
テスト方法
テスト中に、次のタスクが解決されました。
- 長い書き込み負荷(書き込みクリフ)によるストレージパフォーマンスの低下とストレージの満杯の影響の研究。
- さまざまな負荷プロファイルに対するIBM FlashSystem840ストレージパフォーマンスの調査。
テストベッド構成
テストのために、お客様のサイトで、2つの異なるスタンドが直列に組み立てられました。
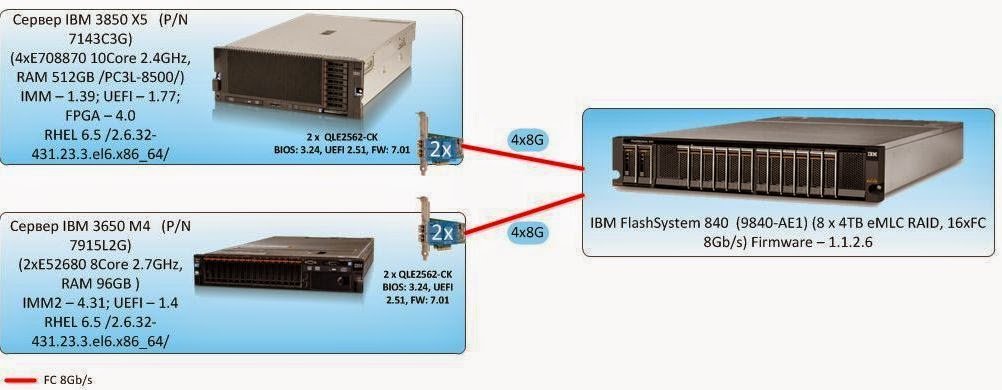
グループ1および2のテストの場合、負荷は1台のサーバーによって生成され、スタンドは図に示す形式になります。
 |
| 図1.テストベンチのブロック図1。 |
サーバー:IBM 3850X5、8つの8Gb FC接続で直接接続。 IBM FlashSystem 840用のストレージ
グループ3のテストでは、 IBM 3650M4サーバーを説明したスタンドに追加し、IBM Flash System 840ストレージシステムに直接接続しますこの段階で、各サーバーは4つの光リンクを介してストレージシステムに接続します。
 |
| 図2.テストベンチのブロック図2。 |
- 論理ボリュームマネージャー(Veritas Volume Manager)の機能。
- ディスクアレイへのフェールセーフ接続の機能(Dynamic Multi Pathing)
退屈な詳細とあらゆる種類のスマートワードを参照してください。
ディスクI / Oの遅延を減らすことを目的として、テストサーバーで次の設定を行いました。
ストレージシステムでは、ディスク領域をパーティション分割するための次の構成設定が実行されます。
ストレージシステムで合成負荷を作成(合成テストを実行)するには、Flexible IO Tester(fio)ユーティリティバージョン2.1.4を使用します。 すべての模擬テストでは、fioセクション[グローバル]の次の構成パラメーターが使用されます。
次のユーティリティは、合成負荷の下でパフォーマンスインジケータを取得するために使用されます。
パフォーマンスインジケータは、テスト中に5秒間隔で
によって
。
- I / O
cfq
は、Symantec VxVolume
scheduler
パラメータにnoop
値noop
割り当てることにより、noop
からcfq
にcfq
れcfq
た。 - 次のオプションが
/etc/sysctl.conf
追加され、Symantec論理ボリュームマネージャーレベルでキューのサイズが最小化されましたvxvm.vxio.vol_use_rq = 0
; - デバイスへの同時I / O要求の制限は、
Symantec VxVolume
nr_requests
パラメータに1024の値を割り当てることにより、1024までnr_requests
ます。 -
Symantec VxVolume
nomerges
パラメーターに値1を割り当てることにより、I / O操作のマージ(iomerge)の可能性のチェックを無効にしました。 - FCアダプターのキューサイズは、
