タンタムポッサム量子シムス
おそらく誰もが同意するでしょう-監視はITインフラストラクチャの最も重要なコンポーネントの1つです。
散らばったRAID、根本的に詰まったルートパーティション、またはすべての合理的な制限を超えるLAを「突然」見つけたくないので、病棟の状態を知る必要があります。
ツール、機器の寿命を継続的に監視するために、誰もが自分で選択します。
Nagiosのような人、Muninを選ぶ人、独自のソリューションや他のソリューションを愛する人もいます。
お客様向けの監視サービスを作成する際、Zabbixを選択しました。
ただし、サーバーを監視に接続するだけでは十分ではありません。チケットシステムとユーザーの個人アカウントとの関係を整理する必要があります。 問題の存在を報告することに加えて、インシデントへの迅速な対応のためのテクニカルサポートサービスへの要求を自動的に作成し、さらにクライアントに電子メールで通知します。
habrokatの下で、私たちがそれをどのように行ったかを説明します。
説明
サービスを接続する手順について説明します。
まず、「監視」タブを選択します。
サービスの説明を読み、接続します。
すぐに使用できるように、私たちの意見では、最も重要なパラメーターを選択できます。

「設定」をクリックして、必要なしきい値と通知設定を設定します。
しきい値は、10%ずつ10%から90%の間で設定できます。
通知オプションを設定することもできます。

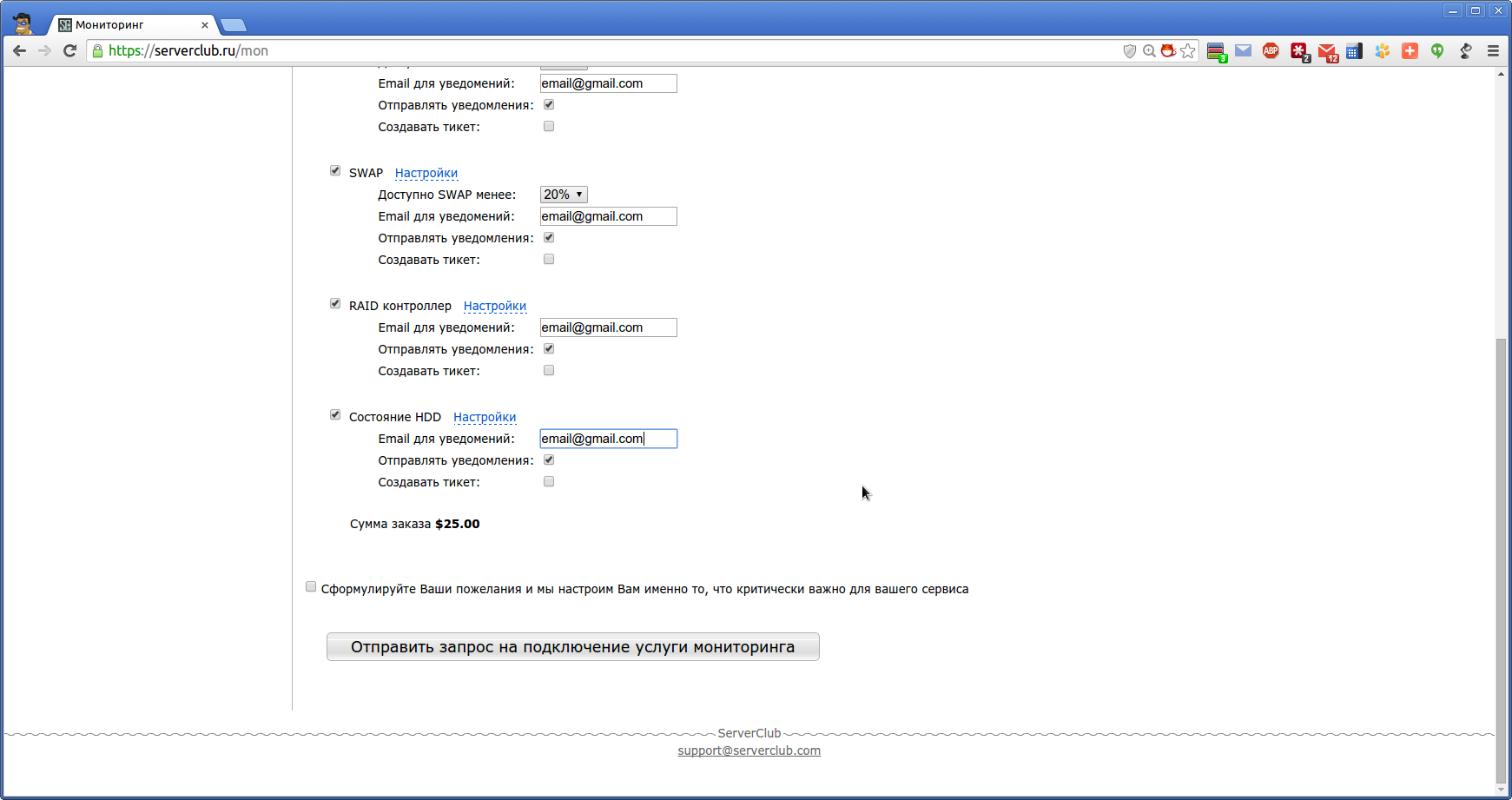
しかし、事前定義されたメトリックのセットが監視要件を完全に満たしていない場合はどうでしょうか?
