最近のBooking.comハッカソンでは、Perlインタープリターに整数を配置する機能を高速化する機会がありました。 成功した場合、これはプロジェクトで動作するほとんどすべてのプログラムを高速化するのに役立ちます。 アイデアの些細な実装でも機能することがわかったが、コードを維持する複雑さが増すだろう。 私たちの研究により、Cプリプロセッサにコードの品質を向上させると同時に、プログラムの実行を高速化することができました。
背景
perlgutsおよびPerlGuts Illustratedでは、Perlでの変数の表現は通常、ヘッダーと本文(構造体として表される)の2つの部分で構成されると書かれています。 ヘッダーには、可能なボディへのポインターなど、そのタイプに依存しない変数の処理に必要なデータが含まれています。
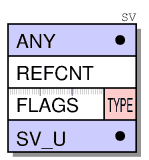
体の構造は、変数のタイプによって大きく異なります。 最も単純な変数はSvNULLです。これは、undefを表し、本体を必要としません。
文字列(PV-「ポインタ値」)の場合、本体のタイプはXPVです:
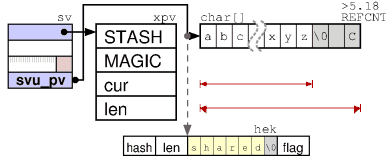
PVのボディ構造は、PVNVのボディとは異なります。 PVNVには、浮動小数点数と同じ値の文字列表現を含めることができます。
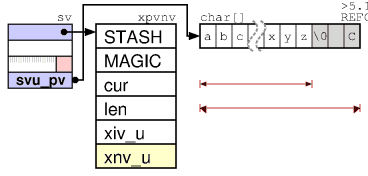
この設計の利点は、変数へのすべての参照がヘッダーにつながることです。 Perlは、本文の保存場所を自由に変更できます。これには、他のすべてのポインターを更新する必要はありません。
タイプの変更
Perlには型変換のための内部関数があります-これはsv_upgrade(「スカラー値のアップグレード」)です。 変数(たとえば整数)があり、別の型(たとえば文字列)の変数としてアクセスする必要がある場合、sv_upgradeは変数の型を変換します(たとえば、整数と文字列表現の両方を含む型に変換します)値)。 これには、現在のボディを大量に交換する必要がある場合があります。
sv_upgradeの実装方法を調べるには、sv.cのPerl_sv_upgrade関数を見てください。 関数は非常に複雑であり、コードにはさまざまな実装機能を説明するコメントがたくさんあることがわかります。 これは驚くことではありません-任意の型のスカラー値を取り、それを他の型が表すことができるビューに変換できるためです。
関数の最初に、変数の現在の型に応じて機能するスイッチがあります。これにより、新しい型に対して何を行う必要があるかが決まります。 そのすぐ後に、新しいタイプを解析する2番目のスイッチがあります。 2番目のブロックには、古いタイプに応じて異なる処理を行う多数のif {}ブロックが含まれています。 そして最後に、新しい本体の構造体を定義し、ヘッダーの構造体に正しいフラグを入力すると、古い本体が占有していたメモリが解放されます。
まだ寝ていない?