ql2xmaxqdepth=64 (options qla2xxx ql2xmaxqdepth=64)
オプションql2xmaxqdepth=64 (options qla2xxx ql2xmaxqdepth=64)
構成ファイルに追加することにより増加しました。
ストレージシステムでは、ディスク領域をパーティション分割するための次の構成設定が実行されます。
- フラッシュRAID5モジュールの構成を実装しました。
- ストレージシステム上のグループ1および2のテストでは、同じボリュームの8つのLUNが作成され、合計ボリュームがディスクアレイの有効容量全体をカバーします。 LUNブロックサイズは512バイトです。 作成されたLUNは1つのテストサーバーに提示されます。 グループ3のテストでは、同じボリュームの16個のLUNが作成され、合計ボリュームがディスクアレイの使用可能な容量全体をカバーします。 作成されたLUNは、2つのテストサーバーのそれぞれに8個ずつ提示されます。
テストソフトウェア
ストレージシステムで合成負荷を作成(合成テストを実行)するには、Flexible IO Tester(fio)ユーティリティバージョン2.1.4を使用します。 すべての模擬テストでは、fioセクション[グローバル]の次の構成パラメーターが使用されます。
-
thread=0
-
direct=1
-
group_reporting=1
-
norandommap=1
-
time_based=1
-
randrepeat=0
-
ramp_time=10
次のユーティリティは、合成負荷の下でパフォーマンスインジケータを取得するために使用されます。
-
iostat
、txk
キーを備えたsysstat
バージョン9.0.4パッケージの一部です。 -
vxstat
、svd
キーを使用したSymantec Storage Foundation 6.1の一部。 -
vxdmpadm
、-q iostat
スイッチを備えたSymantec Storage Foundation 6.1の一部。 -
fio
バージョン2.1.4。各負荷プロファイルの概要レポートを生成します。
パフォーマンスインジケータは、テスト中に5秒間隔で
iostat, vxstat, vxdmpstat
によって
iostat, vxstat, vxdmpstat
。
テストプログラム。
テストは、テスト対象システムから提示された8つのLUNからVeritas Volume Managerを使用して作成された
stripe, 8 column, stripe unit size=1MiB
ような論理ボリュームであるブロックデバイス上のfioプログラムで合成負荷を作成することによって実行されます。
テストは、3つのテストグループで構成されました。
詳細を尋ねる
テスト負荷を作成するとき、fioプログラムの以下のパラメーターが(以前に定義されたパラメーターに加えて)使用されます:
