
おそらく既にご存知のように、Kaggleはさまざまなレベルの研究者向けのプラットフォームであり、重要な関連タスクでデータ分析モデルをテストできます。 このようなリソースの本質は、モデルが最高の場合に優れた賞金を獲得する能力だけでなく、経験を獲得し、データ分析と機械学習の分野の専門家になるための(そしてこれはおそらくはるかに重要です) 。 実際、そのような専門家がしばしば直面する最も重要な問題は、実際のタスクを見つける場所です。 それらは十分にあります。
経験以外のインセンティブを提供しないトレーニングコンテストへの参加を試みます。
このために、 MNISTサンプルから手書き数字を認識するタスクを選択しました。 wikiからの情報。 MNIST(米国国立標準技術研究所データベース)は、パターン認識システムをテストするための主要な基盤であり、機械学習アルゴリズムのトレーニングとテストに広く使用されています。 これは、元のNISTデータベースの画像を並べ替えて作成されたもので、認識が困難でした。 さらに、特定の変換が実行されました(画像はグレーグラデーションを得るために正規化および平滑化されました)。
MNISTデータベースは、トレーニング用の60,000個の画像とテスト用の10,000個の画像で構成されています。 たとえば 、MNISTの認識問題について多数の記事が執筆されています (この場合、著者は畳み込みニューラルネットワークの階層システムを使用しました)。
元のサンプルはサイトに掲載されています 。
Kaggleは、MNISTの完全なサンプルを提示しますが、編成は少し異なります。 ここでは、トレーニングサンプルには42000個の画像が含まれ、テストサンプルには28000個の画像が含まれています。それでも、内容は同等です。 各MNIST画像は、256階調のグレーの28X28ピクセルの画像で表されます。 識別に含まれるいくつかのあいまいな数字の例を下の図に示します。

数値を認識するためのニューラルネットワークのモデルを作成するには、インストールされたnolearn 0.4パッケージとともにnumpyとscipy(すべての依存関係を満たす)と共にPythonインタープリターを使用します。
Adrian Rosebrockが私のブログに書いた紹介記事は、ここで私を大いに助けてくれました。 作成者自身が事前トレーニングなしでテストするために784-300-10アーキテクチャの通常の多層パーセプトロンを使用しているにもかかわらず、深い信頼のニューラルネットワークとそのトレーニングに関する入門情報を提供します。 私たちもそうします。 ところで、 nolearnページでパッケージを使用するプロセスは、さまざまな古典的なサンプルの例で非常に詳細に検討されています。
したがって、上記の記事に記載されている指示に従って、独自の多層パーセプトロンを作成し、ダウンロードおよび処理されたデータでトレーニングしてから、テストを実施します。
まず、アーキテクチャー784-300-10の独自の2層パーセプトロンを作成します。
from nolearn.dbn import DBN net = DBN( [784, 300, 10], learn_rates=0.3, learn_rate_decays=0.9, epochs=10, verbose=1, )
ここでいくつかの説明が必要です。 ニューラルネットワークコンストラクターの最初のパラメーターは、各レイヤーの入力とニューロンの数を含むリストです。learn_ratesは学習速度、 learn_rate_decaysは各時代の後の学習速度を設定する乗数、 epochsは学習時代の数、 verboseは学習プロセスの詳細レポートを表示するフラグです。
この手順を完了すると、必要なモデルが作成され、データをダウンロードするだけで済みます。 Kaggleは、 train.csvとtest.csvの 2つのファイルを提供しています。それぞれ、トレーニングとテスト用のサンプルが含まれています。 ファイル構造は単純です。最初の行にはヘッダーが含まれ、その後にデータが続きます。 train.csvでは、データの各行の前に、対応するラベル(画像を定義する0〜9の数字)が付きます。 test.csvにはラベルがありません。
次のステップでは、csvファイルを操作するためのパッケージを使用して、データを配列にロードします。 正規化することを忘れないでください:
import csv import numpy as np with open('D:\\train.csv', 'rb') as f: data = list(csv.reader(f)) train_data = np.array(data[1:]) labels = train_data[:, 0].astype('float') train_data = train_data[:, 1:].astype('float') / 255.0
その後、準備したデータでニューラルネットワークをトレーニングします。
net.fit(train_data, labels)
プロセス自体は、ニューラルネットワークの構築中に与えられたトレーニング時代の数によって決定される時間がかかります。 各トレーニングエポックで、画面には(詳細なパラメーターが設定された)損失とerr(損失関数とエラーの値)の値が表示されます。
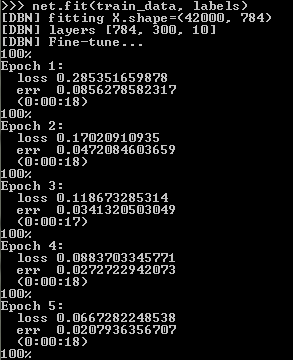
トレーニング後、テストデータをダウンロードし、テストサンプルの各画像の予測をcsv拡張子の付いたファイルに保存するだけです。
with open('D:\\test.csv', 'rb') as f: data = list(csv.reader(f)) test_data = np.array(data[1:]).astype('float') / 255.0 preds = net.predict(test_data) with open('D:\\submission.csv', 'wb') as f: fieldnames = ['ImageId', 'Label'] writer = csv.DictWriter(f, fieldnames=fieldnames) writer.writeheader() i = 1 for elem in preds: writer.writerow({'ImageId': i, 'Label': elem}) i += 1
次に、結果のファイルをテストシステムに読み込み(図を参照)、待機します。
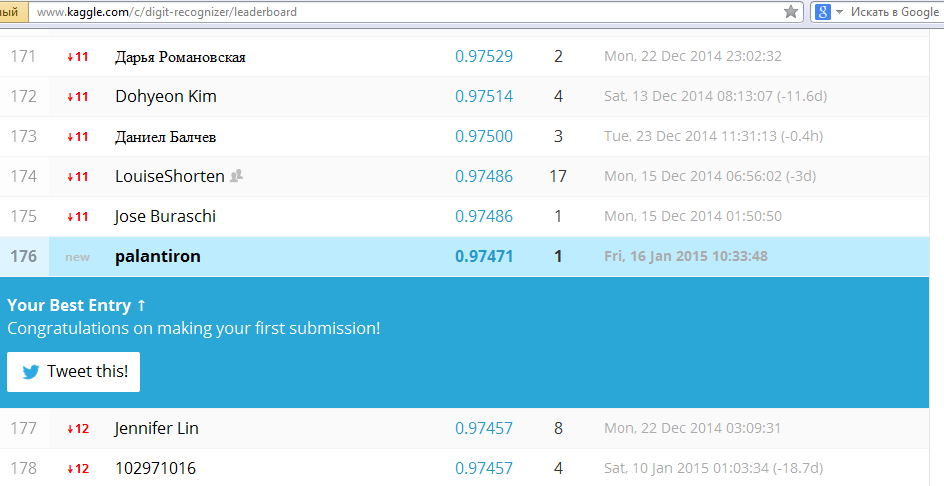
できた! 500人以上の参加者のうち176人が参加。 はじめに、それはかなり良いです。 これで、たとえば、独自の開発を適用したり、nolearnのパラメーターを変更および選択したりして、結果を改善することができます。 時間のメリットは十分です。MNISTでの競争は繰り返し延長され、現在は2015年12月31日まで開催されます。 この記事を読んでくれてありがとう。