公式の翻訳(少し磨き上げたもの)はこちらから入手できます。
数週間前にレビューのために提供したコンピューターグラフィックスの短期コースでは、ローカルの照明方法を使用しました。 これはどういう意味ですか? これは、各ポイントの照明の強度をその隣接ポイントとは無関係に選択したことを意味します。
Phongライティングモデルは、ローカル選択の典型的な例です。

最終的な強度は、環境照明、シーンのすべてのポイントの一定値の3つのコンポーネントで構成されます。 拡散照明とグレアは、与えられたポイントへの法線ベクトルと光の方向に依存しますが、シーンの残りのジオメトリには依存しません。 実際、周囲の照明がシーン全体で一定に選ばれた理由を考えてみましょう。
グローバルライティングへの2番目のアプローチ:アンビエントオクルージョン
まあ、実際、そのコースで地元の取材を受けたと言ったとき、私は少し間違っていました。 6番目の部分では、オブジェクトによって投影される影の構造を調べました。 そして、これはグローバルな報道の秘ofの一つです。 この記事では、周囲光を計算するためのいくつかの簡単なアプローチを検討することを提案します。 これは、Phongモデルの照明のアンビエントコンポーネントのみを使用し、拡散光もグレアも使用しないモデルの例です。

したがって、タスクは次のとおりです。シーンの可視部分の各ポイントのアンビエント照明(アンビエント照明)の値を計算します。
Fongが、周囲の環境は非常にビロードでふわふわしているため、すべての方向に同じ光を反射すると言ったとき、それはやや強力な単純化でした。 もちろん、これはローカルの照明方法を満足させるために行われました。これはグローバルな方法よりもはるかに高速です。 シャドウを作成するには、2つのパスでレンダリングする必要がありました。 しかし、現代の鉄では、より信性のある写真を得るために軽くシバリバストする余裕があります。 実際の生活では、トンネルの入り口を見ると、周囲の山よりも日光に照らされている部分がはっきりと見えます。
オブジェクトが均一に明るい半球(たとえば、曇り空)に囲まれていると仮定すると、十分に妥当な画像が得られます。 しかし、これはトンネルも内部で光るという意味ではありません。つまり、オブジェクトの各ポイントが光る半球からどれだけ見えるかを計算して、追加の作業を行う必要があります。
額に行こう
ここで取り上げる関連資料。
最も簡単な方法は、たとえば、オブジェクトの周囲の半球の千の異なる点をランダムに選択し、これらの点でカメラを使用してシーンを千回レンダリングし、見たモデルのどの部分を計算するかです。 ここで、いくつかの質問をするのが適切です。
質問1:極の周りに蓄積することなく、球上の千点の均一な分布をすぐに選択する方法を知っていますか?
このようなもの:
非表示のテキスト 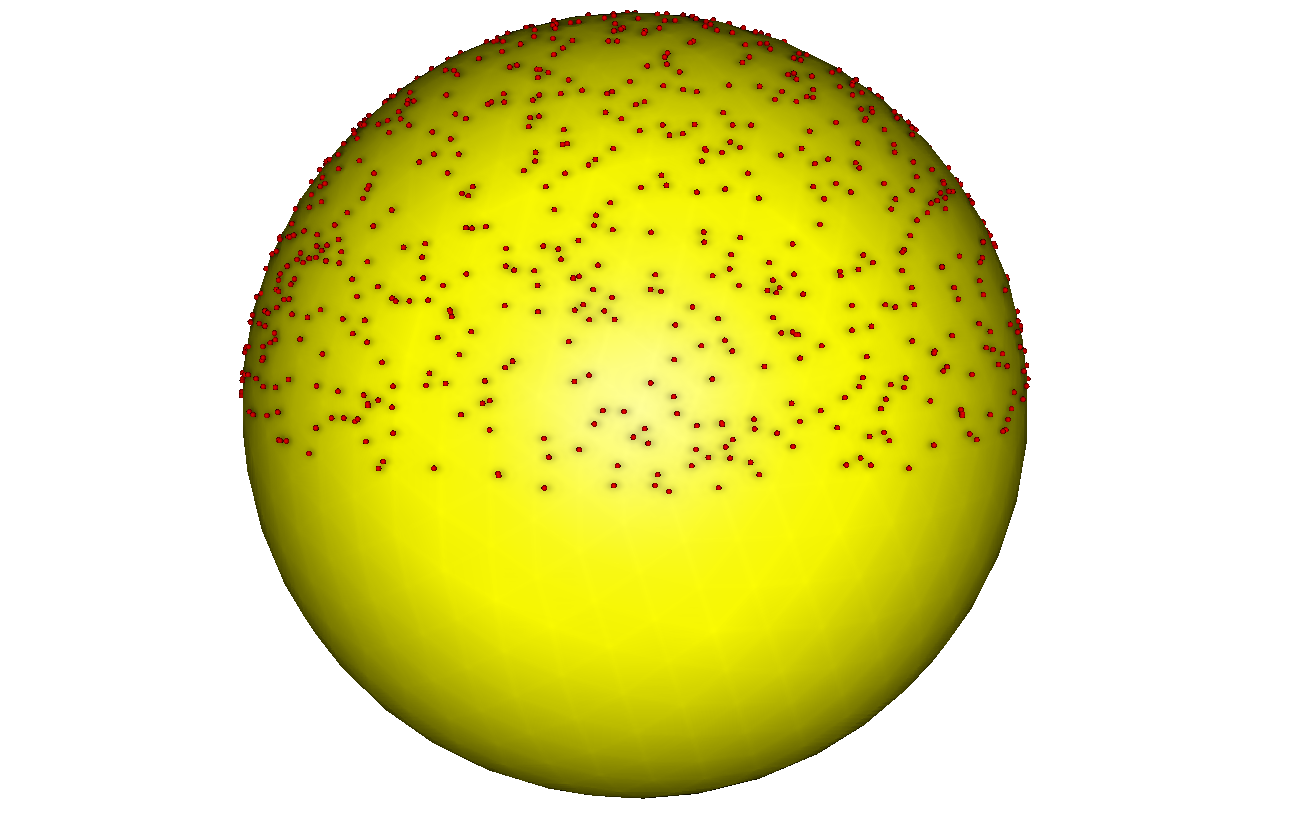
結局、緯度と経度をランダムに(均等に)選択した場合、極では素晴らしい凝塊が得られます。これは、世界で反射される光の均一性に関する仮定が正しくないことを意味します。 既製の計算の例は、 ここで取得できます 。