テストグループは、テスト対象のストレージシステムで提供されるLUNの合計量とI / Oブロックのサイズが異なる3つのテストで構成されます。
vxstatチームが出力したデータに基づいて、テスト結果に基づいて、テスト結果を組み合わせた次のグラフが生成されます。
得られた情報の分析が実行され、以下について結論が下されます。
テスト中に、次のタイプの負荷が調査されます。
テストグループは、一連のテストで構成されます。テストは、上記の種類の負荷のすべての可能な組み合わせです。 テスト間のテスト結果に対するストレージのサービスプロセス(ガベージコレクション)の影響を緩和するために、テスト中に記録された情報量をストレージのサービスプロセスのパフォーマンス(テストの最初のグループの結果によって決定)で割った値に等しいポーズが実現されます。
テスト結果に基づいて、各テストの終了時にfioソフトウェアによって出力されたデータに基づいて、次のグラフが、次の負荷タイプの組み合わせごとに生成されます:負荷プロファイル、I / O操作の処理方法、キューの深さ、I / Oブロックの異なる値を持つテストの組み合わせ:
結果の分析が実行され、遅延が1ミリ秒以下のディスクアレイの負荷特性、シングルスレッド負荷のアレイのパフォーマンスに関するアレイの最大パフォーマンスについて結論が出されました。 最大量のデータを送信しながら、最大数のI / O操作を実行できるブロックとして、配列を操作するための最適なブロックサイズも決定されます。
このグループのテストを実行するには、別のサーバーをスタンド構成に追加します。 ディスクアレイは同じサイズの16個のLUNに分割され、合計でストレージボリューム全体を占有します。 各サーバーには8つのLUNが提供されます。 テストはグループ2のテストと同様に実行されますが、例外は2つのサーバーによって同時に負荷が生成されることです。 各テスト中に両方のサーバーで得られた合計パフォーマンスが推定されます。 テストの最後に、負荷を生成するサーバーの数がストレージのパフォーマンスに影響すると結論付けられます。
グループ1:入出力ブロック(I / O)のサイズを変更して、ランダム書き込みタイプの長い負荷を実装するテスト。
テスト負荷を作成するとき、fioプログラムの以下のパラメーターが(以前に定義されたパラメーターに加えて)使用されます:
-
rw=randwrite
; -
blocksize=4K
; -
numjobs=64
; -
iodepth=64
。
テストグループは、テスト対象のストレージシステムで提供されるLUNの合計量とI / Oブロックのサイズが異なる3つのテストで構成されます。
- 完全にマークされたストレージシステムで実行された書き込みテスト-提示されたLUNの合計ボリュームは有効なストレージ容量に等しく、テスト期間は18時間です。
