PIC( Wikipediaに準拠)は、任意のメモリ領域に配置できるプログラムです。その中のメモリセルへの参照はすべて相対的であるためです。 このプログラムのコンパイル方法は、Android、ライブラリ、および他の多くのアプリケーションで使用されます。 現在、ほとんどのAndroidアプリは32ビットであるため、32ビットモードでのPICのGCCパフォーマンスは非常に重要です。
GCC 5.0は、特に暗号化、干渉からのデータ保護、データ圧縮、ハッシュなどのパフォーマンスが整数サイクルに集中しているアプリケーション、特にベクトル化されたアプリケーションを大幅に( 最大30% )加速することが期待されます適用されない理由。
GCC 4.9と比較してGCC 5.0では何が変更されましたか?
GCC 4.9では、EBXレジスタはグローバルオフセットテーブルまたはグローバルオフセットテーブル(GOT)のアドレス用に予約されているため、配布に使用できません。 したがって、32ビットモードのPICの場合、EAX、ECX、EDX、ESI、EDI、およびEBPの6つのレジスターのみが使用可能です(通常の7つではありません)。 これにより、配布に十分なレジスタがない場合、パフォーマンスが大幅に低下します。
GCC 5.0では、EBXレジスタを配布できます。 したがって、PICの空きレジスタの総数は絶対コードと変わりません。 以下は、レジスタがないループでの整数計算を使用したテストの結果です。
int i, j, k; uint32 *in = a, *out = b; for (i = 0; i < 1024; i++) { for (k = 0; k < ST; k++) { uint32 s = 0; for (j = 0; j < LD; j++) s += (in[j] * c[j][k] + 1) >> j + 1; out[k] = s; } in += LD; out += ST; }
どこで:
- cは定数行列です。
const byte c[8][8] = {1, -1, 1, -1, 1, -1, 1, -1, 1, 1, -1, -1, 1, 1, -1, -1, 1, 1, 1, 1, -1, -1, -1, -1, -1, 1, -1, 1, -1, 1, -1, 1, -1, -1, 1, 1, -1, -1, 1, 1, -1, -1, -1, -1, 1, 1, 1, 1, -1, -1, -1, 1, 1, 1, -1, 1, 1, -1, 1, 1, 1, -1, -1, -1};
このようなマトリックスは、サイクル内の計算を最小限に抑えて比較的速い加算と減算を行い、依存関係の数を増やすために使用されます。
- 入出力-グローバル配列「a [1024 * LD]」および「b [1024 * ST]」へのポインタ
- uint32は符号なし整数です
- LDおよびSTは、それぞれメモリダウンロードのグループの長さを決定し、メモリに保存するマクロです。
コンパイルオプション "-Ofast -funroll-loops -fno-tree-vectorize --param max-completely-peeled-insns = 200" plus Silvermontの "-march = slm"、 Haswellの "-march = core-avx2" -fPIC "for PIC and" -DLD = {4、5、6、7、8} -DST = 7 "
「-fno-tree-vectorize」-ベクトル化を回避するために使用されるため、xmmレジスター(同じ番号が常に使用可能)の使用
「--param max-completely-peeled-insns = 200」-GCC 5.0と4.9が等しい条件になるように使用されます。4.9では、このパラメーターは100でした。
4.9と比較したGCC 5.0のパフォーマンスの向上(加速の回数は、高いほど良い)。
X軸は、サイクル内のダウンロード数LDを変更します。 「LD」が増えると、見当合わせのプレッシャーが大きくなります。
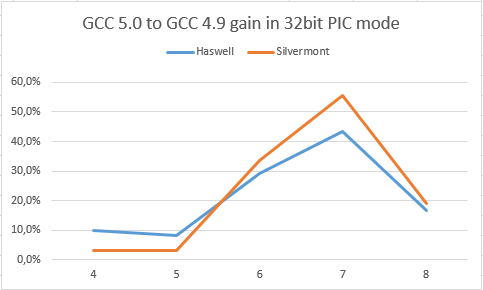
ここでは、SilvermontとHaswellの両方が印象的なゲインを示していることがわかります。 しかし、これがEBXレジスターの配布に追加されたために正確に発生したことを確認するには、以下の2つのチャートに目を向ける必要があります。
これらのグラフは、GCC 5.0およびGCC 4.9コンパイラーでのHaswellおよびSilvermontのPICへの切り替えからの減速を示しています(高いほど良い)
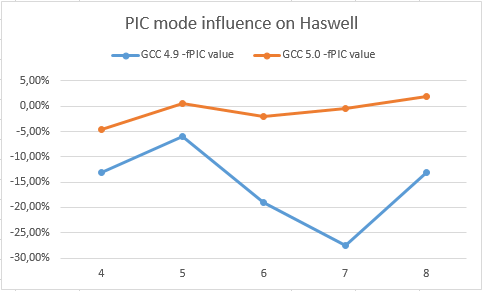
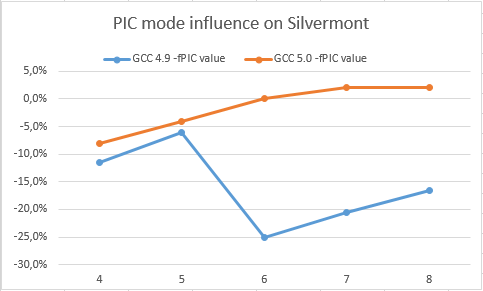
ここで、GCC 5.0がPICへの移行によって大きな損失を被っていないことがわかります。 それどころか、GCC 4.9はHaswellとSilvermontの両方でかなり遅くなります。 これにより、GCC 5.0がPICの整数サイクルを大幅に加速するはずです。 さらに、開発者は、ループプロモーション(アンロール)、関数置換(インライン)、不変式のより積極的な削除など、より積極的な最適化(レジスタ圧力の増加)を使用できます...
GCC 5.0を今すぐ試すことができます。 Android NDKへの移植も可能です。
測定に使用されるプロセッサ:
Silvermont :Intel®Atom(TM)CPU C2750 @ 2.41GHz
Haswell :Intel®Core(TM)i7-4770K CPU @ 3.50GHz
測定に使用されるコンパイラ:
英語の記事の元のテキストから測定値が取得された例をダウンロードできます。