今日は、 Power BI DesktopとPower BIでの収入と支出の計画事実分析を使用した簡単なダッシュボードの構築についてお話したいと思います。 最初の部分では、クエリの操作を検討し、複数のソースからのデータを結合し、それらをクリーニングする方法を学びます。
初期データ:しばらくの間、会社の収入と支出の指標に関する情報を保存するいくつかのExcelファイル。 レポートと会計記事の形式は数回変更されているため、情報シートは似ていますが、まったく同じ構造ではありません。 出口では、マネージャーが会社の財務状況で何が起こっているかを把握できるようなものを手に入れる必要があります。
Power BI Desktopを使用してデータを結合し、視覚化する方法を見てみましょう。
図1. Power BI Desktopの開始画面
起動時に、Power BI Desktopはデータソースを指定するか、最近のソースの1つを選択するように求めます。 ところで、ソースに関して-オンラインおよびローカルソースを含む多数のソースに接続することが可能です。 たとえば、Google Analytics。 この例では、すべてのレポートが1つのフォルダーに保存されるため、ソースとして「フォルダー」を選択します。 このような選択により、[更新]ボタンをクリックして、このフォルダーに新しいレポートをさらに追加し、分析のためにデータを読み込むことができます。
図2.データソースの選択
[接続]ボタンをクリックすると、データソースへのクエリの結果のプレビューウィンドウが表示されます。 データを「そのまま」ロードするか、「変更」ボタンをクリックしてクエリ編集モードに切り替えることができます。 ほとんどの場合、クエリ結果を処理する必要があります。
図3.クエリ結果のプレビュー
[変更]ボタンをクリックすると、[クエリエディター]ウィンドウが自動的に開きます。このウィンドウで、データのクリーニングと準備を実行できます。