- ブロックサイズ(4,8,16,32,64,1024K)を変更して記録するテストは、完全にラベル付けされたストレージシステムで実行され、各テストの期間は1時間です。 テスト間の一時停止は2時間です。
- ブロックサイズ(4,8,16,32,64,1024K)を変更して記録するテストは、最大70%のストレージシステムで実行され、各テストの期間は1時間です。 テスト間の一時停止は2時間です。 このテストでは、テストされたストレージシステム上に8つのLUNが作成され、その合計容量は有効なストレージ容量の70%です。 作成されたLUNはテストサーバーに提示され、Symantec VxVMツールはテスト負荷がかかるボリュームを収集します。
vxstatチームが出力したデータに基づいて、テスト結果に基づいて、テスト結果を組み合わせた次のグラフが生成されます。
- 時間の関数としてのIOPS。
- 時間の関数としての帯域幅(BandWidth)。
- 時間の関数としてのレイテンシー。
得られた情報の分析が実行され、以下について結論が下されます。
- レコードへの長時間の負荷によるパフォーマンスの低下の存在。
- ストレージ(ガベージコレクション)のサービスプロセスのパフォーマンスにより、長時間のピーク負荷の下で記録するためのディスクアレイのパフォーマンスが制限される
- ストレージサービスプロセスのパフォーマンスに対するI / Oブロックのサイズの影響の程度。
- ストレージのサービスプロセスを平準化するためのストレージ用に予約されているスペースの量。
- サービスプロセスのパフォーマンスに対するストレージ容量の影響。
グループ2:ブロックデバイスレベルで実行される、単一サーバーによって生成されるさまざまな種類の負荷に対するディスクアレイパフォーマンステスト。
テスト中に、次のタイプの負荷が調査されます。
- プロファイルのロード(変更可能なソフトウェアパラメータfio:
randomrw, rwmixedread
):
- ランダム記録100%;
- ランダム書き込み30%;ランダム読み取り70%;
- ランダム読み取り100%。
- ブロックサイズ:1KB、8KB、16KB、32KB、64KB、1MB(変更可能なソフトウェアパラメーターfio:
blocksize
); - 入出力操作の処理方法:同期、非同期(変更可能なソフトウェアパラメーターfio:
ioengine
); - 負荷を生成するプロセスの数:
numjobs
(ソフトウェアfioの可変パラメーター:numjobs
); - キュー深度(非同期I / O操作の場合):32、64(変更可能なソフトウェアパラメーターfio:
iodepth
)。
テストグループは、一連のテストで構成されます。テストは、上記の種類の負荷のすべての可能な組み合わせです。 テスト間のテスト結果に対するストレージのサービスプロセス(ガベージコレクション)の影響を緩和するために、テスト中に記録された情報量をストレージのサービスプロセスのパフォーマンス(テストの最初のグループの結果によって決定)で割った値に等しいポーズが実現されます。