この場合、特別な形式で希望を送信し、クライアントのニーズに合わせてサーバーの監視を構成できます。

サービスとチケットを接続するためのアプリケーションがシステム管理者向けに作成され、クライアントは詳細をさらに議論し、接続を制御できます。

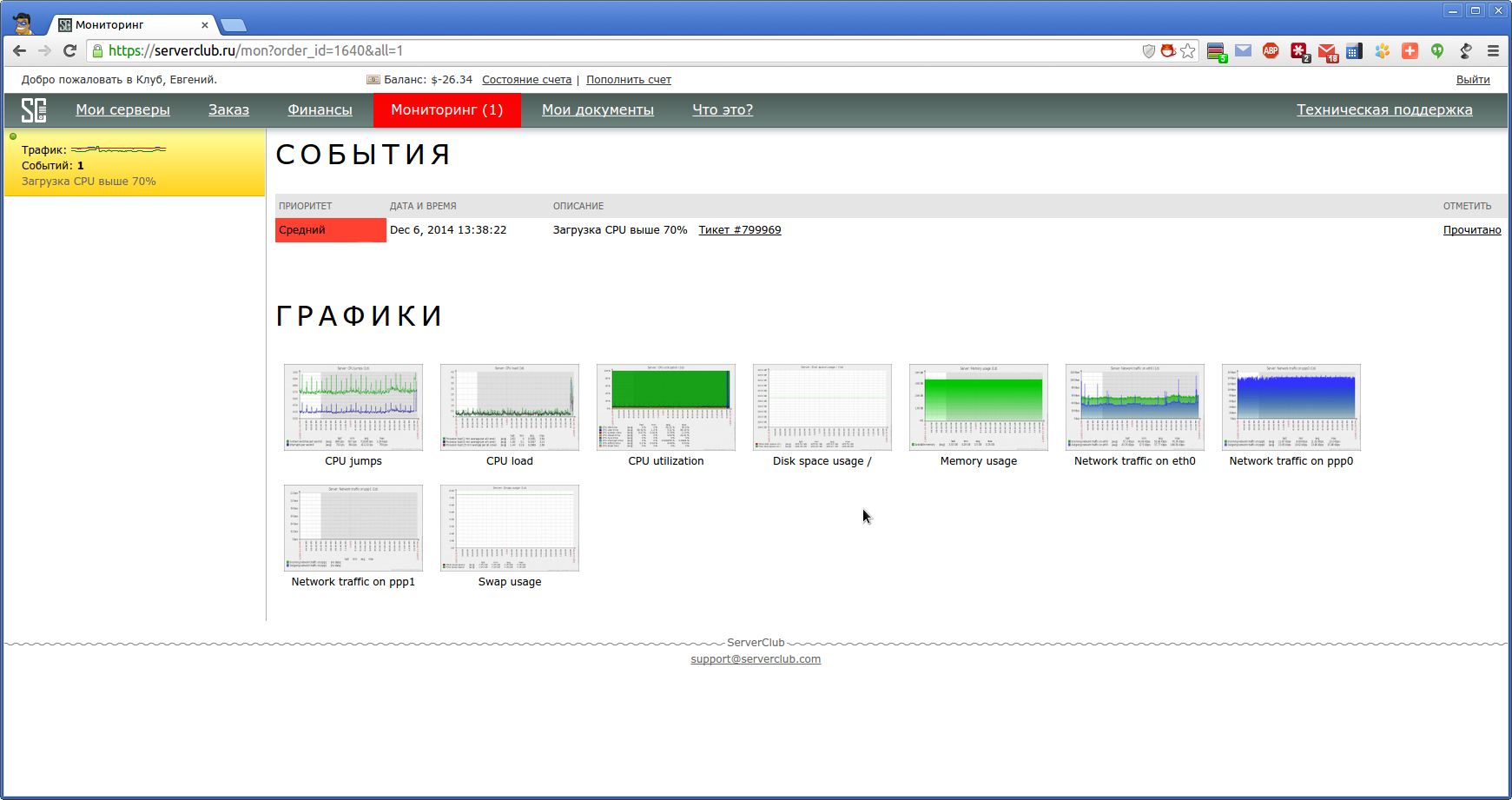
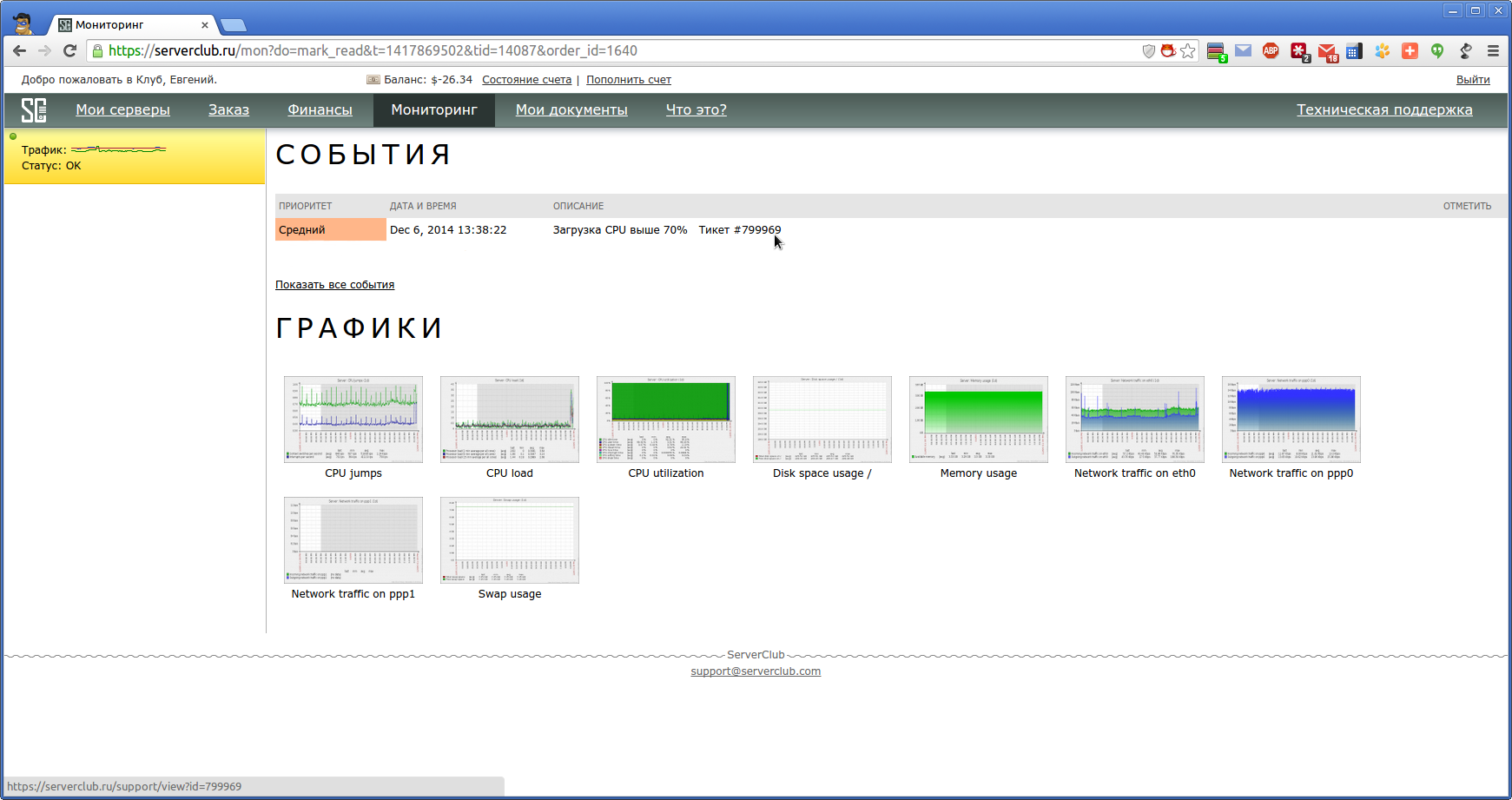
前に設定したしきい値を超えた場合、監視システムは個人アカウントの監視タブを赤で強調表示する問題を報告します。
また、クライアントに電子メール通知を送信し、勤務中のエンジニア向けのチケットを作成します(対応するチェックボックスがオンになっている場合)。
「読み取り」リンクをクリックして、カラー表示をオフにします。
トリガーされたトリガーの説明の後に、テクニカルサポートシステムのチケットへのリンクが表示されます。ここで、デューティエンジニアと詳細を確認できます。
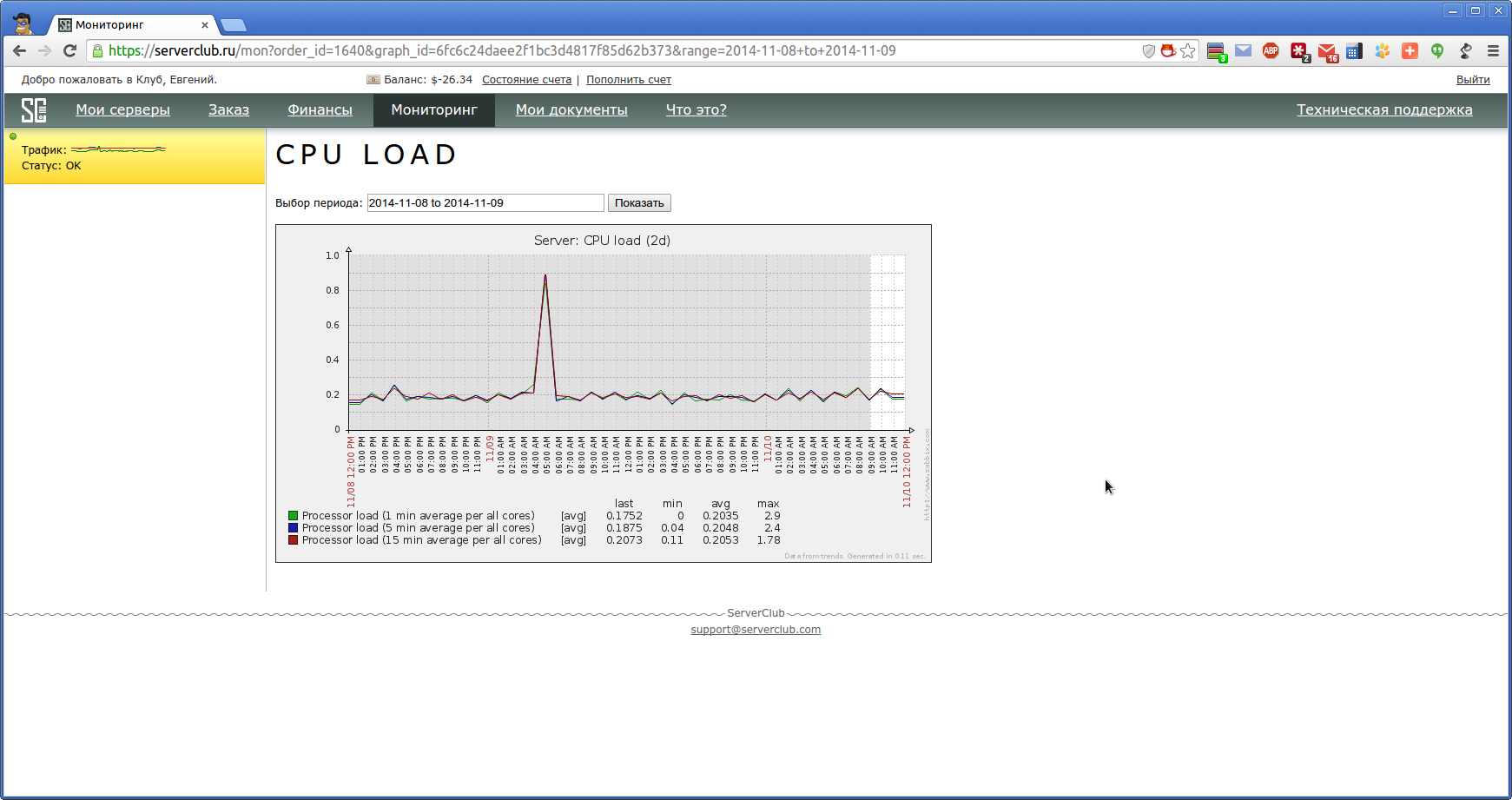
グラフごとに、データは目的の時間間隔のコンテキストで表示されます。