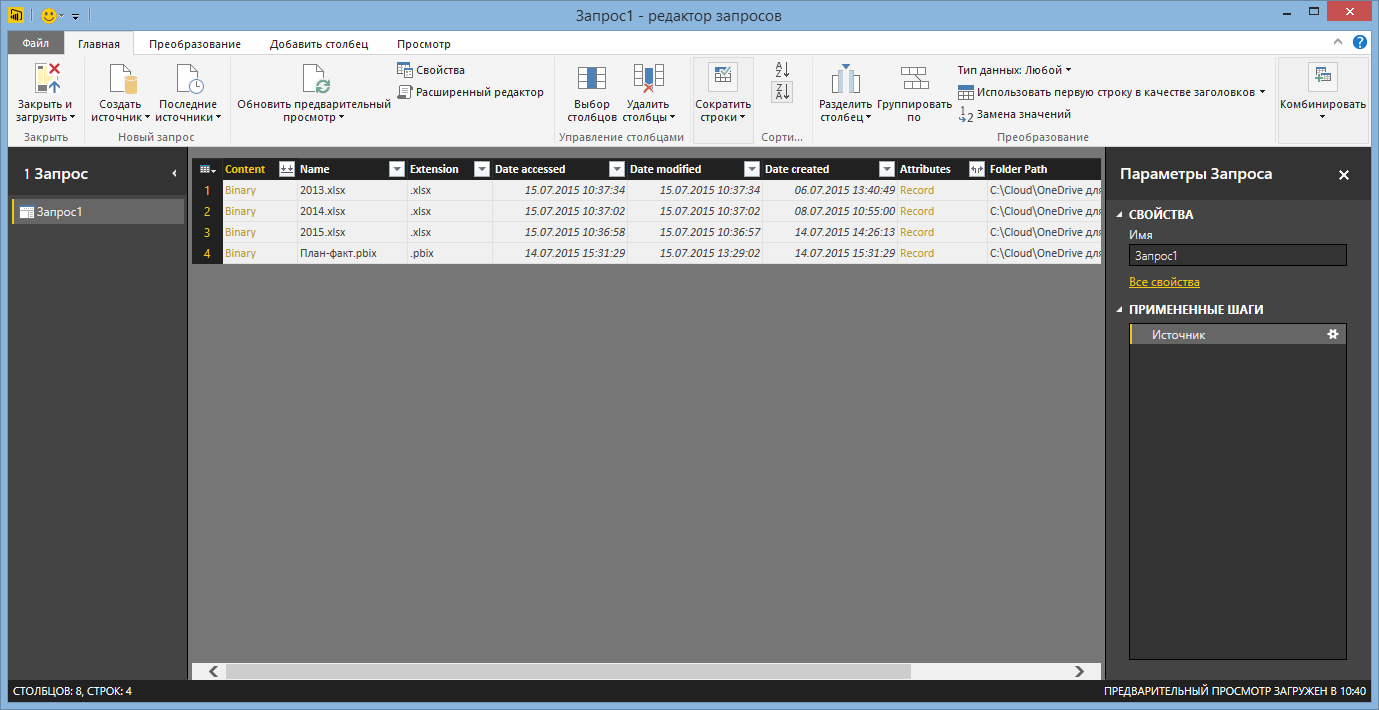
図4.クエリエディターウィンドウ
スクリーンショットでわかるように、Power BI Desktopはフォルダーとメインメタ情報からファイルをアップロードしました。 「コンテンツ」、「名前」、「拡張子」を除くすべての列を削除します。 ファイル名は、対応するレポートが属する年を示しているため、これに使用します。
[コンテンツ]列のいずれかの行をクリックすると、Power BI Desktopは対応するブックのコンテンツを開きます。 [リクエストパラメータ]セクションでは、完了したすべての手順が記録され、変更または削除できます。 [詳細エディター]ウィンドウを開くと、実行されたすべてのアクションのプログラムコードが表示されるウィンドウが開きます。 はい、Power BI Desktopには独自のプログラミング言語「M」があり、これは非常にクールです。
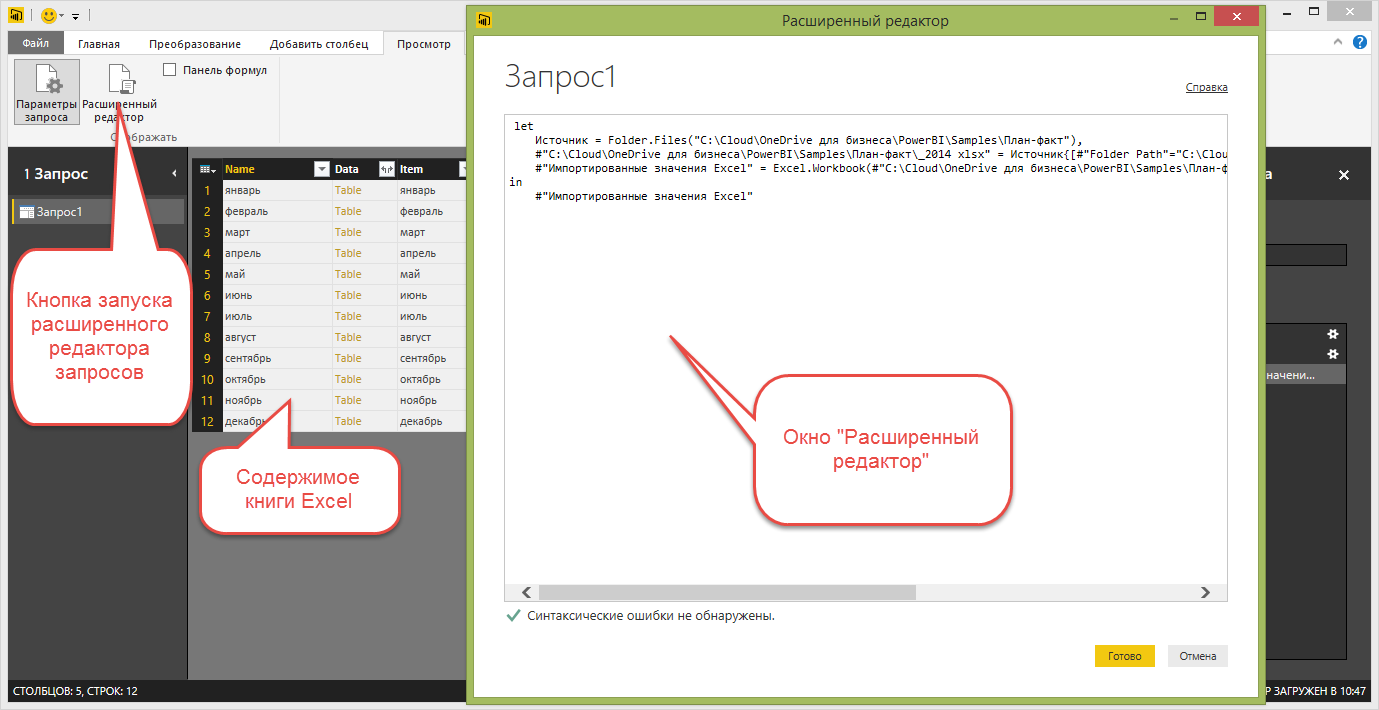
図5.高度なクエリエディター
レポートには1つだけでなくフォルダー内のすべてのExcelファイルの内容が必要なので、最後の2つの手順を削除し、「M」言語の機能を使用してフォルダーからExcelブックの内容を解析します。
データをさらに処理する前に、Excelファイルだけをフォルダーにロードできないことも考慮する必要があります。 したがって、「拡張」列にフィルターを適用する必要があります。これにより、不要なファイルの種類が排除されます。
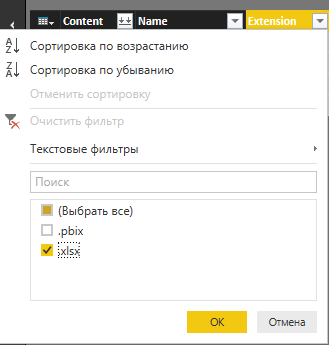
図6.フィルターアプリケーション
次に、Excelブックの内容を「抽出」する必要があります。 これを行うには、Excel.Workbook関数を使用して新しい列を追加します。これにより、Excelブックの内容を「抽出」できます。 新しい列には「テーブル」タイプの値が含まれます。これにより、その内容を他のいくつかの列に「展開」できます。 「デプロイ」するときに、表示する列を選択できます。 この場合、意味は「データ」列と「アイテム」列です。