テスト結果に基づいて、各テストの終了時にfioソフトウェアによって出力されたデータに基づいて、次のグラフが、次の負荷タイプの組み合わせごとに生成されます:負荷プロファイル、I / O操作の処理方法、キューの深さ、I / Oブロックの異なる値を持つテストの組み合わせ:
- 負荷を生成するプロセスの数の関数としてのIOPS。
- 負荷を生成するプロセスの数の関数としての帯域幅。
- 負荷を生成するプロセスの数の関数としての緯度(clat)。
結果の分析が実行され、遅延が1ミリ秒以下のディスクアレイの負荷特性、シングルスレッド負荷のアレイのパフォーマンスに関するアレイの最大パフォーマンスについて結論が出されました。 最大量のデータを送信しながら、最大数のI / O操作を実行できるブロックとして、配列を操作するための最適なブロックサイズも決定されます。
グループ3:ブロックデバイスレベルで実行される、2台のサーバーによって生成されるさまざまな種類の負荷のディスクアレイパフォーマンステスト。
このグループのテストを実行するには、別のサーバーをスタンド構成に追加します。 ディスクアレイは同じサイズの16個のLUNに分割され、合計でストレージボリューム全体を占有します。 各サーバーには8つのLUNが提供されます。 テストはグループ2のテストと同様に実行されますが、例外は2つのサーバーによって同時に負荷が生成されることです。 各テスト中に両方のサーバーで得られた合計パフォーマンスが推定されます。 テストの最後に、負荷を生成するサーバーの数がストレージのパフォーマンスに影響すると結論付けられます。
試験結果
グループ1:入出力ブロック(I / O)のサイズを変更して、ランダム書き込みタイプの長い負荷を実装するテスト。
結論:
1.特定の時点で長時間の記録負荷が発生すると、ストレージシステムのパフォーマンスの著しい低下が記録されます(図3)。 パフォーマンスの低下が予想されますが、これはガベージコレクション(GC)プロセスの包含とこれらのプロセスの制限されたパフォーマンスに関連するSSD(クリフの書き込み)操作の機能です。 ディスクアレイのパフォーマンスは、書き込みクリフ効果の後(パフォーマンスの低下後)に修正され、ディスクアレイの最大平均パフォーマンスと見なすことができます。
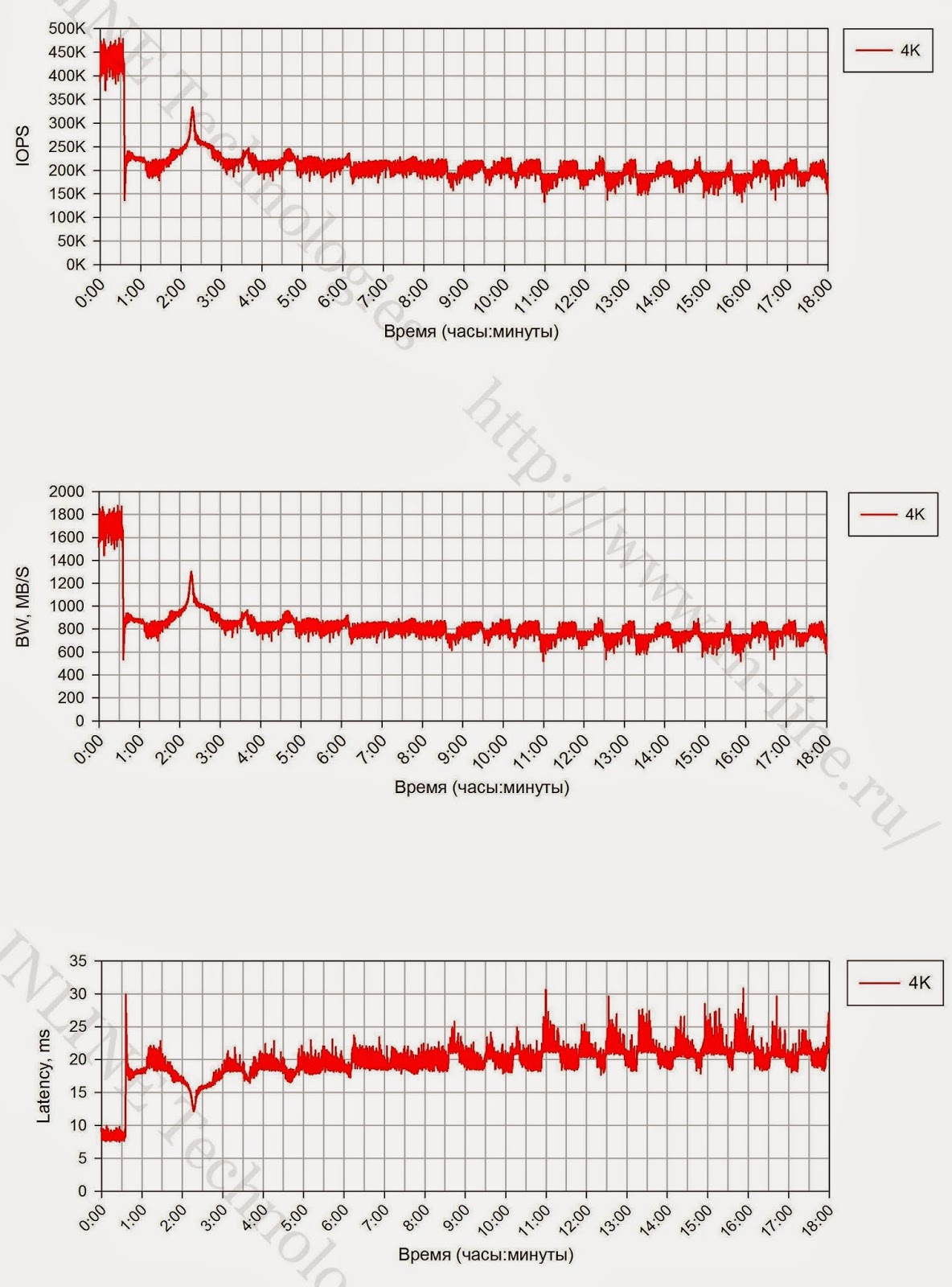 |
| 図3. 4Kユニットでの長期録画中のI / O操作(iops)、データ転送速度(帯域幅)、および待ち時間(待ち時間)の速度の変化。 |
2.連続記録ロード中のブロックのサイズは、GCプロセスのパフォーマンスに影響します。 そのため、小さなブロック(4K)の場合、GCの速度は640 MB / sであり、中規模および大規模のブロック(16K-1M)では、CGは約1200 MB / sの速度で動作します。