質問2:発光半球のどの部分がオブジェクトの特定のポイントから見えるかについての情報をどこに保存しますか? 真っ先に進むと、答えはほとんど明白です。オブジェクトのテクスチャーです!
そのため、2つのシェーダーを記述し、各ポイントに対して2回レンダリングします。 これが最初の(断片化された)シェーダーとその作業の結果です。
virtual bool fragment(Vec3f gl_FragCoord, Vec3f bar, TGAColor &color) { color = TGAColor(255, 255, 255)*((gl_FragCoord.z+1.f)/2.f); return false; }
非表示のテキスト 
ピクチャ自体は特に重要ではありませんが、このシェーダーの結果としてzバッファーに関心があります。
次に、このようなフラグメントシェーダーを使用して2番目のパスを作成します。
virtual bool fragment(Vec3f gl_FragCoord, Vec3f bar, TGAColor &color) { Vec2f uv = varying_uv*bar; if (std::abs(shadowbuffer[int(gl_FragCoord.x+gl_FragCoord.y*width)]-gl_FragCoord.z)<1e-2) { occl.set(uv.x*1024, uv.y*1024, TGAColor(255)); } color = TGAColor(255, 0, 0); return false; }
彼が赤い絵を出すことは私たちにとって絶対に重要ではありません。 この行はここで興味深いものです:
occl.set(uv.x*1024, uv.y*1024, TGAColor(255));
occlは、元々黒で塗りつぶされた1024x1024の画像です。 そして、この行は、このフラグメントを見ると、occlテクスチャマップでマークすることを示しています。 これは、レンダリングが終了した後のoccl画像の外観です。
非表示のテキスト 
何が起こっているのかを理解するための練習:穴のあるはっきりと見える三角形があるのはなぜですか? より正確には、なぜ変装されていない三角形の選択されたポイントのみがマークされるのですか?
演習2:なぜいくつかの三角形は他の三角形よりもドットで覆われた密度が高いのですか?
一般に、この手順を1000回繰り返し、結果として得られる1000個のocclイメージの平均を考慮して、このテクスチャを取得します。
非表示のテキスト 
ああ! すでに価値のあるもののように見えますが、このテクスチャの色のみを使用して、照明の追加の誤計算なしにモデルをレンダリングしてみましょう。
virtual bool fragment(Vec3f gl_FragCoord, Vec3f bar, TGAColor &color) { Vec2f uv = varying_uv*bar; int t = aoimage.get(uv.x*1024, uv.y*1024)[0]; color = TGAColor(t, t, t); return false; }
ここのaoimageは、計算されたばかりのテクスチャです。 このシェーダーの結果は次のとおりです。
非表示のテキスト 
演習3:ああ、なぜ雲よりも暗いのですか?
