項に従って作成されたID文書の一部です。 MRZ認識の問題については、他の記事をご覧ください 。
MRZの例:

MRZには88文字が含まれています。 システムの品質の2つの特性を使用します。
- 誤って認識された文字の割合。
- 完全に正しく認識されたゾーンの割合(MRZは、その中のすべての文字が正しく認識された場合、完全に正しく認識されたと見なされます)。
将来的には、ニューラルネットワークはモバイルデバイスで使用されることになっています。モバイルデバイスでは、計算能力が制限されているため、使用されるネットワークの層と重みは比較的少数になります。
実験のために、800'000の記号の例が収集され、3つのグループに分けられました。トレーニング用の200'000の例、検証用の300'000の例、テスト用の300'000の例です。 このようなパーティションは、ほとんどの例が「無駄」(検証とテスト)であるため不自然ですが、さまざまな方法の長所と短所を最もよく示すことができます。
テストサンプルの場合、さまざまなクラスの例の分布は実際に近く、次のようになります。
クラス名(シンボル):例の数
0:22416 1:17602 2:13746 3:8115 4:8587 5:9383 6:8697 7:8082 8:9734 9:8847
<:110438 A:12022 B:1834 C:3891 D:2952 E:7349 F:3282 G:2169 H:3309 I:6737
J:934 K:2702 L:4989 M:6244 N:7897 O:4515 P:4944 Q:109 R:7717 S:5499 T:3730
U:4224 V:3117 W:744 X:331 Y:1834 Z:1246
自然な例のみで学習する場合、25回の実験の平均シンボリックエラー値は0.25%でした。 正しく認識されていない文字の総数は、300,000枚の画像のうち750でした。この場合、正しく認識されたゾーンの数は80%であるため、実用上、この品質は受け入れられません。
ニューラルネットワークで発生する最も一般的なタイプのエラーを検討してください。
誤って認識された画像の例:





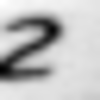
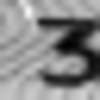




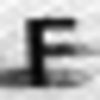

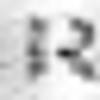
次のタイプのエラーを区別できます。
- 中心から外れた画像のエラー。
- 回転した画像のエラー。
- 線のある画像のエラー。
- フレア画像のエラー。
- 難しい場合のエラー。
最も一般的なエラーの表:
(元のシンボル形式、エラーの数、ネットワークで最も頻繁にこのシンボルと混同されるシンボルとその回数)
元の文字: '0'、エラー数:437
「O」:419、「U」:5、「J」:4、「2」:2、「1」:1
元の文字: '<'、エラー数:71
「2」:29、「K」:6、「P」:6、「4」:4、「6」:4
元の文字: '8'、エラー数:35
「B」:10、「6」:10、「D」:4、「E」:2、「M」:2
元の文字: 'O'、エラー数:20
「0」:19、「Q」:1
元の文字: '4'、エラー数:19
「6」:5、「N」:3、「¡」:2、「A」:1、「D」:1
元の文字: '6'、エラー数:18
「G」:4、「S」:4、「D」:3、「O」:2、「4」:2
元の文字: '1'、エラー数:17
「T」:6、「Y」:5、「7」:2、「3」:1、「6」:1
元の文字: 'L'、エラー数:14
「私」:9、「4」:4、「C」:1
元の文字: 'M'、エラー数:14
「H」:7、「P」:5、「3」:1、「N」:1
元の文字: 'E'、エラー数:14
「C」:5、「I」:3、「B」:2、「F」:2、「A」:1
トレーニングセットで最も一般的なタイプのエラーに対応するさまざまなタイプの歪みを徐々に追加します。 追加される「歪んだ」画像の数は、検証サンプルの逆応答に基づいて変化し、選択する必要があります。
次のスキームに従って行動します。
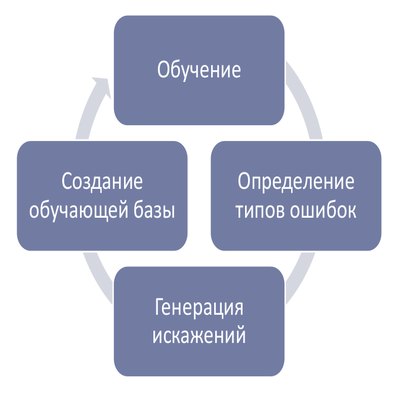
たとえば、このタスクでは、次のことが行われました。
- 「中心を外れた」画像のエラーに対応する「シフト」歪みを追加します。
- 一連の実験の実施:いくつかのニューラルネットワークのトレーニング。
- テストサンプルの品質評価。 MRZ認識品質が9%向上しました。
- 検証サンプルで最も一般的な認識エラーの分析。
- 追加のラインを含む画像をトレーニングベースに追加します。
- 再び一連の実験。
- テスト。 テストセットでのMRZの認識品質は3.5%向上しました。
このような「反復」は、必要な品質が達成されるまで、または品質が成長しなくなるまで繰り返し実行できます。
このようにして、正しく認識されたゾーンの94.5%で認識品質が得られました。 後処理(Markovモデル、有限状態マシン、N-gramおよびボキャブラリーメソッドなど)を使用すると、品質をさらに向上させることができます。
問題の人工データのみでトレーニングを使用する場合、正しく認識されたゾーンの81.72%で品質のみが達成されましたが、主な問題は歪みパラメーターの選択の難しさです。
| トレーニングデータタイプ | 正しく認識されたMRZの割合 | 文字エラー |
|---|---|---|
| 自然画像 | 80.78% | 0.253% |
| 自然画像+シフトのある画像 | 89.68% | 0.13% |
| +追加行のある画像 | 93.19% | 0.1% |
| +回転した画像 | 95.50% | 0.055% |
| 人工画像 | 78.53% | 0.29% |
おわりに
結論として、それぞれのケースで、トレーニングデータを取得するために独自のアルゴリズムを選択する必要があることに注意したいと思います。 ソースデータが完全に存在しない場合は、サンプルを人工的に生成する必要があります。 実際のデータを簡単に取得できる場合は、それらからのみ作成されたトレーニングセットを使用できます。 また、実際のデータがあまりない場合、またはめったにエラーが発生しない場合、最良の方法は一連の自然画像を膨張させることです。 私たちの経験では、後者のケースが最も一般的です。