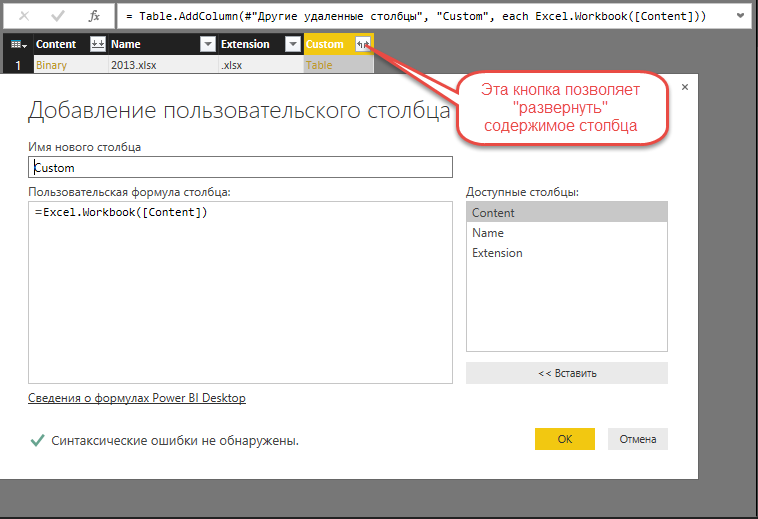
図7.カスタム列の追加
「データ」列にはExcelワークシートのデータが含まれており、今後はタイムスタンプに「名前」と「アイテム」を使用します。
「名前」列にはyyyy.xlsx(yyyyはレポートの年)という形式のデータが含まれているため、簡単な操作を実行して列内のデータを分離します。 区切りは、文字数と区切りの両方で実行できます。 この場合、列はセパレータで分割する必要があります。
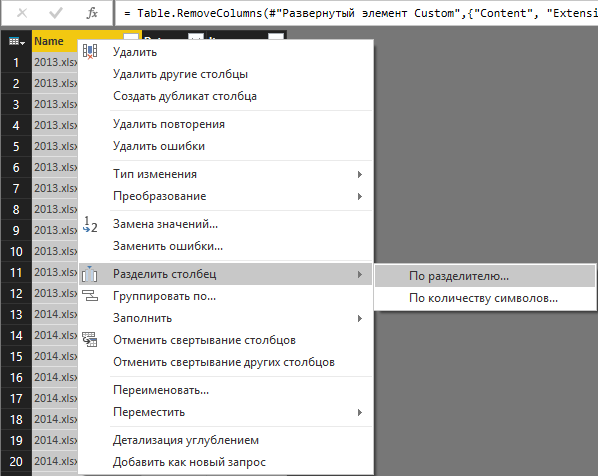
図8.列の分割
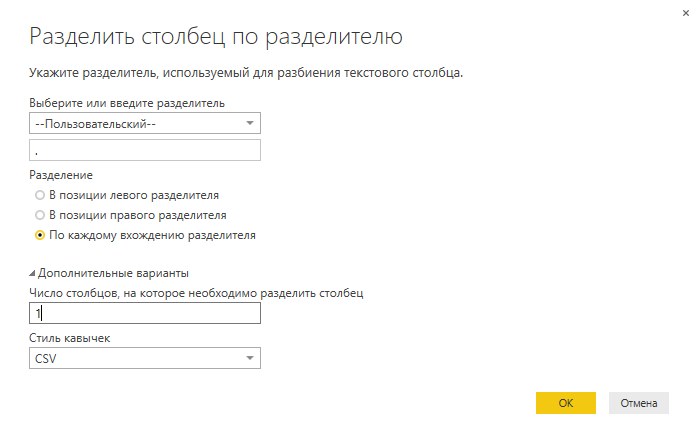
図9.列分割設定ウィンドウ
列を分割した後、名前を変更する必要があります。
図9.列分割設定ウィンドウ
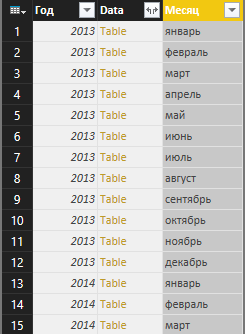
図10.「デプロイメント」リクエストの準備
次に、[データ]列を「展開」し、すべてのExcelファイルとシートの内容を、最終レポートの作成に適さない形式で表示します。 ただし、Power BI Desktopの機能を使用してデータを消去できます。
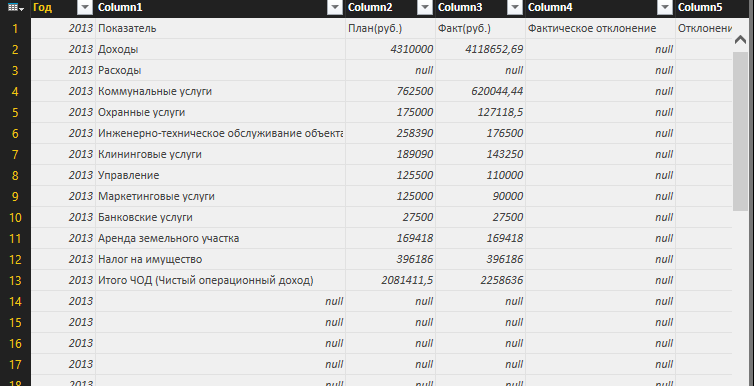
図11.ファイルの内容を「デプロイ」した後のリクエスト
1.一番上の行を見出しとして使用し、列の名前を変更します。 「実際の偏差」列と「%の偏差」列を削除します。 後で詳しく説明します。
2.空の値と「インジケータ」列の「インジケータ」値を含む行を削除して、フィルタリングを適用します。 同様に、合計値を含む行(「合計CHOD」、「合計」など)を削除します。