答え
これは、演習2の半分の答えです。糖尿病のテクスチャには片方の腕しかないことに気づきましたか? アーティストは経済的で、両手は同じで、2つの手のテクスチャ座標のグリッドをテクスチャ内の同じ場所に配置すると言いました。 そしてこれは、(大体)手が描かれている領域が、顔が描かれている領域の2倍強調表示されることを意味します。 それは1つだけです。
まとめると
このメソッドを使用すると、ジオメトリが静的なシーンのアンビエントオクルージョンテクスチャを(事前に)計算できます。 計算ミスの時間は、選択したポイントの数によって異なりますが、通常、時間はあまり重要ではありません。 これは実際にはシーンの作成であり、ゲームプロセスではありません。このようなテクスチャは一度考慮され、その後単に使用されます。 利点は、そのようなテクスチャを使用すると安価であり、均一に発光する半球よりも複雑な照明条件でカウントできることです。 欠点は、テクスチャ空間にオーバーレイがある場合、穏やかな不快感が発生することです。
それを機能させるためにテープを貼る場所は?
テクスチャ空間は糖尿病には適さないため、通常のフレームバッファを使用できます。 レンダリングはいくつかのパスで行われます:カメラの通常の位置からzバッファーをレンダリングし、次に何千もの異なる光源からモデルを照らし、シャドウマッピングを1000回カウントし、各ピクセルの平均を計算します。 すべてがうまくいくだろう、私たちは自分自身の上に情報を重ねる問題を取り除いたが、一方で、私たちは膨大な量のレンダリング時間を得た。 前のアプローチでモデルの寿命全体にわたってテクスチャを一度計算した場合、空間内のカメラの位置に依存します...
スクリーン空間アンビエントオクルージョン
そのため、グローバルライティングは高価なものであるという結論に達しました。さまざまな場所からの表面の可視性に関する多くの高価な計算が必要です。 結果の速度と品質の妥協点を見つけてみましょう。 すぐにカウントする写真を次に示します。

1つのパスで画像を描画します。使用するシェーダーは次のとおりです。
struct ZShader : public IShader { mat<4,3,float> varying_tri; virtual Vec4f vertex(int iface, int nthvert) { Vec4f gl_Vertex = Projection*ModelView*embed<4>(model->vert(iface, nthvert)); varying_tri.set_col(nthvert, gl_Vertex); return gl_Vertex; } virtual bool fragment(Vec3f gl_FragCoord, Vec3f bar, TGAColor &color) { color = TGAColor(0, 0, 0); return false; } };
Eeee ... color = TGAColor(0、0、0); ?! そうです、今ではアンビエントライティングのみを考慮しており、実際には、このシェーダーからの深度バッファーのみに関心があります。シェーダーが終了した後、フレームバッファーが完全に黒のままになることはなく、シーンの後処理の結果としてモデルが表示されます。
空のシェーダーと画像の後処理で使用されるレンダリングコードを次に示します。
ZShader zshader; for (int i=0; i<model->nfaces(); i++) { for (int j=0; j<3; j++) { zshader.vertex(i, j); } triangle(zshader.varying_tri, zshader, frame, zbuffer); } for (int x=0; x<width; x++) { for (int y=0; y<height; y++) { if (zbuffer[x+y*width] < -1e5) continue; float total = 0; for (float a=0; a<M_PI*2-1e-4; a += M_PI/4) { total += M_PI/2 - max_elevation_angle(zbuffer, Vec2f(x, y), Vec2f(cos(a), sin(a))); } total /= (M_PI/2)*8; total = pow(total, 100.f); frame.set(x, y, TGAColor(total*255, total*255, total*255)); } }
空のシェーダーでレンダリングすると、デプスバッファーがいっぱいになります。 後処理は次のとおりです。画面上の各ピクセルに対して、一定量(ここでは8)の光線を異なる方向に放射します。 私たちにとっての深度バッファは、起伏のある地形と考えることができます。 私たちが興味を持っているのは、各光線の方向に進むとどれだけ上昇するかです。 この関数はmax_elevation_angleであり、現在の光線のパスで出会う最大の上昇を与えます。
8つの光線すべての仰角がゼロの場合、このポイント(x、y)はどこからでもはっきりと見えます。 角度が約90°の場合、その点は周囲の天球からは非常に見えにくく、その結果、明るく照らされないはずです。
良い方法では、結果の図の立体角を計算する必要がありますが、この目的のために(90°の仰角)を取得し、8で割って立体角の近似値を取得するのに十分です。 結果として生じる立体角を100の累乗に上げると、単純に画像のコントラストが上がります。
古い黒人男性の頭で何が起こるかは次のとおりです。

いつものように、コードはこちらから入手できます 。
非表示のテキスト 
Habra外でのコミュニケーション
質問があり、コメントで質問したくない場合、または単にコメントを書く機会がない場合は、xmpp jabber-conference:3d@conference.sudouser.ruに参加してください。