-要素がセットに正確に属していません。
-要素は多数に属する場合があります。
構造
集合Sに属する要素のハッシュは、構造に保存されます。
F = h(S)= {h(x)| xのS}
そのため、構造は確率的です。
要素Aを探しているとします。そのハッシュを計算し、構造を調べます。
状況1:アイテムハッシュが見つかりませんでした。 答えは、要素がセットに正確に属していないということです。
状況2:検索中にハッシュが見つかりましたが、それが要素Aに属しているかどうかを確認することはできません。2つの異なる要素のハッシュが一致することがあります(この一致は完全衝突-ハード衝突と呼ばれます)。 したがって、要素Aのハッシュが見つかったかどうか、または衝突であったかどうかを確実に言うことはできません。 答えは、要素がセットに属している可能性があるということです。
フィルターは、m = 2 ^ q個のハッシュグループを持つハッシュテーブルTとして表すことができます。 ハッシュをグループに配布するには、商法を使用します(フィルターの名前です)。 この方法は、Knutによって提案されました(コンピュータープログラミングの技術:検索と並べ替え、第3巻、セクション6.4、演習13)。
ハッシュは2つの部分に分割されます。
商fq = f /(2 ^ r)
剰余fr = f mod(2 ^ r)
結果として、フィルターにハッシュfを追加すると、グループfr [fq]に一部frが追加されます。 完全なハッシュは、式によって復元されます。
f = fq *(2 ^ r)+ fr
式([2]から取得)
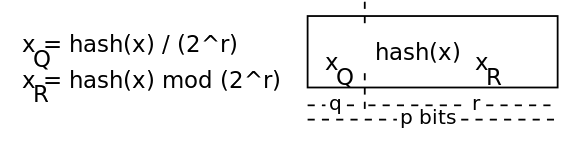
テーブルTは、長さ(r + 3)ビットのA [0..m-1]要素の配列として格納されます。 配列の各スロットには、ハッシュの残りと、ハッシュの回復に必要な3ビットの情報が格納されます。
2つのハッシュがプライベートに一致する場合、これはソフトコリジョンと呼ばれます。 プライベートハッシュと一致するすべてのハッシュは、(実行)セグメントの配列に順番に格納されます。 さらに、条件は常に保持されます。fq1<fq2の場合、fr1は常にfr2の前の配列にあります。
情報ビット
各剰余とともに格納された追加の3ビットが何をするかを見てみましょう。
1.ビットが占有されています(占有されています)。 スロットiがこのビットを持っている場合、商fq = iを持つ配列にハッシュがあります(ただし、このスロットにはないかもしれませんが、さらにシフトされます)。
2.は継続ビットです。 スロットiにこのビットがある場合、そこに格納されている剰余は、前のスロットi-1に格納されている剰余と同じセグメントに属します。