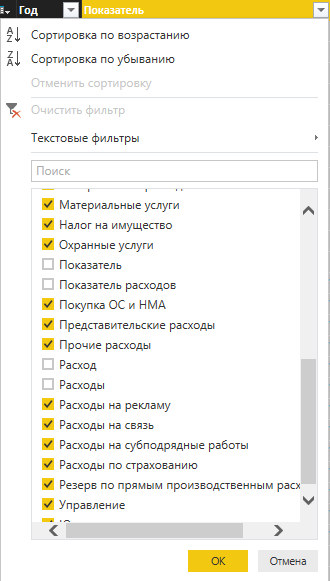
図12.データフィルタリングメニュー
3.「値の置換」機能を使用して、同義語、例えば「Income」と「Income」を置換します。
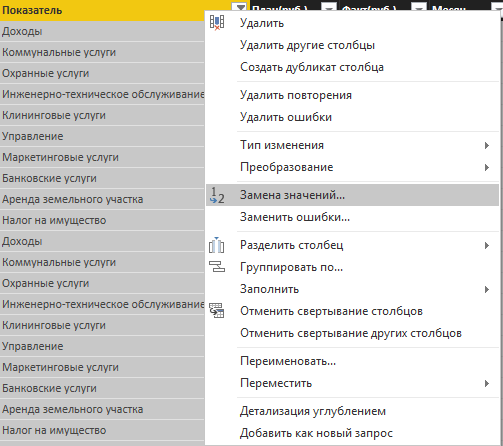
図13.値の置き換え
4.「指標」列の内容をもう少し調べてみると、私の収入はすべて「収入」または「収入」指標に関連していることがわかります。 他のすべてはコストに関連し、タスクを大幅に促進します。 さらに処理とフィルタリングを行うために、「カテゴリ」列を作成します。この列には、「インジケータ」列に「収入」という単語が存在する場合は「収入」という値が含まれます。

図14.カテゴリー列の追加
5.次に、「Plan」列と「Fact」列の値のタイプが10進数であることを示す必要があります。 しかし、その前に、これらの列の内容からスペースを削除する必要があります。
6.操作が完了したら、列のエラーと負の値を確認します。 私たちの場合、負の値の存在は入力エラーを意味するため、値変換関数を使用して、「Plan」列と「Fact」列の絶対値を強調表示します。 これで基本的なデータクレンジングが完了しました。
7.時間参照付きのインジケータを表示するには、各レコードの日付を指定する必要があります。 表には、テキスト形式の月と年が含まれています。 便宜上、データは毎月末に表示されると想定しています。 ここで問題に直面しています-言語「M」では現在、月の名前を日付に変換できません。 したがって、いくつかの中間ステップを実行する必要があります。
8.月の名前とその番号を含む新しいクエリを作成します。 これを行うには、空のリクエストを作成し、高度なエディターを開いて次のコードを貼り付けます。
let
Source = {"", "", "", "", "", "", "", "", "", "", "", ""},
