
驚いたことに、明らかに、彼らはまだHabréでNMFについて書いていません。 この方法の歴史と一般的な情報はウィキペディアで入手できます。 しかし、最初に、なんらかの方法で分割表を変換する必要がある理由の質問に答えます。
テーブルの行と列の数が少ない場合、列または積み上げ棒グラフを使用した単純なグラフで、テーブルのデータを把握できます。 たとえば、変数「性別」とサイズ2x4の「過去1か月間のスポーツまたはフィットネスクラブへの訪問頻度(4つのカテゴリ)」の共通部分によって得られたテーブルを簡単に分析できます。 もう1つは、テーブルのサイズが大きくなった場合、たとえば20x30以上になる場合です。 テーブル内の数字のジャングルとグラフの列の森では、パターンを検出することは不可能または非常に困難です。 この場合、代替はNMFです。これは、分割表の次元を下げ、結果をヒートマップの形式で表示します。 これにより、非常に視覚的で解釈しやすい表のビューが得られます。
歴史的に、変換されたテーブルの構造をグラフィカルに表す最初の方法の1つは、コレスポンデンス分析 (CA)です。 主成分法に戻り、特異行列分解(SVD)に基づいています。 SVDについては、Habréのこの記事を読むことができます。 また、SVD定義を使用した優れたビデオと、コレスポンデンス分析の構築例についても説明します。 コレスポンデンス分析は一般的な方法ですが、私の意見では、非負行列の因数分解にはいくつかの利点があります。 これに関する考慮事項は、この記事の最後に記載されます。
以下は、分割表の分析に必要な因子分解の定義のみです。 テーブルVのサイズをmxnとします。 原則として、行列WとH のランクをrで表します。r<< min (n、m)です。 SVDのマトリックスの正確な表現とは異なり、NMFには近似的な等値しかありません
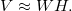
行列WとHは、損失関数を最小化するような方法で選択されます。D(V、WH) -> min。 私たちの場合、 Dはカルバック・ライブラーの発散に基づいて設定されます
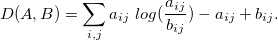
問題はランクrの選択にあります。 rを推定する方法はいくつかあります(たとえば、 k- meansメソッドのパラメーターkの場合)。 しかし、 rの選択は研究者/ユーザーの裁量、テーブルの構造が最も理解可能で、単純で、適切で、最適であるランクに任せたほうが良いです。
R環境には、非負行列の因数分解、分解の視覚化、およびその診断のためのいくつかのアルゴリズムを実装するパッケージnmf [1]があります。 NMFの機能は、 欧州社会調査(ESS)の第6ラウンドのデータで実証されます。 以前の出版物は、このデータをRにロードする方法を示しました。
2012年のESSプロジェクトには29か国が参加しました。 特に、アンケートには、人間の価値の重要性に関する21の質問が含まれており、6つの値のスケールがあります。「とても似ている」から「まったく好きではない」まで。 これら21個のシングルレスポンス変数のそれぞれを論理変数に変換します。 この変数は、この値が重要である回答者に対して「True」を受け入れます。「Very much like me」および「Like me」です。 他のすべての回答者-疑いのある人、この値を共有していない人または回答しない人の場合、変数の値はFalseになります。