3.最初の長いテストとそれに続く4Kブロックでの同等のテストで記録されたピークパフォーマンスの最大ストレージ時間の値の違いは、テスト前にストレージが完全に満たされなかったためです。
4.ピークパフォーマンスでのストレージの最大動作時間は、4Kブロックと他のすべてのブロックで大幅に異なります。これは、GCプロセス用に予約されたストレージスペースが限られているためと考えられます。
5.ストレージシステムでサービスプロセスを実行するために、約2TBが予約されています。
6. 70%満たされたストレージシステムでテストすると、パフォーマンスの低下は少し遅れて発生します(約10%)。 GCプロセスの速度に変更はありません。
チャートと表。 (すべての写真はクリック可能です)
単一のサーバーによって生成されるさまざまな種類の負荷のデバイスパフォーマンスグラフをブロックします。
| データレート(帯域幅) | I / O速度(IOPS) | 待ち時間 | |
| 完全にマークされたストレージ(100%フォーマット済み) | 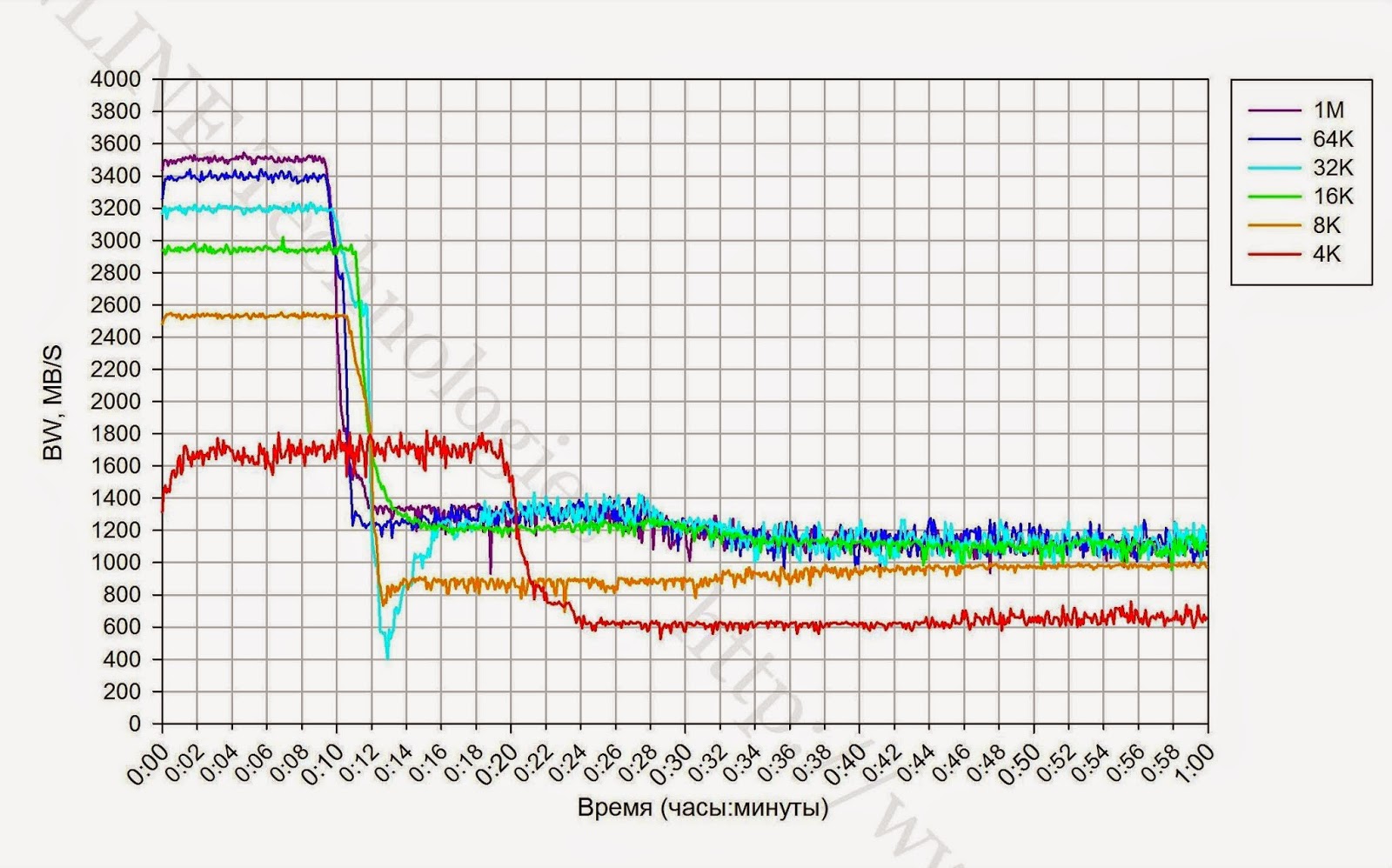 |  | 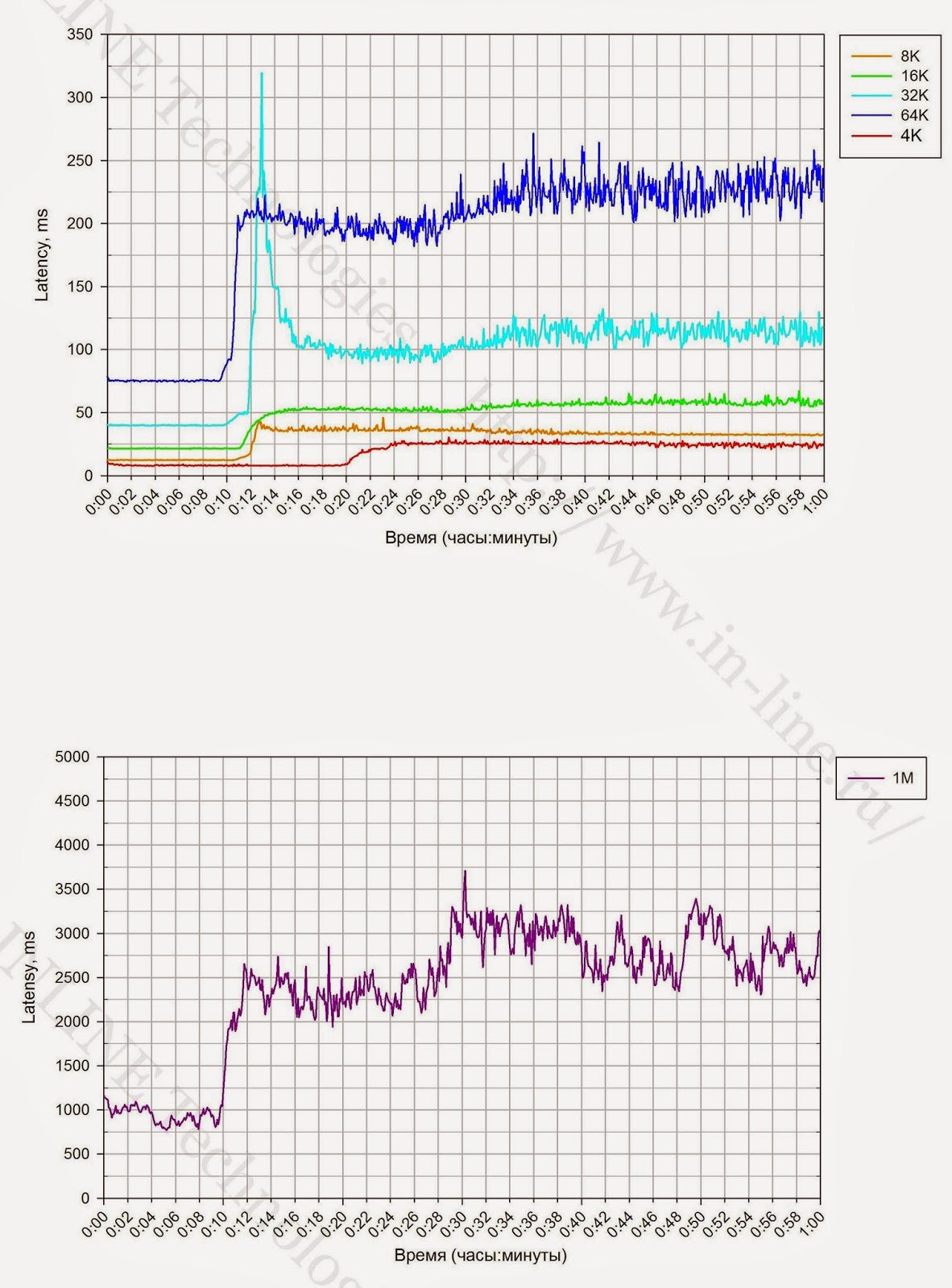 |
| ストレージが完全にラベル付けされていない(70%フォーマット済み) | 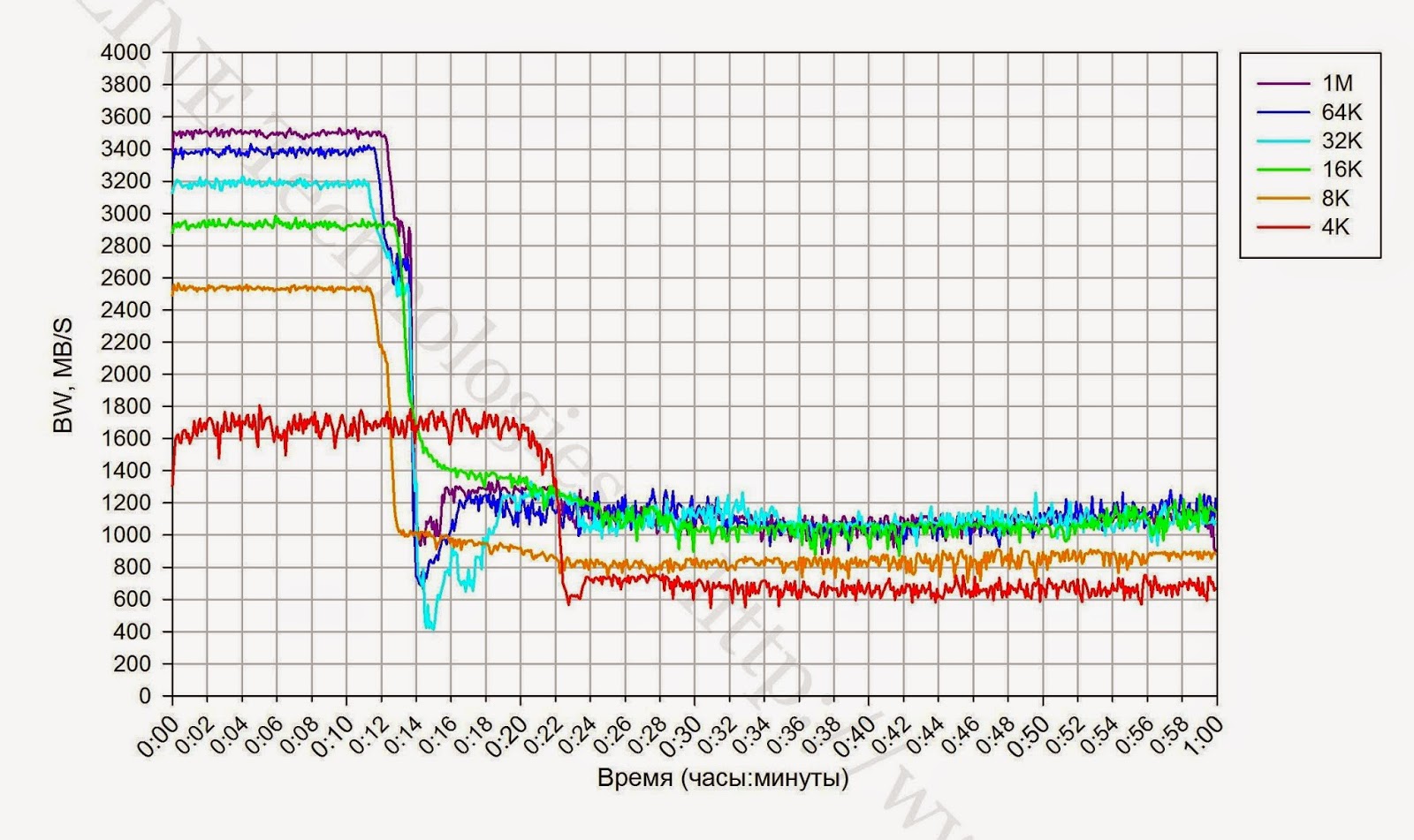 |  | 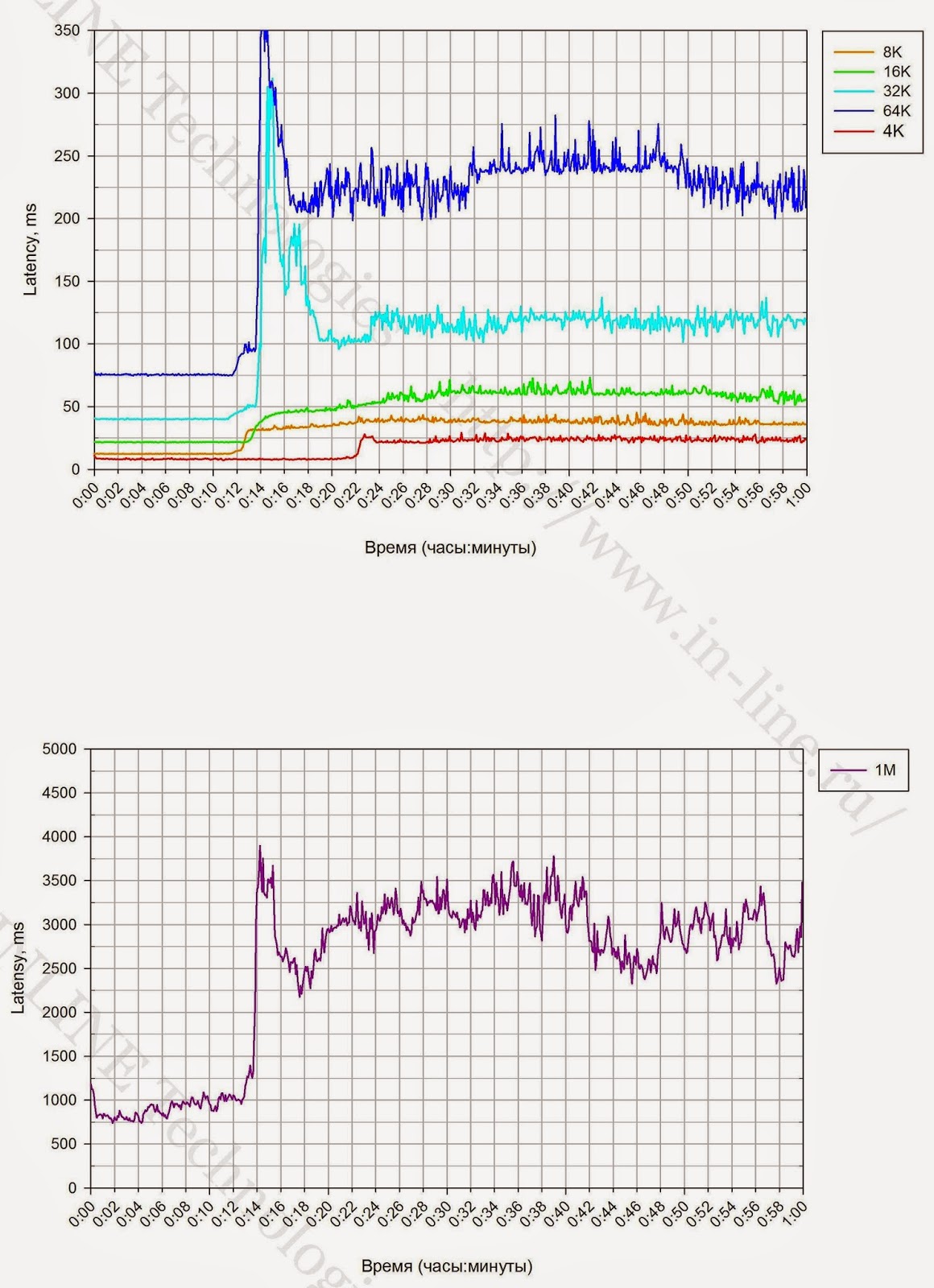 |
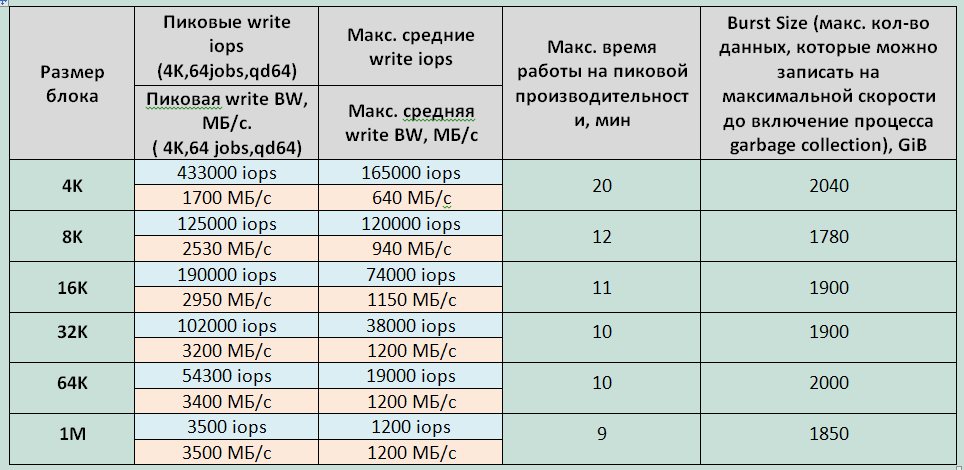 |
| 表1長い記録負荷でのブロックサイズに対するSHDインジケータの依存性。 |
グループ2:ブロックデバイスレベルで実行される、単一サーバーによって生成されるさまざまな種類の負荷に対するディスクアレイパフォーマンステスト。
グラフに表示される主なテスト結果は、表にまとめられています。
表とグラフ。 (すべての写真はクリック可能です)
2つのサーバーによって生成されるさまざまな種類の負荷のデバイスパフォーマンスグラフをブロックします。
(すべての写真はクリック可能です)
 |
| 表2単一の負荷生成プロセスのストレージパフォーマンス(ジョブ= 1) |
 |
| 表3 1ms未満の遅延に対する最大ストレージパフォーマンス |
 |
| 表4.最大3msの遅延に対する最大ストレージパフォーマンス |
 |
| 表5さまざまな負荷プロファイルの最大ストレージ容量。 |
2つのサーバーによって生成されるさまざまな種類の負荷のデバイスパフォーマンスグラフをブロックします。
(すべての写真はクリック可能です)
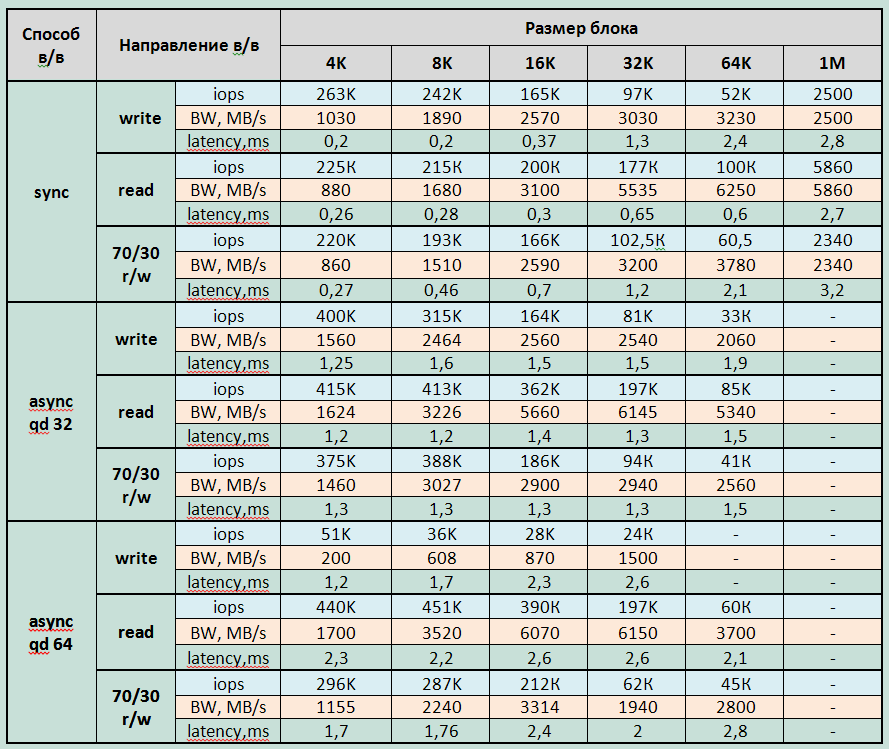
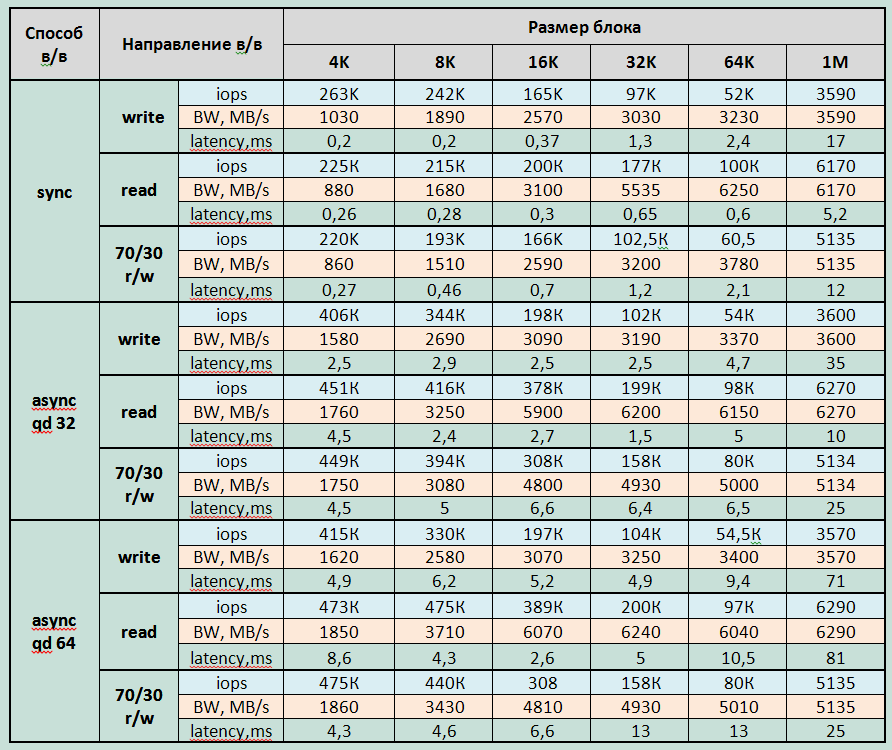
| 同期入出力 | キュー深度32の非同期I / O | キュー深度が64の非同期I / O | |
| ランダム読み取り | 