技術的な部分。
管理パネルとの統合のために、GitHubの広大さに見られるクラスを使用しました。
選択基準は、グラフの画像を受信する能力(APIにはそのような機能はありません)とクラス実装の単純さです。
他のいくつかは明確ではないような方法で書かれました-これはAPIを使用するため、または宇宙船を発射するためです。
このクラスはZabbixの2.2までのバージョン向けに設計されているため、少し改良する必要がありました。 必要な機能を追加し、使用しているバージョン2.4の認証を修正し、ZabbixAPI呼び出しのパラメーターをいくつか修正しました。
また、余分なデータを切り取って独自のヘッダーを挿入できるように、zabbixのチャート作成スクリプトも変更しました。
データはhttp / httpsを介して交換され、APIはjsonオブジェクトを配列として返します。
チャートは少し複雑になります-ブラウザがエミュレートされているかのように、つまり スクリプトは、curlを介したログイン/パスワードによって承認され、発行されたCookieを使用して、PNGファイルをスケジュールとともにダウンロードします。
チャート(およびそのプレビュー)の写真はredisに保存され、ライフタイムは1時間です。たとえば、スケジュールが更新されなかった場合、アカウントのユーザーへのスケジュールの最後の表示から1日が経過した場合など、ユーザーが終了しないように行われますページが更新されるたびに画像を作成することにより、zabbix。
画像は、一意のリクエストごとに形成されます。 ユーザーが監視を開始しない場合、システムはスケジュールを調整しません。
Zabbixへのすべてのリクエストは、md5ソルトハッシュに基づくキーによって隠されます。 リクエストパラメータもredisに保存され、ユーザーはアクセスできません。 特定のパラメーターと監視サーバーへのリンクは表示されません。
cronのスクリプトは、1分ごとにすべてのアクティブトリガーをチェックし、イベントが開始された日時と、そのようなトリガーがアクティブではなくなったことをテストで示した日時を記録します(サービスの接続時に選択されたトリガーのみが記録されます)。
トリガーをトリガーするために選択されたイベントに応じて、新しいアクティブトリガー、およびユーザーがまだアカウントで既読としてマークしていないトリガーに関するメッセージ、および/またはトリガーテキストでチケットが作成され、および/または「監視」メニュー項目が点滅します。
Zabbix自体では、説明内のトリガーテンプレートは「scm_ID trigger threshold%」、たとえば「scm_CPU 70%」として設定されます。これにより、注文後、スクリプト自体がトリガーID(各ホストとトリガーバリアントに固有)を見つけることができ、これにより説明を簡単に置き換えることができますscm_CPU 70% "on" CPU負荷が70%を超える "または" CPU負荷が70%を超える "。
管理パネルには、このホストで利用可能なすべてのスケジュール、トリガー、イベントが表示され、ユーザーはいつでもオン/オフを切り替えることができます。
いくつかの特定のものを監視するためのテンプレートがゼロから作成されたか、見つかったものが完成しました。わずかに修正されたデフォルトのテンプレートが私たちの仕様に合わせて修正されました。
関心が生じた場合は、コミュニティとベストプラクティスを共有できます。
以上です!
ご清聴ありがとうございました!