人口を「20〜45歳の男性」と定義します。 回答者の重みを考慮して、これらの論理変数と調査の29か国のそれぞれとの共通部分の表を作成します。 サイズ29x21のテーブルを取得します。
分割表は拡張された意味で認識され、人間の値に関する多重応答変数が含まれていることに注意してください。 さらに、遺伝子のサイズ。 各国の人口は異なります。 テーブルのこれら2つの機能により、行を遺伝子のサイズに正規化することが重要です。 国の人口。 つまり、この表は、ESS調査の各国におけるサポート値の加重平均値で構成されています。 これは彼女の断片です

テーブルを構築し、ランク5の因子分解を見つけるためのコード。
研究データは既にダウンロードされており、オブジェクトの名前は変更されていません。
人間の価値に関する質問に対応する研究ベースの変数の名前をリストします
データベースに論理変数を追加し、数値型に変換し、回答者の重みを掛けます
必要なテーブルを作成します(cntry.human.valuesで示されます)
そして、非負のランク5行列を因数分解します
人間の価値に関する質問に対応する研究ベースの変数の名前をリストします
human.values <- c("ipcrtiv", "imprich", "ipeqopt", "ipshabt", "impsafe", "impdiff", "ipfrule", "ipudrst", "ipmodst", "ipgdtim", "impfree", "iphlppl", "ipsuces", "ipstrgv", "ipadvnt", "ipbhprp", "iprspot", "iplylfr", "impenv", "imptrad", "impfun")
データベースに論理変数を追加し、数値型に変換し、回答者の重みを掛けます
weighted.human.values<-paste(human.values,"w",sep="_") add.binary.human.values<-function(){ adding.variables<-paste("srv.data[,c('", paste(weighted.human.values, collapse = "','"), "'):=list(", paste("as.numeric(",human.values, " %in% c( 'Very much like me', 'Like me' )) *dweight", collapse = ", " ), ")]", sep="") eval(parse(text=adding.variables)) return(T) } add.binary.human.values()
必要なテーブルを作成します(cntry.human.valuesで示されます)
