この記事では、この構造の複雑さ、つまりデータベースレベルで行われること、クエリの最適化、およびデータベースヒントについて説明します。
非常に多くの場合、プログラマはABAPコードを記述するときにこの構成を使用します。 便利で、開発中の時間を節約できますが、誰もがそれがどのように機能するかを考えているわけではありません。 そしてある日、データ量の増加により、書かれたプログラムが「スローダウン」し始める瞬間があります。 ほとんどの場合、問題はデータベースクエリにあり、開発者はそれらの最適化を開始します。インデックスの追加、ループからのクエリの削除など。 しかし、彼はFOR ALL ENTRIES INの設計にほとんど注意を払っていません。最適化するものはないと考えているからです。
データベースレベルで何が起こるか
簡単な例を使用して、この構造の動作を分析しましょう。 BKPFテーブルから内部テーブルLT_BKPFの1000行を選択し、BSISテーブルからFOR ALL ENTRIES IN LT_BKPFコンストラクトを使用してデータを選択します。 同様の例は、公式のSAPヘルプで提供されています。
report z_test. " " data: begin of ls_bkpf, bukrs type bkpf-bukrs, belnr type bkpf-belnr, end of ls_bkpf. data: lt_bkpf like table of ls_bkpf. data: lt_bsis like table of bsis. " bkpf lt_bkpf " select bukrs belnr up to 1000 rows from bkpf into corresponding fields of table lt_bkpf where gjahr = '2013'. check lines( lt_bkpf ) > 0. " BSIS. FOR ALL ENTRIES IN LT_BKPF " select * from bsis into corresponding fields of table lt_bsis for all entries in lt_bkpf where bsis~bukrs = lt_bkpf-bukrs and bsis~belnr = lt_bkpf-belnr and bsis~gjahr = '2013'.
構造の動作を分析するには、トランザクションST05-SQLクエリトレースを使用します。
1つのモードで、ST05を開始し、トレースをオンにします(図1):
図 1トレースを開始
別のモードで、プログラムを実行します。 次に、ST05でトレースをオフにして、BKPFおよびBSISテーブルにフィルターを設定して結果を表示し(図2、図3、図4)、不要なガベージをフィルターで除外します。
図 2トレースを無効にする
図 3トレース出力
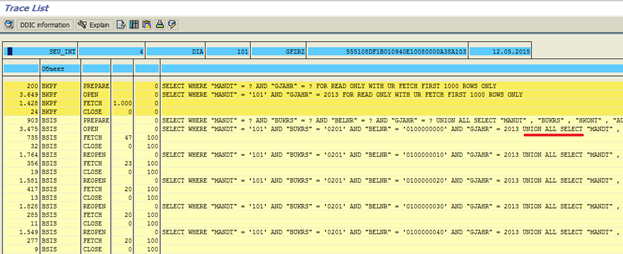
図 4トレース結果
BKPFテーブルのクエリを1つ実行し、1000行を返したことがわかります。ここではすべて問題ありません。 しかし、BSISテーブルに対しては100のクエリを完了し、各クエリにもUNION ALL SELECT構造を介して結合された10のクエリが含まれています。 これは、本質的に、実行時にFOR ALL ENTRIES INを持つ1つのOpen SQLクエリが1000の個別のデータベースクエリに変わることを意味します。 要約すると-FOR ALL ENTRIES INの内部テーブルにあるレコードの数は、非常に多くの個別のデータベースクエリになります。 大量のデータがある場合、これはすべて非常にゆっくりと動作することは明らかです。
最適化
パフォーマンスを向上させるには、プログラムのコードを少し複雑にする必要があります。
report z_test. " " data: begin of ls_bkpf, bukrs type bkpf-bukrs, belnr type bkpf-belnr, end of ls_bkpf. data: lt_bkpf like table of ls_bkpf. data: lt_bkpf_tmp like lt_bkpf. field-symbols: <wa_bkpf> like ls_bkpf. data: lt_bsis like table of bsis. data: begin of ls_bukrs, bukrs type bukrs, end of ls_bukrs. data: lt_bukrs like table of ls_bukrs. " BKPF LT_BKPF " select bukrs belnr up to 1000 rows from bkpf into corresponding fields of table lt_bkpf where gjahr = '2013'. check lines( lt_bkpf ) > 0. " LT_BUKRS " loop at lt_bkpf assigning <wa_bkpf>. ls_bukrs-bukrs = <wa_bkpf>-bukrs. collect ls_bukrs into lt_bukrs. endloop. " " loop at lt_bukrs into ls_bukrs. " LT_BKPF , LT_BKPF_TMP " clear lt_bkpf_tmp. loop at lt_bkpf assigning <wa_bkpf> where bukrs = ls_bukrs-bukrs. append <wa_bkpf> to lt_bkpf_tmp. endloop. " BSIS. FOR ALL ENTRIES IN LT_BKPF_TMP " select * from bsis appending corresponding fields of table lt_bsis for all entries in lt_bkpf_tmp where bsis~bukrs = ls_bukrs-bukrs and bsis~belnr = lt_bkpf_tmp-belnr and bsis~gjahr = '2013'. endloop.