| 
| 
|
| ランダム録音の場合 | 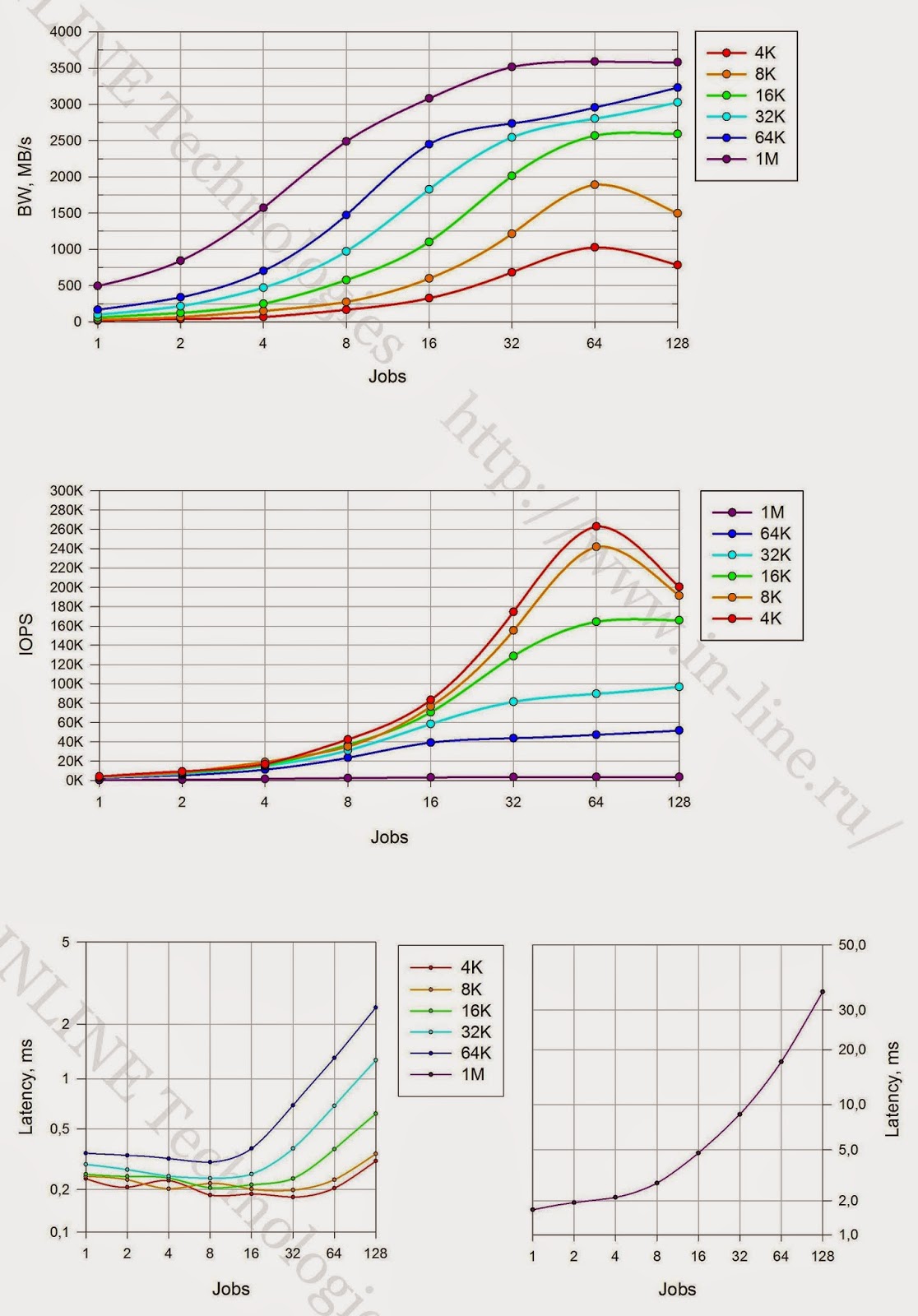
| 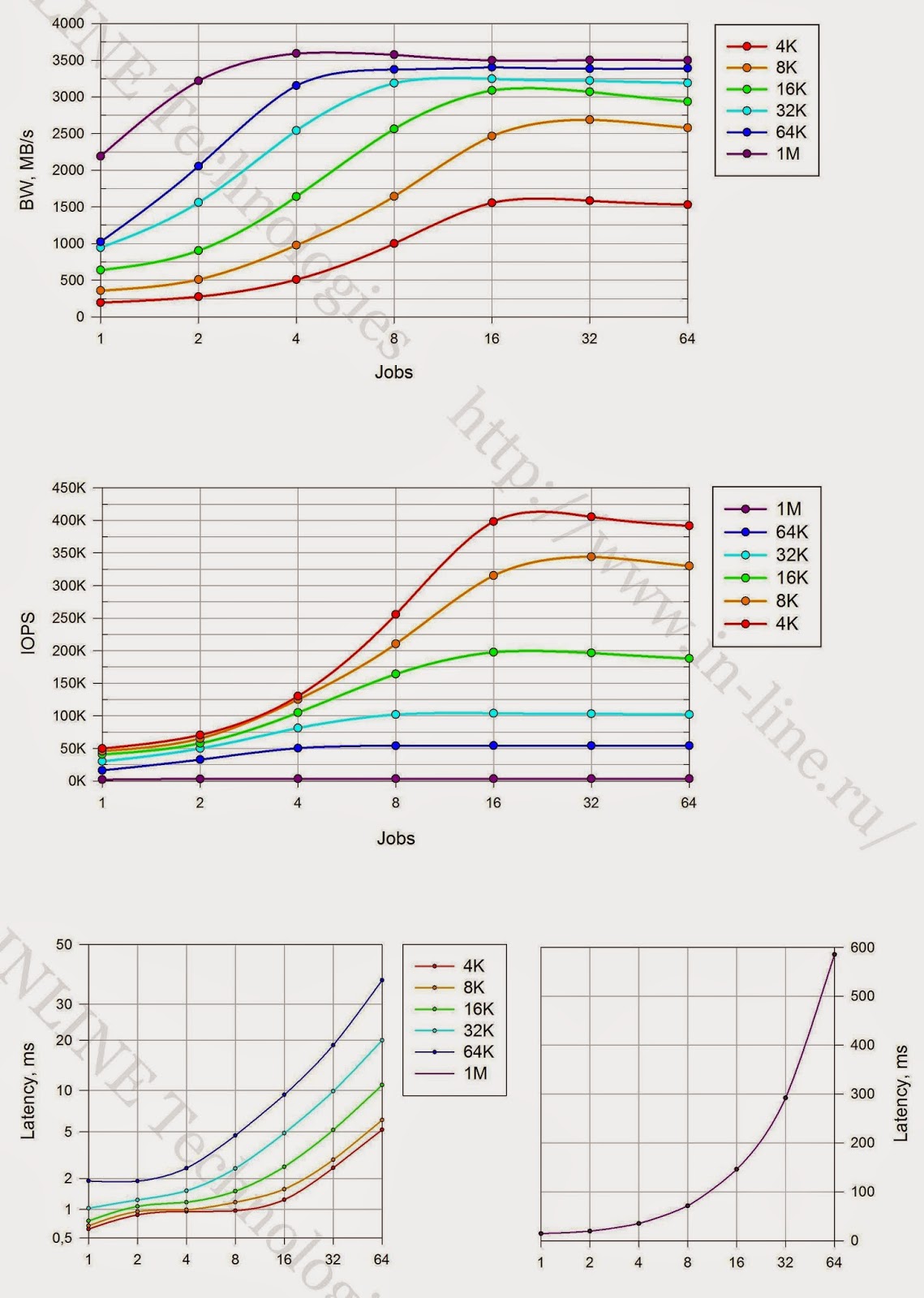
| 
|
| 混合負荷時(読み取り70%、書き込み30%) | 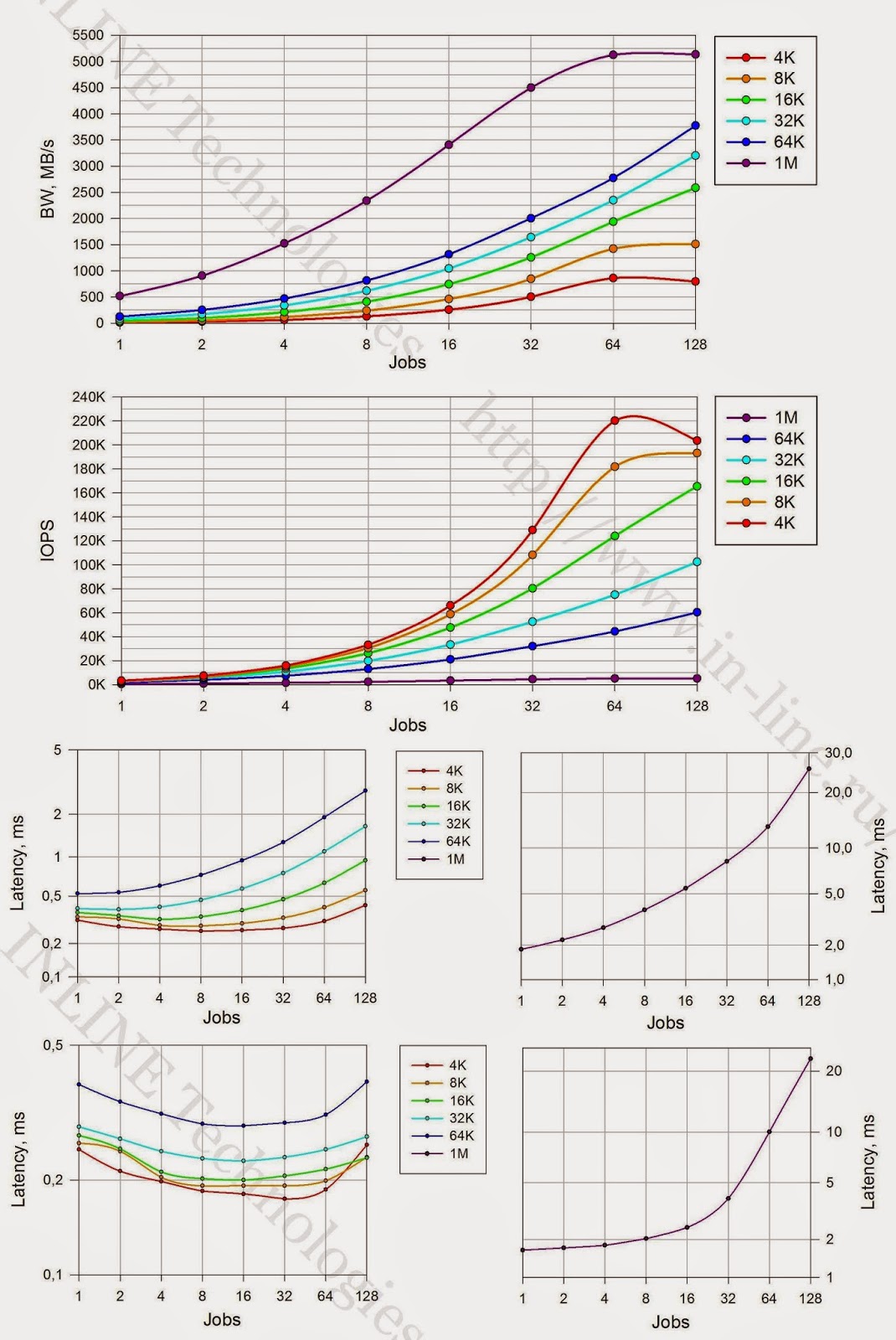
| 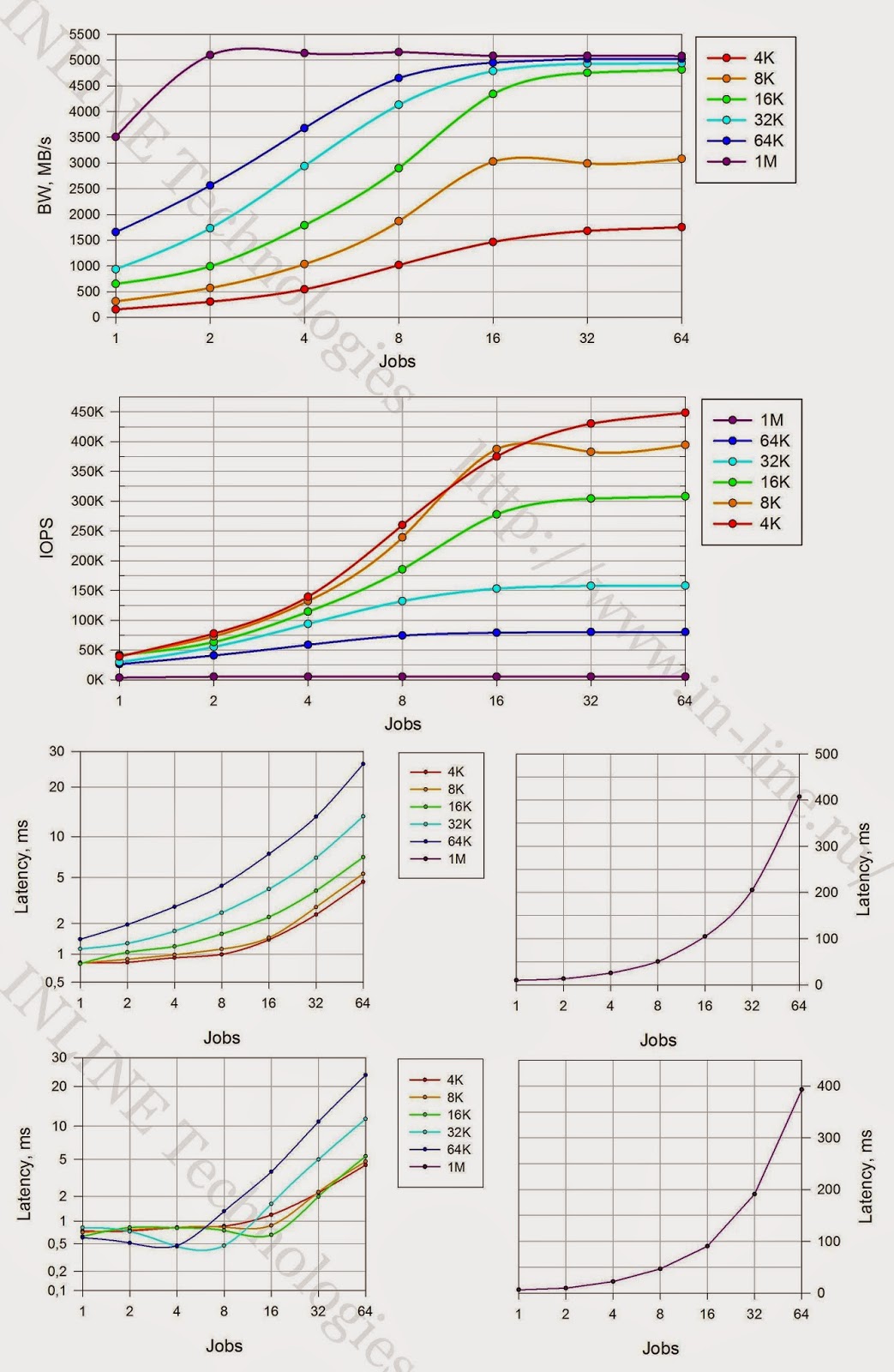
| 
|
結論:
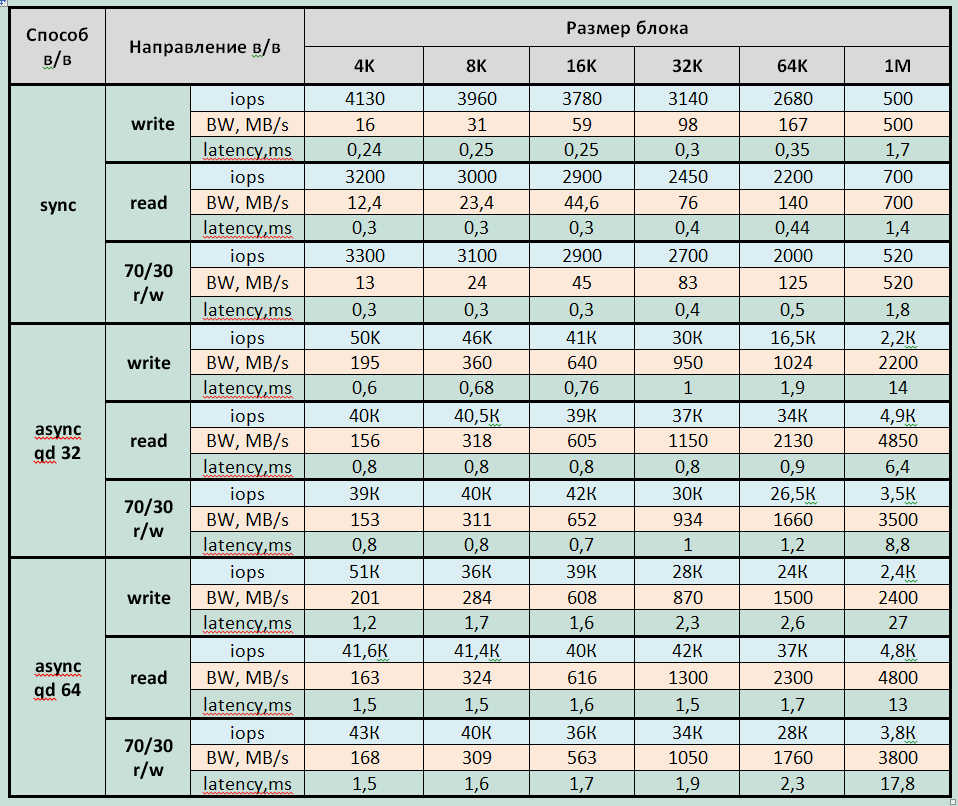
1.ストレージの最大記録パフォーマンスパラメーター(各テスト期間の平均から3分):
記録:
- 遅延4.9msで415000 IOPS(4KB非同期qd64ブロック)
- 同期I / Oで-遅延0.2ms(4Kブロック)で263000 IOPS
- 帯域幅:3600MB / s(大きなブロックの場合)
読書:
- レイテンシ4.3msで475000 IOPS、レイテンシ2.3で440000 IOPS(8KB非同期qd64ブロック);
- 同期I / Oで-レイテンシ0.26ms(4Kブロック)で225000 IOPS
- 帯域幅:6290MB / s(大きなブロックの場合)
混合負荷(70/30 rw)
- レイテンシ4.3msで475000 IOPS(4KB非同期qd64ブロック);
- 同期I / Oで-レイテンシ0.27ms(4Kブロック)で220,000 IOPS
- 大きなブロックの場合、帯域幅5135MB / s。
最小遅延:
- 記録時-4Kジョブのブロックで0.177ms = 32同期
- 読み取り時-4Kジョブのブロックで0.25ms = 32同期
2. SHDは飽和モードに入ります
- 大きいブロックで8個のジョブ(32K-1M)を使用し、中小のブロックで16個のジョブ(4-16K)を使用する非同期I / Oメソッド。
- 64個のジョブでの同期I / O。
3.大きなブロック(16K-1M)での読み取り操作では、6 GB / sを超えるスループットが得られました。これは、サーバーをストレージシステムに接続するときに使用されるインターフェイスの合計スループットにほぼ相当します。 したがって、ストレージコントローラーもフラッシュドライブもシステムのボトルネックではありません。
4.非同期I / O方式のアレイは、同期I / O方式の場合よりも小さなブロック(4〜8K)で1.5〜2倍のパフォーマンスを発揮します。 大規模および中規模ブロック(16K-1M)では、同期および非同期I / Oのパフォーマンスはほぼ同等です。
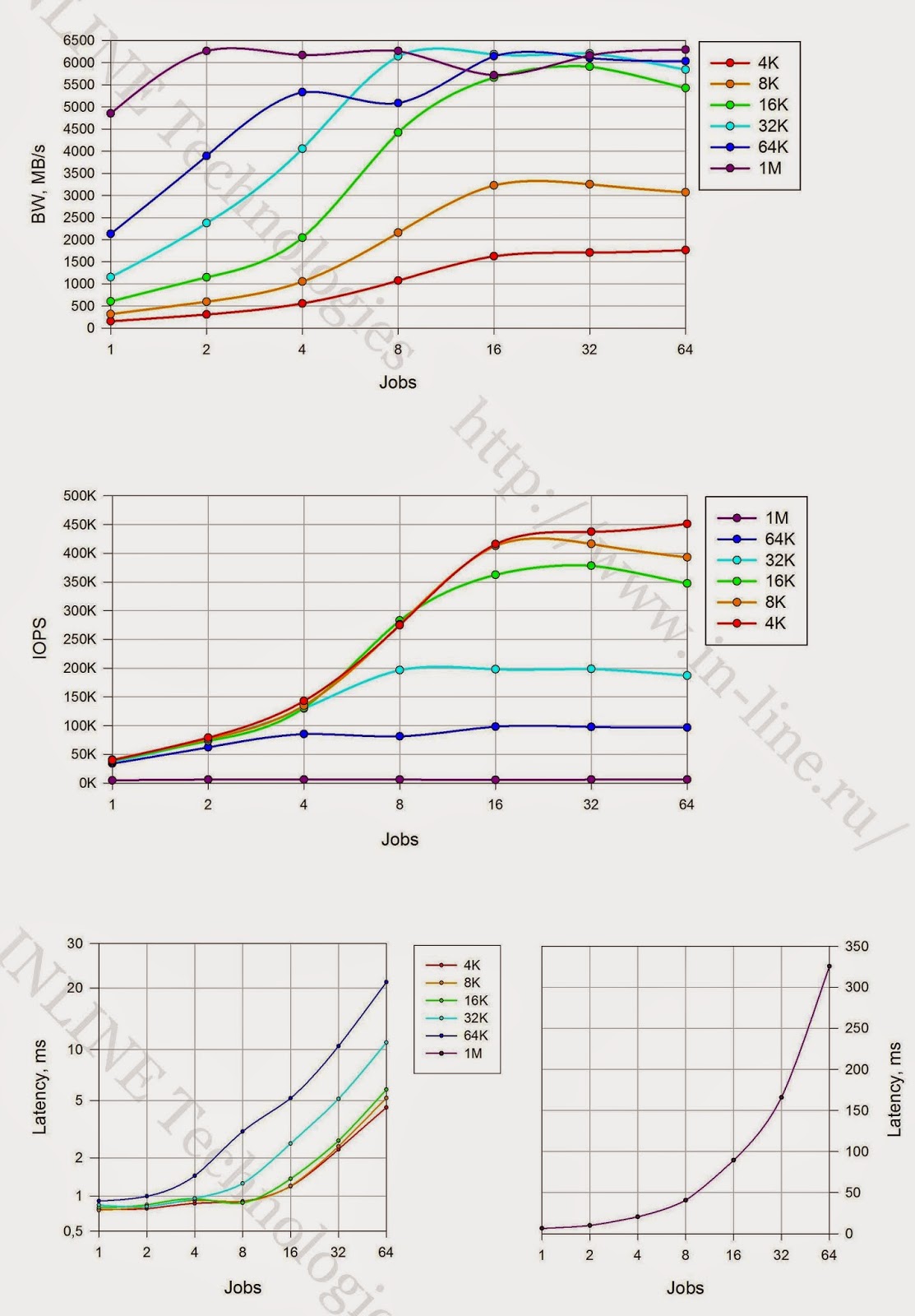
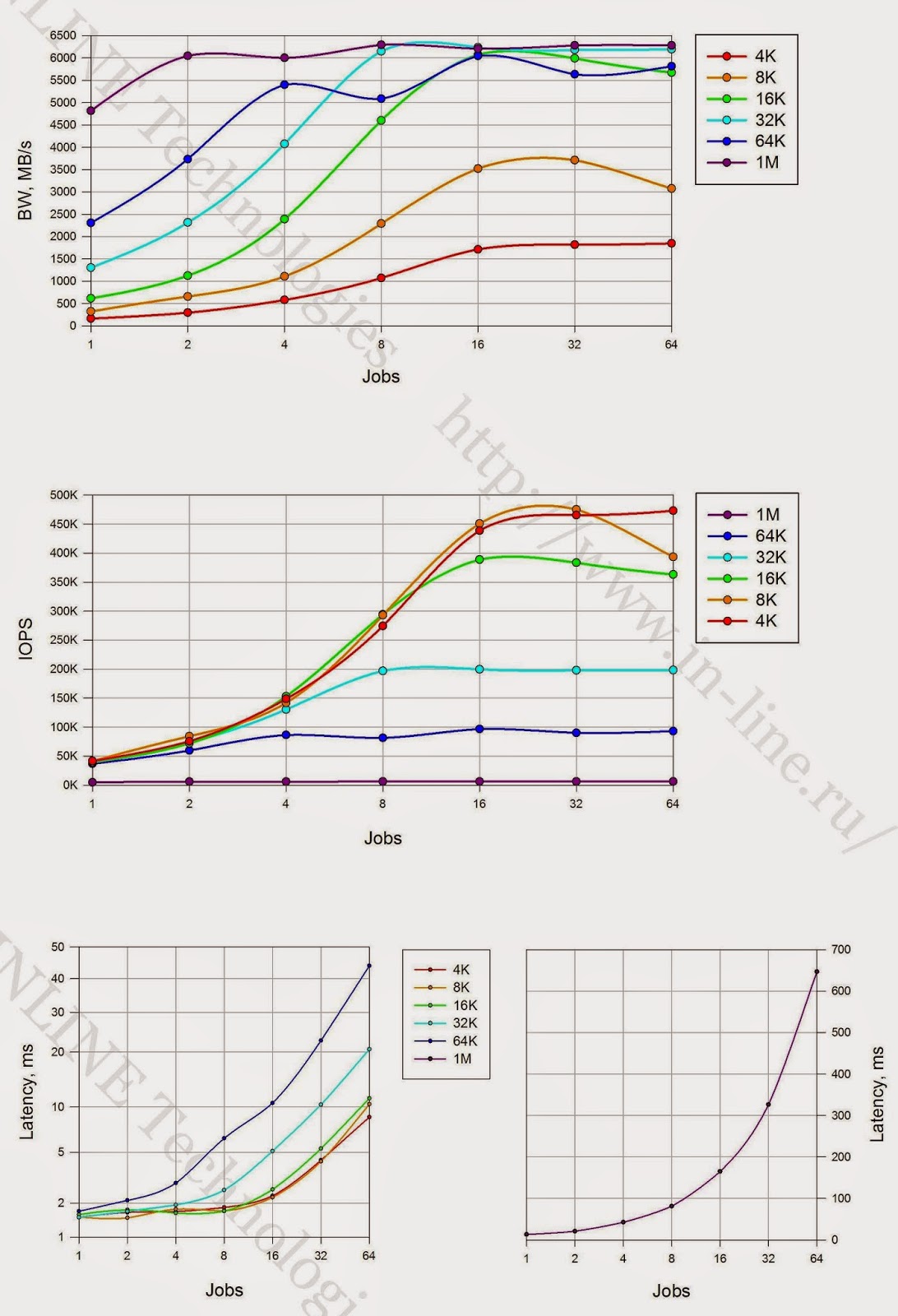
