 コードを乱雑にしないために、この記事のタスクは非常に単純化されていることをすぐに予約したいと思います。 たとえば、実際のアプリケーションの1つでは、ドキュメントは例外を含む完全なスケジュールを保存し、それらに基づいて、スクリプトは必要な値を計算します。 しかし、プラグイン自体に焦点を当てたいので、例は非常に単純です。
コードを乱雑にしないために、この記事のタスクは非常に単純化されていることをすぐに予約したいと思います。 たとえば、実際のアプリケーションの1つでは、ドキュメントは例外を含む完全なスケジュールを保存し、それらに基づいて、スクリプトは必要な値を計算します。 しかし、プラグイン自体に焦点を当てたいので、例は非常に単純です。
私がElasticsearchコミッターではないことも言及する価値があります。提示される情報は主に試行錯誤によって得られたものであり、いくつかの点で間違っている可能性があります。
したがって、「HH:MM:SS」という形式の文字列として時間を保存する開始プロパティと停止プロパティを持つイベントドキュメントがあるとします。 タスクは、アクティブなイベント(開始<=時間<=停止)が出力の先頭になるように、所定の時間のイベントをソートすることです。 そのような文書の例:
{ "start": "09:00:00", "stop": "18:30:00" }
プラグイン
基礎として、 Elasticsearchの開発者の1人から例を取り上げました 。 プラグインは、登録する必要がある1つ以上のスクリプトで構成されます。
public class ExamplePlugin extends AbstractPlugin { public void onModule(ScriptModule module) { module.registerScript(EventInProgressScript.SCRIPT_NAME, EventInProgressScript.Factory.class); } }
完全なソースコード
スクリプトは、NativeScriptFactoryファクトリと、AbstractSearchScriptを継承するスクリプト自体の2つの部分で構成されています。 ファクトリーは、スクリプトの作成に取り組んでいます(同時にパラメーターの検証も行っています)。 スクリプトは(各シャードで)検索のために1回だけ作成されるため、この段階でパラメーターの初期化/処理を行う必要があることに注意してください。
クライアントアプリケーションは、パラメーターをスクリプトに渡す必要があります。
- time-「HH:MM:SS」という形式の文字列、興味のある時点
- use_doc-文書データへのアクセスに使用するメソッドを決定します(詳細は後ほど)
public static class Factory implements NativeScriptFactory { @Override public ExecutableScript newScript(@Nullable Map<String, Object> params) { LocalTime time = params.containsKey(PARAM_TIME) ? new LocalTime(params.get(PARAM_TIME)) : null; Boolean useDoc = params.containsKey(PARAM_USE_DOC) ? (Boolean) params.get(PARAM_USE_DOC) : null; if (time == null || useDoc == null) { throw new ScriptException("Parameters \"time\" and \"use_doc\" are required"); } return new EventInProgressScript(time, useDoc); } }
完全なソースコード
これで、スクリプトが作成され、準備が完了しました。 スクリプトで最も重要なことは、run()メソッドです。
@Override public Integer run() { Event event = useDoc ? parser.getEvent(doc()) : parser.getEvent(source()); return event.isInProgress(time) ? 1 : 0; }
完全なソースコード
このメソッドはドキュメントごとに呼び出されるため、ドキュメント内で何が発生し、どのくらいの速さであるかに特に注意する必要があります。 これは、プラグインのパフォーマンスに直接影響します。
一般に、ここでのアルゴリズムは次のとおりです。
- 必要なドキュメントデータを読む
- 結果を計算する
- Elasticsearchに返す
ドキュメントデータにアクセスするには、source()、fields()、doc()のいずれかの方法を使用する必要があります。 将来的には、doc()はsource()よりもはるかに高速であり、可能であれば使用する必要があります。
この例では、ドキュメントに基づいて、さらに作業するためのモデルを作成します。
public class Event { public static final String START = "start"; public static final String STOP = "stop"; private final LocalTime start; private final LocalTime stop; public Event(LocalTime start, LocalTime stop) { this.start = start; this.stop = stop; } public boolean isInProgress(LocalTime time) { return (time.isEqual(start) || time.isAfter(start)) && (time.isBefore(stop) || time.isEqual(stop)); } }
(もちろん、些細なケースでは、ドキュメントのデータを使用して、すぐに結果を返すことができます。それはより高速です)
この場合の結果は、現在行われているイベント(開始<=時間<=停止)の場合は「1」、それ以外の場合は「0」です。 結果の型は整数です、なぜなら ブール値による並べ替えElasticsearchでは、方法がわかりません。
各ドキュメントのスクリプトを処理した後、どのElasticsearchがそれらをソートするかによって値が決定されます。 タスクが完了しました!