素朴なアプローチ
sv_upgrade関数はさまざまな場所から呼び出されます-文字列形式の整数の出力からだけでなく、以前にリセットされた変数に整数を割り当てるときにも。
無効化された変数は常にundefであり、本体はありません。 この場合のsv_upgradeは、新しい変数の本体を正しく構成するために呼び出されます。 これは正しい決定であり、1つの場所で変数を使用する特定の作業を減らし、本質を増やさない。 ただし、この決定は、いくつかの一般的な(この場合は冗長コード)の実行によりパフォーマンスに影響します。
NULL変数を整数に割り当てることは非常に頻繁に発生するため、パフォーマンスを向上させるためにコードの一部を複製できるようです。 コストを計算することにしました。 この場合、2行のコードのみを複製すれば、sv_upgrade呼び出しを完全に取り除くことができることがわかりました。 しかし、これらはコード内で重複しているわけではありません。 これらの2行。
1つ目は、これが新しいタイプであることがわかっているため、簡単です。
SvFLAGS(sv) |= new_type;
2番目はより困難です。
SvANY(sv) = (XPVIV*)((char*)&(sv->sv_u.svu_iv) - STRUCT_OFFSET(XPVIV, xiv_iv));
次のようなイラスト付きのperlgutsで説明されています。
バージョン5.10以降、純粋なIV(PVなし)の場合、IVXスロットはHEAD内にあり、xpviv struct( "body")にメモリは割り当てられません。 SvIVXマクロはSvANYポインター演算を使用して、コンパイル時にHEAD-1からsv_u.svu_ivまで計算される負のオフセットを示すため、PVIVとIVは同じSvIVXマクロを使用できます。
鉛筆と紙で15分たった後、私はこの行がコメントで説明されていることを正確に行うと確信しました。 その後、Illustrated Perl Gutsの図がより明確になりました。
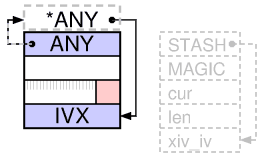
さらに、値が抽出されるたびに発生するif呼び出しを回避するために、この複雑さがすべて存在することに気付きました。
コードの別の部分に複雑な式を追加することで、速度を上げることができることがわかりました。 その結果、このようなコードをサポートする複雑さが増します。
ケーキを食べる方法
この複雑なコードをカプセル化したかったのですが、パフォーマンスは低下しませんでした。 Cを扱う場合、プリプロセッサを使用してすべてをマクロに詰め込みました。他の言語では、よく知られている関数またはメソッドの背後に複雑なコードを隠すように見えます。
#define SET_SVANY_FOR_BODYLESS_IV(sv) \ SvANY(sv) = (XPVIV*)((char*)&(sv->sv_u.svu_iv) - STRUCT_OFFSET(XPVIV, xiv_iv))
マクロを使用する利点は、パフォーマンス料金がコンパイル時にのみ請求され、実行中に何も影響を受けないことです。
そして、これは私たちの状況をどのように変えましたか? マクロを使用すると、2つのレンダリングされた行がより簡単になります。 その結果、パッチは呼び出しを置き換えるためだけに必要でした
sv_upgrade(dstr, SVt_IV);
次の2行で:
SET_SVANY_FOR_BODYLESS_IV(dstr); SvFLAGS(dstr) |= SVt_IV;
その結果、比較的単純なコードの削除により、速度が向上するはずです。 しかし、我々はそれを手に入れますか? これからの本当の利益は何でしょうか?
便益測定
ベンチマークは非常に具体的ですが、同時にかなり一般的なケースです。
$ dumbbench -i50 --pin-frequency -- \ ./perl -Ilib -e \ 'for my $x (1..1000){my @a = (1..2000);}'
そして、ここに仕事の結果があります。 最適化前:
Rounded run time per iteration: 2.4311e-01 +/- 1.4e-04
最適化後:
Rounded run time per iteration: 1.99354e-01 +/- 5.5e-05
18%の増加。 成功。
複雑さがゼロになる傾向があるこの最適化の必要性を実証しました。 一部の場所では、Perlコードはもう少し複雑になっていますが、sv_upgrade関数の内部は単純化されています。 このように行動すると、同様の方法で最適化を実現できる場所がさらにいくつか見つかりました。 その結果、Perlコードに5つのパッチを作成しました。
- bodyless-IV / NVハックをリファクタリングして定義する
- 以前にクリアしたSVへのIVの割り当てを高速化します
- newSVivの高速化()
- newSVuvのnewSViv最適化を繰り返します
- newRVにnewSViv / uv最適化をもたらす試み
この作業のおかげを含め、Perl 5.22のリリースでは、多くのプログラムがより高速に動作します。