target.audience.data <- srv.data[gndr == 'Male' & agea >= 25 & agea<=40, c(weighted.human.values,'dweight', 'cntry'), with=FALSE] cntry.human.values <- t(sapply(unique(target.audience.data[,cntry]), function(x) colSums(target.audience.data[J(x)][,weighted.human.values,with=FALSE]))) cntry.pop.sizes <- target.audience.data[,list(W.Total=sum(dweight)),by=cntry] cntry.human.values <- cntry.human.values/cntry.pop.sizes[,W.Total]*100 rownames(cntry.human.values) <- c("Albania", "Belgium", "Bulgaria", "Switzerland", "Cyprus", "Czech Republic", "Germany", "Denmark", "Estonia", "Spain", "Finland", "France", "United Kingdom", "Hungary", "Ireland", "Israel", "Iceland", "Italy", "Lithuania", "Netherlands", "Norway", "Poland", "Portugal", "Russia", "Sweden", "Slovenia", "Slovakia", "Ukraine", "Kosovo") colnames(cntry.human.values) <- sub(srv.variables[J(human.values)][,title], pattern = "Important to |Important that ", replacement = "")
そして、非負のランク5行列を因数分解します
nmf.fit <- nmf(cntry.human.values, 5, method = "brunet", seed=123456, nrun=100)
現在、マトリックスWおよびHのヒートマップを作成しています。 それらは、5つの潜在変数の空間で、研究された特性の分解を決定します。 セルが暗いほど、潜在変数と値または国との対応がより顕著になります。 正確な定義の数学的な詳細は省略していますが、詳細は[1]に記載されています。
次に、この空間のいずれかの軸に沿ってのみ表現されるhuman.values変数のみを選択します。 軸の名前は私から独立して与えられます。
プロファイルマップの作成
nmf.selected <- nmf.fit[, c(2, 7:10, 13, 15, 21)] basismap(t(nmf.selected), tracks=NA, main="Latent variables: Profiles explanation", scale = "r1", legend = NA, Rowv=TRUE, labCol = c("money | success", "have good time", "be humble & modest", "advantures | fun", "rules | understanding"))

