
前回は、素晴らしいVowpal Wabbitツールについて説明しました。これは、RAMに適合しないサンプルから学習する必要がある場合に役立ちます。 このツールの機能は、主に線形モデルを構築できることです(ちなみに、これは優れた一般化機能を備えています)。また、機能の選択と生成、正則化、およびその他の追加手法によって高品質のアルゴリズムが実現されます。 今日は、より人気があり、大量のデータを処理するように設計されたツール、 Apache Sparkを見ていきます。
このツールの歴史や内部構造については詳しく説明しません。 実用的なことに焦点を当てます。 この記事では、Sparkで実行できる基本的な操作と基本的なことを検討し、次回は機械学習ライブラリMlLibとグラフ処理用のGraphXを詳しく調べます(この投稿の著者は主にこのツールを使用します-これこれは、グラフをクラスター上のRAMに保持する必要があることが多い場合に当てはまりますが、Vowpal Wabbitが機械学習には十分であることがよくあります)。 このマニュアルには多くのコードはありません。 Sparkの基本概念と哲学が考慮されます。 次の記事(MlLibとGraphXについて)では、いくつかのデータセットを取り上げ、実際のSparkを詳しく見ていきます。
Sparkはすぐに、 Scala 、 Python、およびJavaをネイティブでサポートします 。 Pythonの例を検討します。 IPython Notebookで直接作業して、クラスターからデータの小さな部分をアンロードして、たとえばPandasパッケージで処理するのは非常に便利です。
それでは、Sparkの主な概念がRDD(Resilient Distributed Dataset)であるという事実から始めましょう。これは、2種類の変換を行うことができるデータセットです(したがって、これらの構造のすべての作業は、これら2つのアクションのシーケンスで構成されます) 。
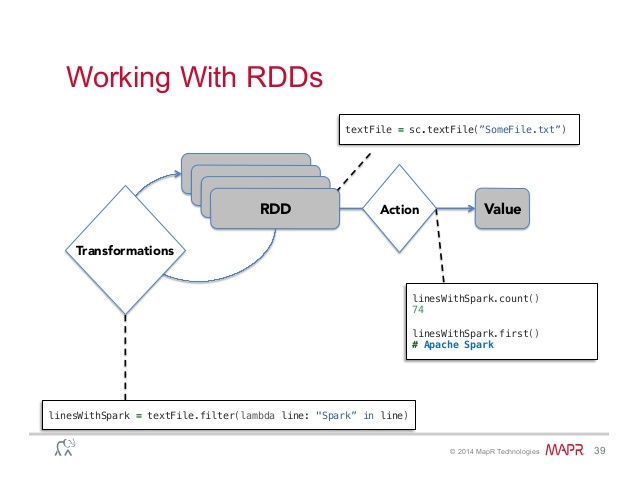
変換
この操作をRDDに適用した結果は、新しいRDDです。 原則として、これらは任意の方法で特定のデータセットの要素を変換する操作です。 最も一般的な変換の不完全なものを次に示します。それぞれが新しいデータセット(RDD)を返します。
.map(関数) -関数functionをデータセットの各要素に適用します
.filter(関数) -関数functionが真の値を返したデータセットのすべての要素を返します
.distinct([numTasks]) -元のデータセットの一意の要素を含むデータセットを返します
セットの操作についても注意する価値があります。その意味は名前から明らかです。
.union(otherDataset)
.intersection(otherDataset)
.cartesian(otherDataset) -新しいデータセットにはすべての種類のペア(A、B)が含まれます。最初の要素は元のデータセットに属し、2番目は引数データセットに属します
アクション
結果を具体化する必要があるときにアクションが適用されます-原則として、データをディスクに保存するか、コンソールにデータの一部を表示します。 RDDで実行できる最も一般的なアクションのリストを次に示します。
.saveAsTextFile(パス) -データをテキストファイルに保存します(hdfsで、ローカルマシンまたはその他のサポートされているファイルシステムに保存します-完全なリストはドキュメントにあります)
.collect() -データセットの要素を配列として返します。 原則として、これはデータセットにデータがほとんどない場合(さまざまなフィルターと変換が適用される場合)に適用されます。たとえば、Pandasパッケージを使用して、視覚化または追加のデータ分析が必要です。
.take(n) - データセットの最初のn要素を配列として返します
.count() -データセット内の要素の数を返します
.reduce(関数)は、 MapReduceに精通している人にとって馴染みのある操作です。 この操作のメカニズムから、関数function(入力として1つの値を返す2つの引数を取る)は可換および連想でなければならない
これらは、ツールを使用する際に知っておく必要がある基本です。 では、少し練習して、データをSparkにロードし、それらを使用して簡単な計算を行う方法を示しましょう。
Sparkを起動するときに最初に行うことは、 SparkContextを作成することです (簡単に言うと、これはクラスターで低レベルの操作を実装するオブジェクトです-詳細についてはドキュメントを参照してください) 。Spark-Shellの起動時に自動的に作成され、すぐに使用可能になります( scオブジェクト)
データの読み込み
Sparkにデータをアップロードするには2つの方法があります。
a)。 .parallelize(データ)関数を使用してローカルプログラムから直接
localData = [5,7,1,12,10,25] ourFirstRDD = sc.parallelize(localData)
b) .textFile(パス)関数を使用して、サポートされているリポジトリ(hdfsなど)から
ourSecondRDD = sc.textFile("path to some data on the cluster")
この時点で、Sparkのデータストレージの1つの機能と、最も便利な関数.cache() (一部はSparkが非常に一般的になったため)に注意することが重要です。これにより、RAMにデータをキャッシュできます(後者の可用性を考慮して)。 これにより、RAMで反復計算を実行し、IOオーバーヘッドを取り除くことができます。 これは、機械学習とグラフコンピューティングのコンテキストでは特に重要です。 ほとんどのアルゴリズムは反復的です-勾配法からPageRankのようなアルゴリズムまで
データを操作する
データをRDDに読み込んだ後、前述のさまざまな変換とアクションを実行できます。 例:
最初のいくつかの要素を見てみましょう:
for item in ourRDD.top(10): print item
または、これらの要素をすぐにPandasにロードして、DataFrameを操作します。
import pandas as pd pd.DataFrame(ourRDD.map(lambda x: x.split(";")[:]).top(10))
一般に、ご覧のとおり、Sparkは非常に便利であるため、さまざまな例を書くことはおそらく意味がありません。または、この演習を読者に任せることができます。
最後に、変換の例のみを示します。つまり、データセットの最大要素と最小要素を計算します。 簡単に推測できるように、これは、たとえば.reduce()関数を使用して実行できます。
localData = [5,7,1,12,10,25] ourRDD = sc.parallelize(localData) print ourRDD.reduce(max) print ourRDD.reduce(min)
そこで、このツールを使用するために必要な基本概念を検討しました。 SQLの操作、 <key、value>ペアの操作は考慮しませんでした(これは簡単です-たとえば、キーを選択するためにRDDにフィルターを適用するだけで、 sortByKey 、 countByKeyなどの組み込み関数を簡単に使用できます) 、 参加など)-読者はこれを独自に理解するように招待され、質問がある場合はコメントを書いてください。 既に述べたように、次回はMlLibライブラリーと個別にGraphXを詳細に調べます