私たちが行ったステップを書き留めます:
- 内部テーブルLT_BKPFを分析し、BUKRS列の値がほとんど繰り返されていることに気付きました。
- BUKRS列の一意の値をすべて内部テーブルLT_BUKRSに保存しました。
- クエリをBSISテーブルに再編集します。
- 一意のBUKRS値ごとに、特定のBU(BUKRS)のドキュメント番号を使用して内部テーブルLT_BKPF_TMPを事前に準備して、サイクルで個別のクエリを実行します。 このテーブルをLT_BKPFではなくFOR ALL ENTRIES INに渡します。
- INTO CORRESPONDING FIELDSはAPPENDING CORRESPONDING FIELDSに置き換えられたため、各ステップで内部テーブルLT_BSISを上書きせずにデータを追加します。
- WHEREブロックでは、テーブルLT_BKPF_TMPからフィールドが1つだけ残されました。
このようなコードの変更後のトレース結果を見てみましょう(図5、図6):

図 5コード最適化後のトレース結果
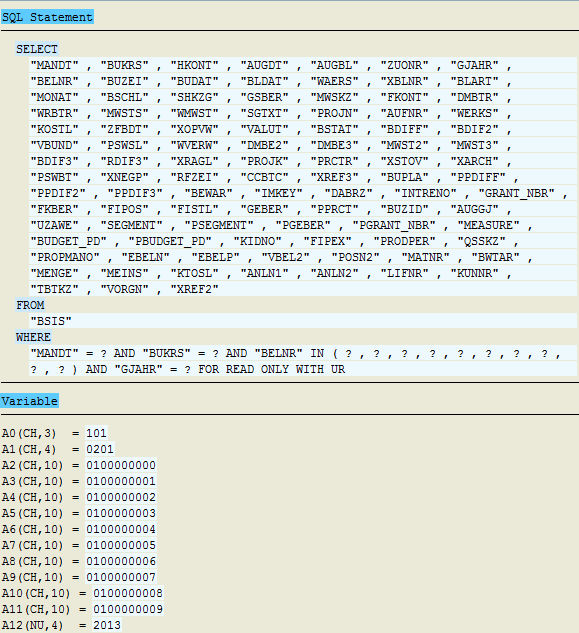
図 6コード最適化後のトレース結果(詳細)
UNION ALL SELECTを削除できたことがわかり、UNION ALL SELECTで結合された1000個のクエリの代わりに、IN演算子(クエリごとに10個の値)を使用してBSISテーブルに対して100個のクエリを実行できます。
そのようなクエリを最適化したとき、達成された結果は私にとって十分ではなかったので、正確に10個の値がIN演算子に渡された理由を見つけることにしました。 これはグローバル構成パラメーターSAP max_in_blocking_factorによって規制され、すべての要求に影響することが判明しましたが、いわゆるデータベースヒントを使用すると、この要求を実行する直前に特定の要求のこの設定を変更できます。 これを行うには、DBMSに応じて、 %_hints db2 '&max_in_blocking_factor 500&'または%_hints oracle '&max_in_blocking_factor 500&'をリクエスト自体に追加します。
select * from bsis appending corresponding fields of table lt_bsis for all entries in lt_bkpf_tmp where bsis~bukrs = ls_bukrs-bukrs and bsis~belnr = lt_bkpf_tmp-belnr and bsis~gjahr = '2013' %_hints db2 '&max_in_blocking_factor 500&'.
データベースヒントを追加すると、次の結果が得られます(図7)。
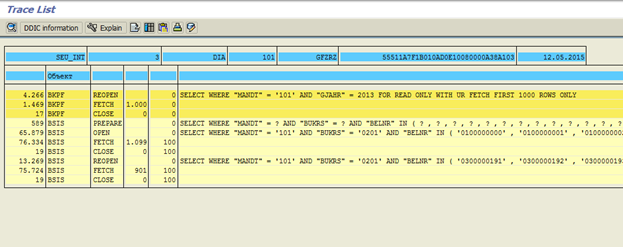
図 7データベースヒントを追加した後のトレース結果
1000個のクエリではなく、IN演算子(クエリごとに500個の値)を使用したBSISテーブルへのクエリが2つしかないことがわかります。
注意! max_in_blocking_factor設定は慎重に変更する必要があります。値が大きいほど、結果を保存するためにより多くのRAMが必要になります。 それぞれの特定のケースでは、生産性とリソース消費の間の妥協点を選択するために個別のアプローチが必要です。
シープスキンはろうそくの価値がありますか?
ほとんどの場合、多くの小さなクエリは、1つの大きなクエリよりも時間がかかります。 サンプリングがインデックス可能なフィールドによって実行される人工的な例でも、ほぼ4倍の速度が得られました。 非インデックスフィールドが選択に関与している場合(WHEREブロックで)、特別なパフォーマンスの向上が得られます。 私の実践では、大幅なコード調整や新しいインデックスの追加なしで、動作時間が50分から30秒に短縮されたレポートがありました。
要約する
- LOCAL_TABLE構造の FOR ALL ENTRIESを使用する場合、内部LOCAL_TABLEテーブルの1つのフィールドのみがWHEREブロックで使用されるようにしてください。
- LOCAL_TABLEテーブルが空でないことを常に確認してください。空でない場合、このテーブルのフィールドの条件は無視されます。
- データベースヒントを非常に慎重に使用してください。
- この方法でクエリを最適化するのは、内部LOCAL_TABLEテーブルの列に重複する値が多数含まれる場合にのみ意味があります。そうでない場合は意味がありません。
- 早すぎる最適化は、すべての悪の根源です(c)Donald Knuth。 本当に必要な場合にのみ最適化する必要がありますが、事前に方法を知っておいた方がよいでしょう。