統合テスト
テストはそれ自体が優れているだけでなく、デバッグの優れたエントリポイントでもあります。 ブレークポイントを設定して、目的のテストのデバッグを開始すると非常に便利です。 これがないと、プラグインのデバッグが非常に困難になります。
プラグイン統合テストのスキームは、およそ次のとおりです。
- テストクラスターを開始する
- インデックスとマッピングを作成する
- ドキュメントを追加
- サーバーに、指定されたパラメーターとドキュメントのスクリプト値を計算するように依頼します
- 値が正しいことを確認してください。
テストサーバーを起動するには、基本クラスElasticsearchIntegrationTestを使用します。 ノード、シャード、レプリカの数を構成できます。 GitHubで詳細をご覧ください。
テストドキュメントを作成するには、おそらく2つの方法があります。 1つ目は、テストでドキュメントを直接作成することです 。例を参照してください 。 このオプションは非常に優れており、最初はそれを使用しました。 ただし、ドキュメントのレイアウトが変更され、時間が経つにつれて、テストで構築された構造が現実と一致しなくなることが判明する場合があります。 したがって、2番目の方法は、 マッピングとデータを別々にリソースとして保存することです。 さらに、この方法により、ライブサーバーで予期しない結果が発生した場合に、問題のドキュメントをリソースとして単純にコピーし、テストがどのように落ちるかを確認できます。 一般的に、どの方法でも良いですが、選択はあなた次第です。
スクリプトの計算結果を要求するには、標準のJavaクライアントを使用します。
SearchResponse searchResponse = client() .prepareSearch(TEST_INDEX).setTypes(TEST_TYPE) .addScriptField(scriptName, "native", scriptName, scriptParams) .execute() .actionGet();
完全なソースコード
Travis-CIとの統合
プログラムのオプション部分は、 継続的統合Travisシステムとの統合です 。 .travisファイルを追加します。
language: java jdk: - openjdk7 - oraclejdk7 script: - mvn test
CIサーバーは各変更後にコードをテストします。 これは次のようになります 。 些細なことですが、素晴らしい。
申込み
これで、プラグインの準備とテストが完了しました。 それを試してみる時間です。
設置
プラグインのインストールについては、公式ドキュメントをご覧ください。 コンパイルされたプラグインは./targetにあります。 ローカルインストールを容易にするために、プラグインをコンパイルしてインストールする小さなスクリプトを作成しました。
mvn clean package if [ $? -eq 0 ]; then plugin -r plugin-example plugin --install plugin-example --url file://`pwd`/`ls target/*.jar | head -n 1` echo -e "\033[1;33mPlease restart Elasticsearch!\033[0m" fi
ソースコード
スクリプトはMac / brew向けに書かれています。 他のシステムでは、プラグインファイルへのパスを修正する必要があります。 Ubuntuでは、/ usr / share / elasticsearch / bin / pluginにあります。 プラグインをインストールした後、Elasticsearchを再起動することを忘れないでください。
試験データ
Rubyで書かれたシンプルなテストドキュメントジェネレーター 。
bundle install ./generate.rb
テスト依頼
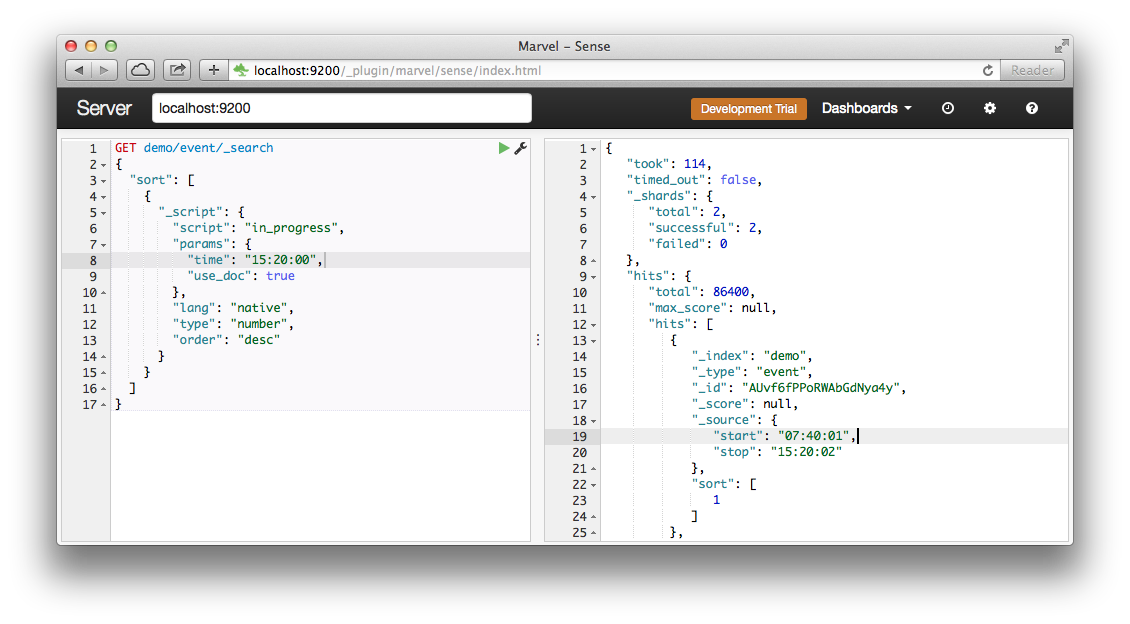
Elasticsearchに、すべてのイベントをin_progressスクリプトの結果でソートするように依頼します。
curl -XGET "http://localhost:9200/demo/event/_search?pretty" -d' { "sort": [ { "_script": { "script": "in_progress", "params": { "time": "15:20:00", "use_doc": true }, "lang": "native", "type": "number", "order": "desc" } } ], "size": 1 }'
結果:
{ "took" : 139, "timed_out" : false, "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "hits" : { "total" : 86400, "max_score" : null, "hits" : [ { "_index" : "demo", "_type" : "event", "_id" : "AUvf6fPPoRWAbGdNya4y", "_score" : null, "_source":{"start":"07:40:01","stop":"15:20:02"}, "sort" : [ 1.0 ] } ] } }
サーバーが139ミリ秒で86,400ドキュメントの値を計算したことがわかります。 もちろんです
速度は単純なソート(2ミリ秒)に匹敵しませんが、ラップトップにとってはそれほど悪くありません。 さらに、スクリプトは異なるシャードで並行して実行されるため、スケーリングされます。
Source()およびdoc()メソッド
最初に書いたように、スクリプトにはドキュメントのコンテンツにアクセスするためのいくつかのメソッドがあります。 これらは、ソース()、フィールド()、およびドキュメント()です。 Source()は便利で遅い方法です。 要求されると、ドキュメント全体がHashMapにロードされます。 しかし、絶対にすべてが利用可能です。 Doc()はインデックス付きデータへのアクセスであり、はるかに高速ですが、操作は少し複雑です。 まず、Nestedタイプはサポートされていません。これは、ドキュメントの構造に制限を課します。 第二に、索引付けされたデータは、文書自体の内容と異なる場合があります。まず、行に関係します。 タスクの実験として、mapping.jsonの「インデックス」:「not_analyzed」を削除して、すべてが壊れる様子を確認できます。 fields()メソッドに関しては、正直なところ、私はそれを試したことはありませんが、ドキュメントから判断すると、source()よりわずかに優れています。
use_docパラメーターをfalseに変更してsource()を使用してみてください。
リクエスト
そして今では587ミリ秒かかりました。 4倍遅くなります。 大きなドキュメントを含む実際のアプリケーションでは、数百倍の差が生じる可能性があります。
curl -XGET "http://localhost:9200/demo/event/_search?pretty" -d' { "sort": [ { "_script": { "script": "in_progress", "params": { "time": "15:20:00", "use_doc": false }, "lang": "native", "type": "number", "order": "desc" } } ], "size": 1 }'
他のスクリプトの使用
プラグインのスクリプトは、並べ替えだけでなく、一般的にスクリプトがサポートされているすべての場所で使用できます。 たとえば、見つかったドキュメントの値を計算できます。 ちなみに、この場合、フィルタリングされた限られたドキュメントのセットに対して計算が実行されるため、生産性はそれほど重要ではなくなりました。
curl -XGET "http://localhost:9200/demo/event/_search" -d' { "script_fields": { "in_progress": { "script": "in_progress", "params": { "time": "00:00:01", "use_doc": true }, "lang": "native" } }, "partial_fields": { "properties": { "include": ["*"] } }, "size": 1 }'
結果
{ "took": 2, "timed_out": false, "_shards": { "total": 2, "successful": 2, "failed": 0 }, "hits": { "total": 86400, "max_score": 1, "hits": [ { "_index": "demo", "_type": "event", "_id": "AUvf6fO9oRWAbGdNyUJi", "_score": 1, "fields": { "in_progress": [ 1 ], "properties": [ { "stop": "00:00:02", "start": "00:00:01" } ] } } ] } }
読んでくれてありがとう!
GitHubソースコード: github.com/s12v/elaticsearch-plugin-demo
PSところで、ベルリンのAWS / Elasticsearch / Symfony2に基づいた大規模なプロジェクトに取り組むには、経験豊富なプログラマーとシステム管理者が本当に必要です。 突然興味があるなら、書いてください!