私の質問に答えるために、私は少し経験をしました。5,000行を含む4つのフィールド(そのうち2つは検索に使用され、FULLTEXTによってインデックス付けされました)を持つテーブルを作成しました。 検索に使用されるフィールドには、1つの大きなテキストからランダムに選択された255文字が含まれていました。 検索は、4文字以上のランダムな単語でも実行されました。
最初の段階では、1つのフィールドで1つの単語が検索されました。 第2段階では、1つのフィールドで2つの単語のいずれかが検索されました。 第3段階では、2つの単語のうちの1つが両方のフィールドで検索されました。 すべての段階で、検索は最初にMATCH(field_name)AGAINST( 'searched_text')コンストラクトを使用して実行され、次にLIKEを使用しました。
注:自宅のコンピューターAMD 64 X2 4200、2GB RAM、Apache、MySQL 5.0でテスト済み。
各段階でのリクエストの数は100です。頻度-1秒に1回。
試験結果
このグラフは、検索クエリの平均実行時間を3段階で示しています。
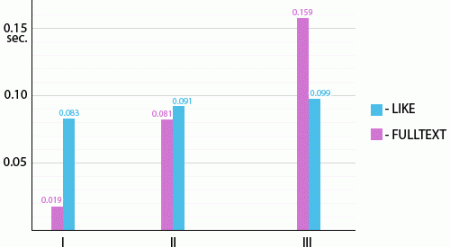
正直なところ、リクエストの複雑さにわずかに異なる時間依存性があり、検索クエリのタイプ間の明確な境界が予想されました。 しかし、これはFULLTEXTインデックスによる検索が単語の形態(追加のインストールおよびロシア語を含む)を考慮に入れているため、追加の負荷が発生するという事実によって説明されます。
長所と短所
LIKE演算子を使用した検索の利点:
- 要求の処理時間のわずかな増加とその複雑さの増加
- 結果をソートする機能
- 汎用性:フルテキストとは異なり、事実上あらゆるタイプのフィールドを検索するために使用できます
欠点のような:
- 形態サポートの欠如
- 修飾子の欠如
- すべての行を検索
全文検索の利点:
- 形態サポート
- 関連性の結果をリリースする
- GoogleおよびYandex検索の修飾子に類似した修飾子の存在
- 言葉を止める
- カスタマイズオプション
短所:
- ソートの欠如
- FULLTEXTインデックスを持つVARCHARおよびTEXTフィールドのみをサポートします
- リソース集約型プロセス
- MyISAMテーブルのみの初期サポート
- FULLTEXTキーが設定されている場合、データはより長くテーブルに追加されます
エピローグ
この実験は理想的であるとは主張していませんが、データベースサイズが小さい2つのタイプの検索の速度の違いをはっきりと示していると思います。 私の意見では、両方のオプションには異なる状況で存在する権利があります。
UPD:状況が異なると、テーブルの行数が異なるケースを意味します。 LIKE演算子は、膨大な数のレコードがなく、すべてのレコードで検索が実行されるため、数十万行のテーブルには適用できない場合に適しています。
PS:全文検索についてはこちらをご覧ください 。