#"Converted to Table" = Table.FromList(Source, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"Added Index" = Table.AddIndexColumn(#"Converted to Table", "Index", 0, 1),
#"Added to Column" = Table.TransformColumns(#"Added Index", {{"Index", each List.Sum({_, 1})}}),
#"Renamed Columns" = Table.RenameColumns(#"Added to Column",{{"Column1", ""}})
in
#"Renamed Columns"

図15.空のリクエストを追加する
9.クエリ「Plan-Fact」に目を向け、目的のタイプの関連付けを選択してクエリを結合します。
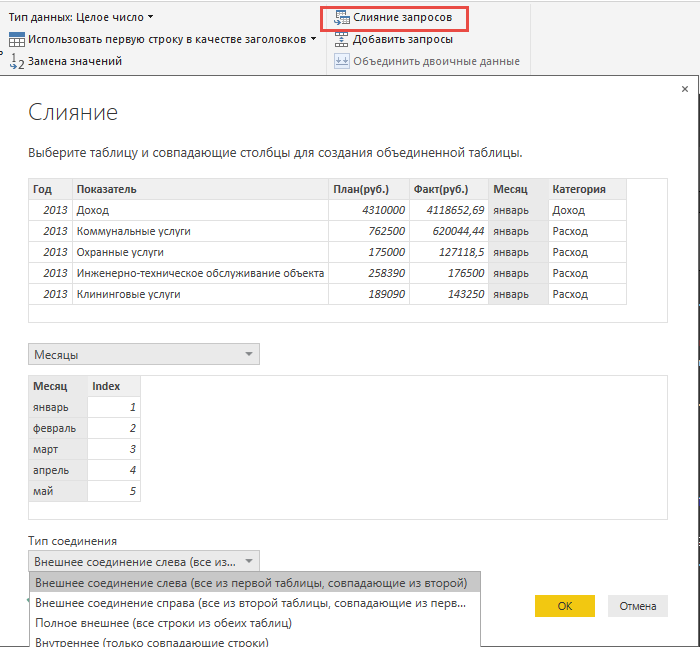
図16.クエリの統合
10.「Months」クエリのデータが新しい列として追加されました。 これを開くと、日付の形成に関するすべてのデータがあります。 次の式を使用して「Date」という新しい列を作成します。= Date.EndOfMonth(#date([Year]、[Index]、1))列が追加され、各月の最終日が含まれます。 Power BI Desktopで月と年で日付をグループ化するには、タイプを明示的に「日付」に設定する必要があります

図17.日付列の追加
11.列インデックス、年、月を削除します。 もう必要ありません。 次に、「閉じるとダウンロード」ボタンをクリックして、データのモデリングと視覚化に進む必要があります。
これでデータ処理の基本部分が完了し、視覚化に進むことができます。 Power BI Desktopでのデータ視覚化の可能性については、 次のパートで説明します。