最終結果を以下に示します-29か国すべてのプレゼンテーション。 変数の一致度は色で表されます。 さらに、潜在的な変数の5次元空間でユークリッドメトリックを使用した階層クラスタリングに従って国がグループ化されます。
非表示のテキスト
基底マップ(nmf.selected、tracks = NA、main =「潜在変数空間の国」、
凡例= NA、labCol = c(「お金|成功」、「楽しい時間を」、「謙虚で控えめな」、
«利点| 楽しい "、"ルール| 理解»))
凡例= NA、labCol = c(「お金|成功」、「楽しい時間を」、「謙虚で控えめな」、
«利点| 楽しい "、"ルール| 理解»))
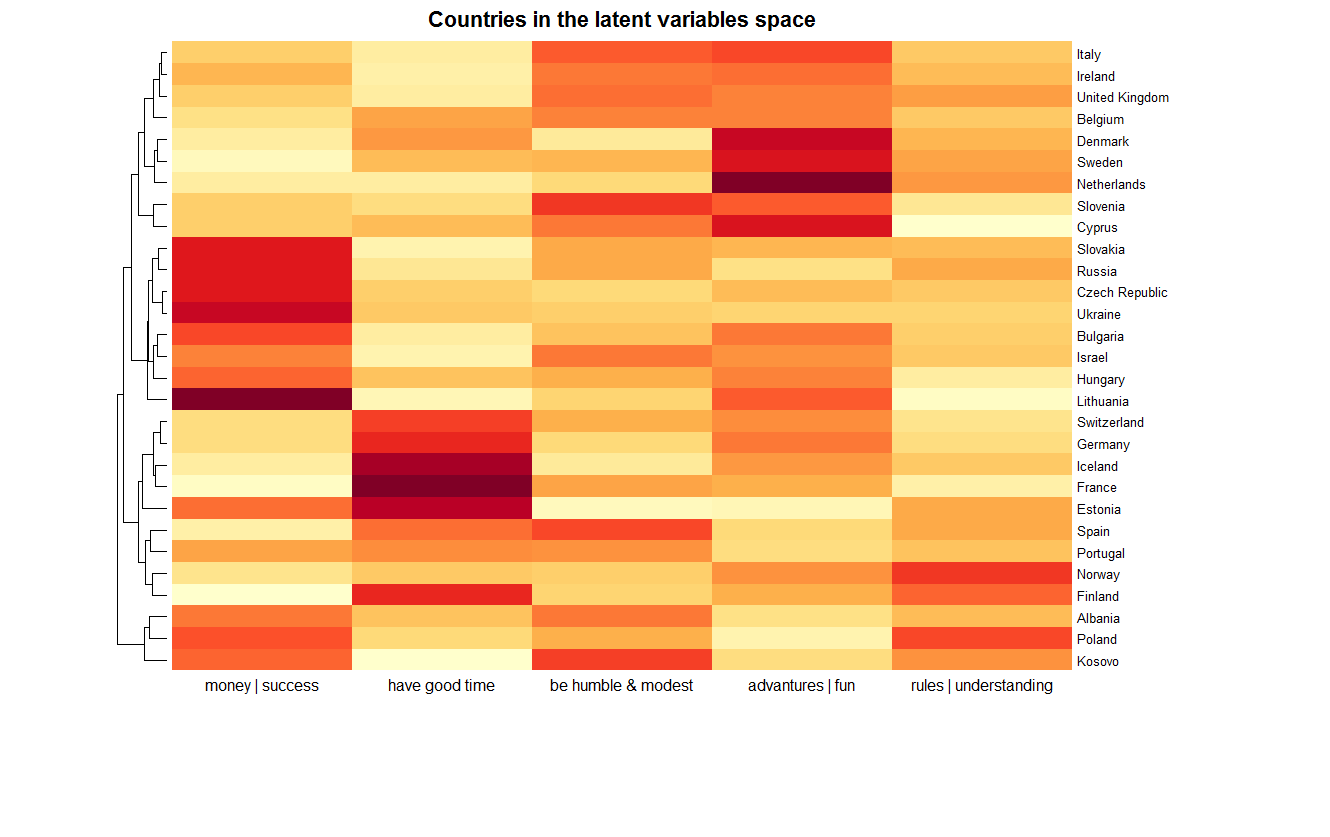
この空間でロシアに最も近い国はスロバキアであることがわかります。 特に、これらの国は、第1軸に沿った厳しさで区別されます。たとえば、フランスについては言えません。 この点については、記事の次の部分でさらに詳しく検討します。 グラフには、必要な詳細に応じて、クラスターを構成する国も示されます。 たとえば、東ヨーロッパ(スロバキア、ロシア、チェコ共和国、ウクライナ、ブルガリア、ハンガリー、リトアニア)およびイスラエルからのクラスター。 アルバニア、コソボ、...ポーランドの好奇心が強いクラスター。 また、ノルウェーとフィンランドはデンマークからかなり離れており、スウェーデンもあります。
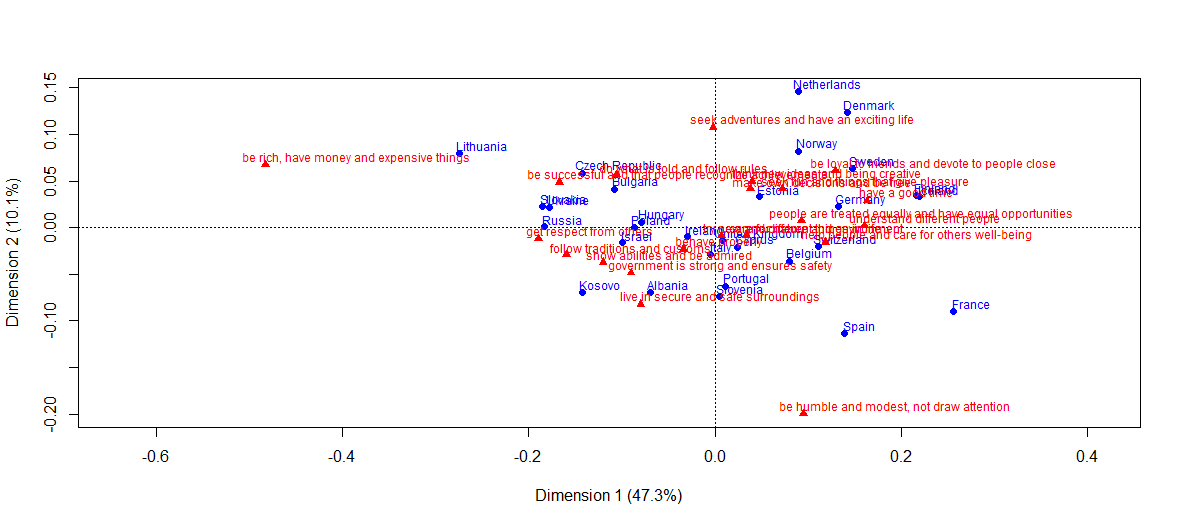
マッチング結果との比較
NMFの利点は何ですか?
-NMFとは異なり、対応の古典的な分析のグラフ表示では、2つの固有値のみが使用されます(上のグラフでは、CA軸の累積慣性は57.4%です)。 NMFでは、ランクが2を超えると視覚化も表示されます。
-第二に、ヒートマップは、CAプレーンよりも構造化された視覚的な方法で情報を表示します。
library(ca) plot(ca(cntry.human.values), what=c("all", "active"))
NMFの利点は何ですか?
-NMFとは異なり、対応の古典的な分析のグラフ表示では、2つの固有値のみが使用されます(上のグラフでは、CA軸の累積慣性は57.4%です)。 NMFでは、ランクが2を超えると視覚化も表示されます。
-第二に、ヒートマップは、CAプレーンよりも構造化された視覚的な方法で情報を表示します。
この出版物には、分割表のマーケティングにNMFを使用する方法が記載されています。 14の自動車ブランドの認識の分析例を検討しています。
NMFダイアグラムは、それらがどれほど優れていても、一般に、価値に関するアイデアに関するさまざまな国の類似点と相違点について決定的な結論を出す理由を与えません。 この問題は、記事の次のパートで検討されます。
参照:
[1] Renaud Gaujoux et al。 非負行列因数分解のための柔軟なRパッケージ。 In:BMC Bioinformatics 11.1(2010)、p。 367。