3.オフセットビット(シフトされます)。 設定されている場合、スロットiに保存されている剰余はグループiに属しておらず、単にシフトされていることを意味します。
オフセットビット= 0の場合、このスロットに属するスロット(fq = i)はスロットiに格納されます。 継続ビットにより、セグメントがいつ終了するかを理解できます。 ビジービットにより、回線が属するスロットを決定できます。
ウィキペディアでよく説明されている組み合わせ([2])
is_occupied
__is_continuation
____is_shifted
0 0 0:空のスロット
0 0 1:スロットは、正規のスロットからシフトされた実行の開始を保持しています。
0 1 0:使用されません。
0 1 1:スロットは、正規のスロットからシフトされた実行の継続を保持しています。
1 0 0:スロットは、正規のスロットにある実行の開始を保持しています。
1 0 1:スロットは、正規のスロットからシフトされた実行の開始を保持しています。
また、これが正規のスロットであるランも存在しますが、右にシフトされます。
1 1 0:使用されません。
1 1 1:スロットは、正規のスロットからシフトされた実行の継続を保持しています。
また、これが正規のスロットであるランも存在しますが、右にシフトされます。
空のスロットなしで連続して実行されるセグメントのグループは、クラスターと呼ばれます。 クラスターの最初のスロットは常にバイアスされません(オフセットビット= 0)。
例([1]から取得)
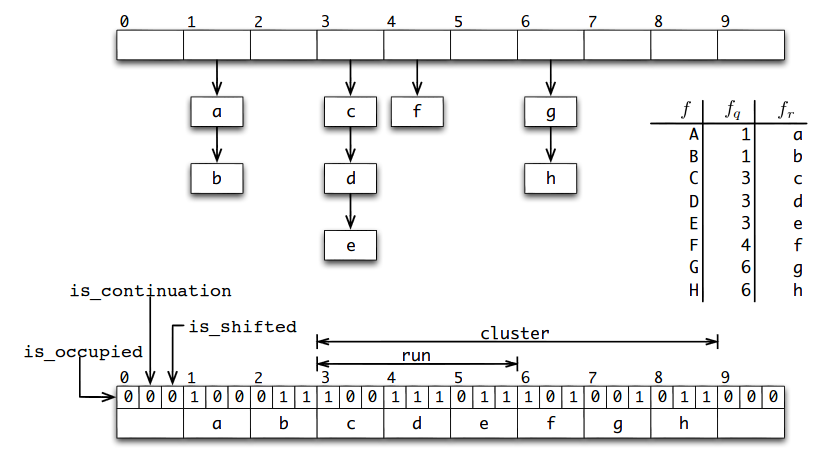
T.ハッシュテーブルが上部に表示され、多くの要素にはプライベートな商、たとえばaとbがあります。 以下は、これらの要素が格納される配列です。
要素検索
要素fのハッシュを見つけ、それを商fqと剰余frに分割します。 アレイのfqスロットを確認します。 ビジービットがオンでない場合、要素はフィルターに含まれません。
スロットがビジーの場合、セグメントの先頭を見つける必要があります。 セグメントの先頭は、そこに置かれたスロットにあるか、別のセグメントによってシフトされている可能性があるため、クラスターの先頭を探しています。
まず、クラスターの始まりが見つかるまで(オフセットビット= 0)fqスロットの左側に移動します。 左に進むと、スキップしたセグメントの数を覚えています。 ビジービットが設定された各スロットは、セグメントの始まりです。 このようなスロットごとに、セグメントカウンターを増やします。