5.以下のグラフは、テストされたストレージシステムの最大取得パフォーマンスインジケータ(IOPSおよびデータ転送速度)のI / Oブロックのサイズへの依存性を示しています。 グラフの性質により、次の結論を導き出すことができます。
- 記録する場合、ストレージを操作するための最も効果的なユニットは8Kユニットです。
- 同期I / Oモードで読み取る場合、16Kおよび32Kブロックで作業する方がより有益です
- 非同期でI / Oを読み取る場合、最適なブロックは16Kです。
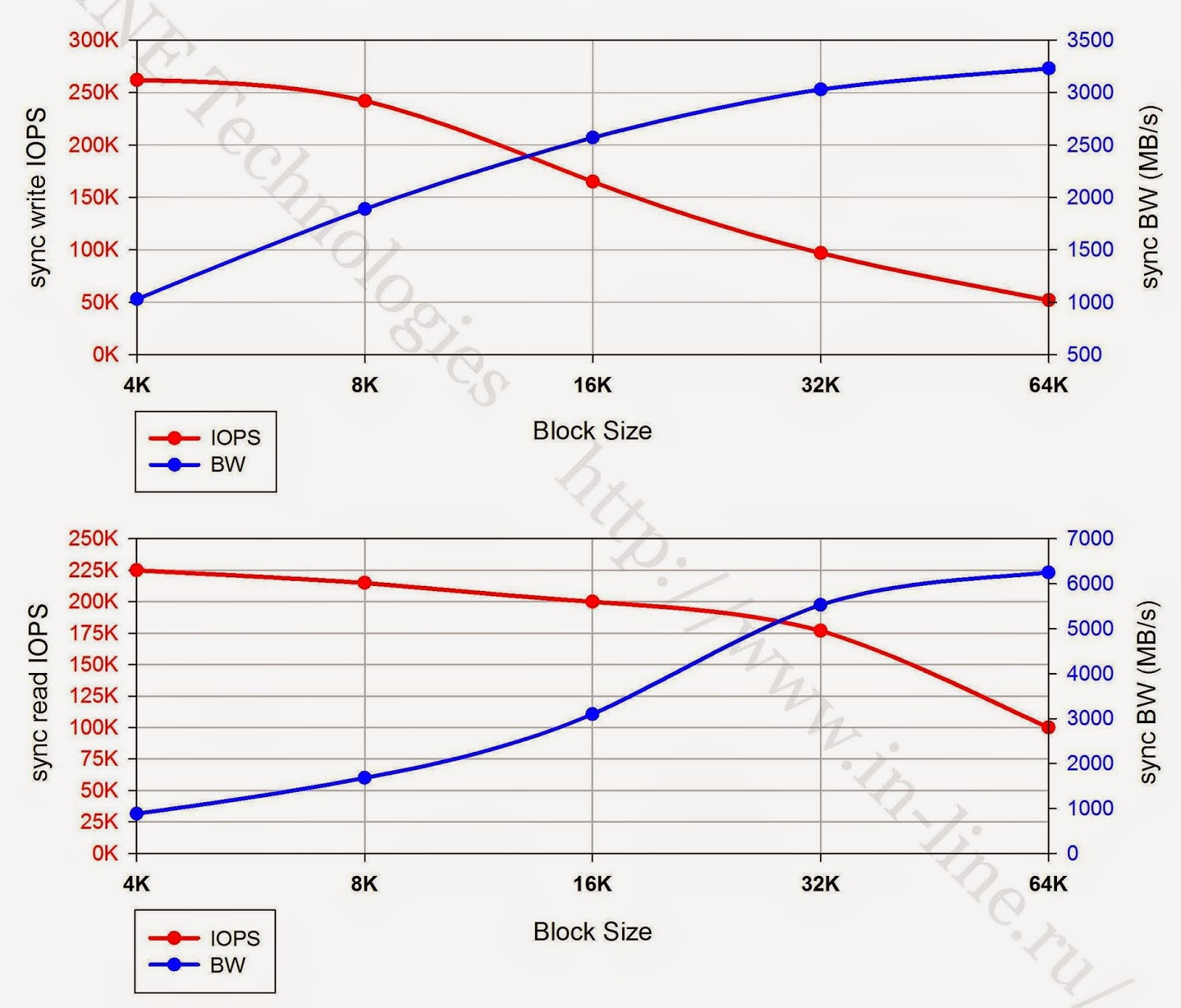 |
| さまざまなブロックサイズで/に同期して読み書きする場合の最大パフォーマンスインジケーター。 |
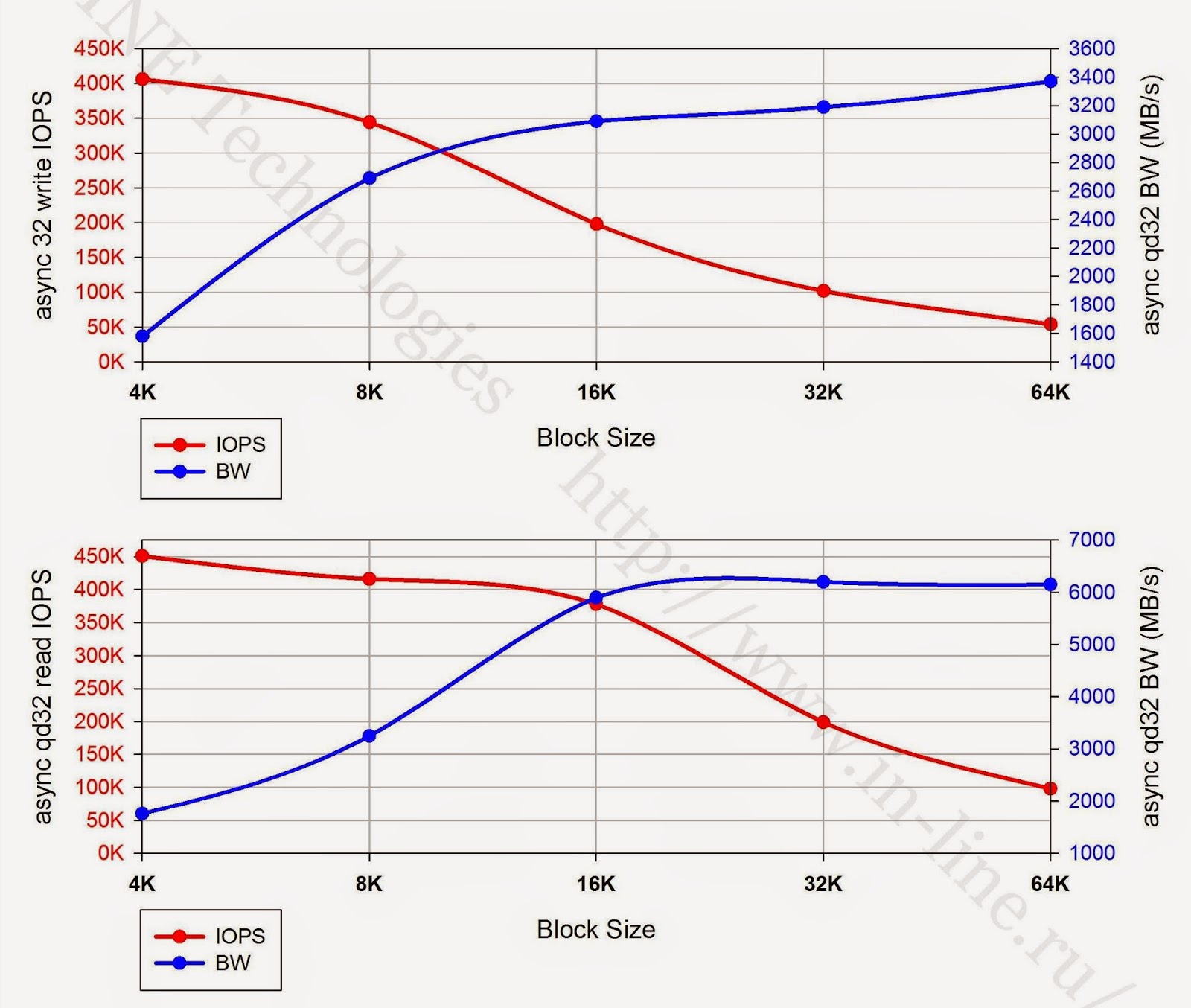 |
| I / O(qd32)の異なるブロックサイズを非同期で読み書きするときの最大パフォーマンスインジケーター。 |
グループ3:ブロックデバイスレベルで実行される、2つのサーバーによって生成されるさまざまな種類の負荷に対するディスクアレイパフォーマンステスト。
各テストで、1台のサーバーで負荷が生成されたときのグループ2のテストの結果と5%の誤差内で一致するパフォーマンスが得られました。 2番目のグループの結果と一致するため、グループ3のテストのグラフとパフォーマンスデータは提供しませんでした。
つまり、この調査では、サーバーがテストベンチのボトルネックではないことが示されました。
結論
一般に、システムは優れた結果を示しました。 明らかなボトルネックと明らかな問題を特定できませんでした。 すべての結果は安定しており、予測可能です。 以前のテストと比較して、IBM FlashSystem 820は管理インターフェースの違いに注目する価値があります。 820番目のモデルは、Texas Instruments RamSan 820から継承された、時々不便なjavaアプレットによって駆動されます。 当時、840thにはすでにIBM製品に馴染みのあるWebインターフェースがあり、XIV Storage SystemとStorwizeに似ています。 それらを使った作業は非常に優れており、最終的には高速です。
さらに、IBM FlashSystem 840は、エンタープライズクラスのデバイスがすべてのコンポーネントをホットスワップし、その場でファームウェアを更新するために必要な機能を獲得しました。 使用可能な接続インターフェイスとフラッシュモジュール構成の選択肢が大幅に拡大しました。
欠点は、おそらく、長時間の録音中にパフォーマンスが低下することです。 ただし、これは今日のフラッシュメモリテクノロジーの欠点であり、メーカーがシステムの速度を人為的に制限しなかったという事実の結果として現れています。 最大記録負荷が長く、パフォーマンスが低下した後でも、ストレージシステムは顕著な結果を示しました。
PS著者は、Pavel Katasonov、Yuri Rakitin、およびこの資料の準備に参加した会社の他のすべての従業員に感謝しています。