クラスターの始まりを見つけたら、右に移動し始めます。 継続ビットが設定されていない各スロットは、新しいセグメントの始まりです。つまり、前のセグメントが終了しています。 そのようなスロットごとに、セグメントカウンタを減らします。 カウンターがゼロにリセットされると、必要なセグメントが見つかりました。 それに沿って実行し、残りのfrと比較します。 セグメントが終了し、残りが見つからない場合、その要素は間違いなくフィルター内にありません。 見つかった場合、そのアイテムはフィルター内にある可能性があります。
例([2]から取得)
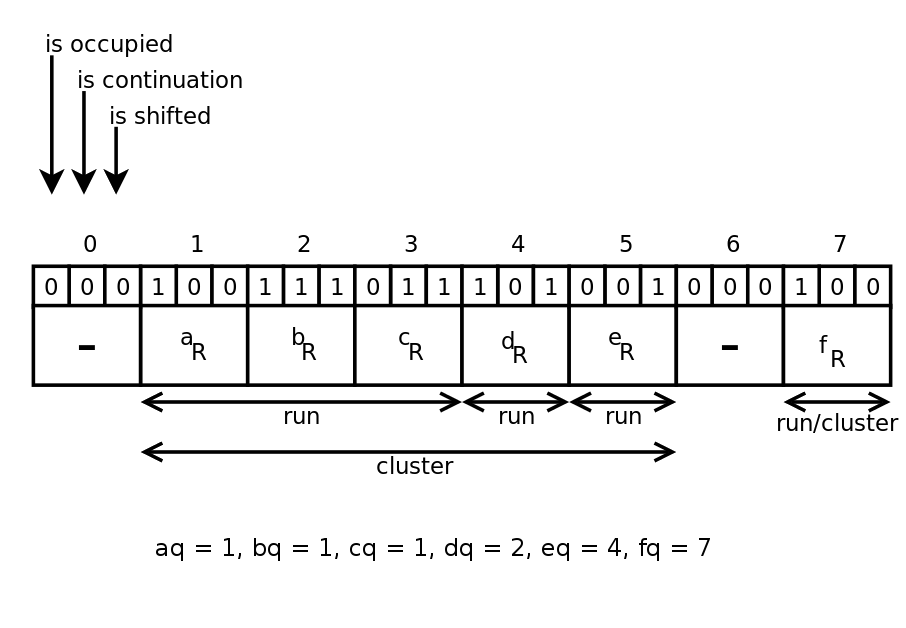
要素eを探しています。 ハッシュを計算し、ハッシュを商eqと剰余erに分割します。 eq =4。スロット4には占有ビットとオフセットビットがあり(残りのdrはその中にあります)、したがってこのスロットには要素がありますが、それはオフセットされました。 クラスターの始まりを探しています。
左に移動すると、3つのセグメント(スロット4、2、1でビジービット= 1)が渡されたことを覚えています。 スロット1-クラスターの始まり(オフセットビット= 0)、右に移動します。 各セグメントの始まりは、継続ビット= 0のスロットです。1番目のセグメントの場合-スロット1、2番目のセグメントの場合-スロット4、3番目の場合-スロット5。 3番目のセグメントには残りが1つだけあり、それは私たちが計算したerと一致します。 答えは、要素がセットに属している可能性があるということです。
アイテムの挿入/削除
要素の検索と同じアルゴリズムを使用して、frのスロットを探します。 スロットが見つかったら、必要に応じてfrを挿入/削除し、要素をシフトします。 次に、スロットA [fq]のビジービットを設定(挿入)または削除(削除、および削除されたアイテムがprivate = fqの唯一のものであった場合)します。
要素がシフトしても、ビジービットは変化しません。 セグメントの先頭に剰余が挿入された場合、このスロットを占有する剰余がシフトされ、セグメントの継続になるため、継続ビットが設定されます。 オフセットされた剰余ごとに、オフセットビットを設定します。
例([2]から取得)
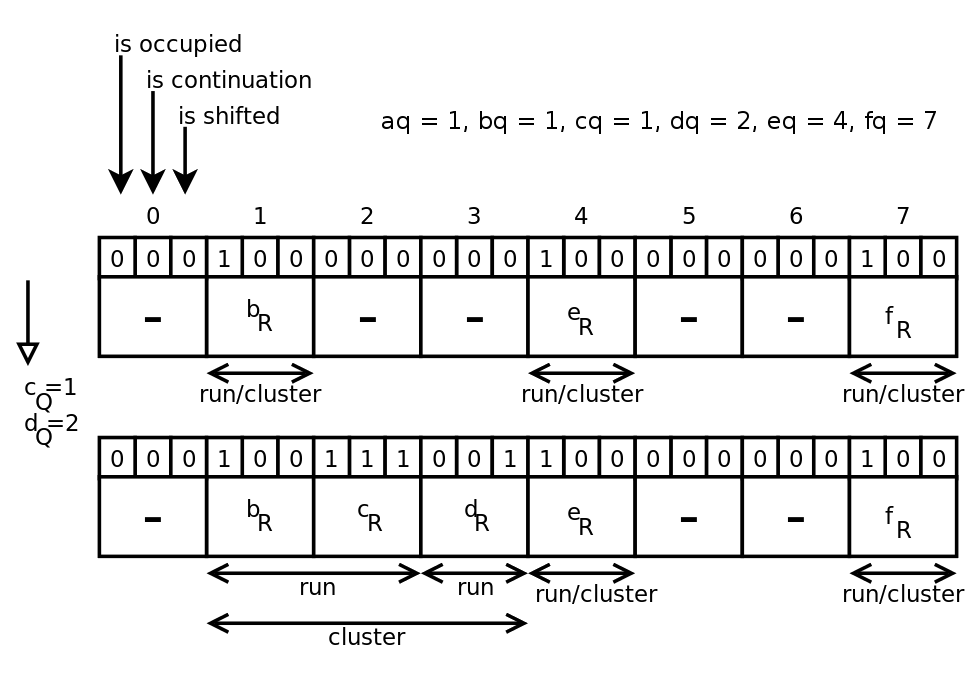
要素cとdが挿入されます。
bq = 1、cq = 1、br <cr。したがって、残りのcrはスロット2に挿入され、継続ビットとオフセットビットはスロット2に格納されます。
dq = 2であるため、スロット2にはビジービットがあります。 しかし、スロット2はすでに使用されているため、drはスロット3に入り、オフセットビットはスロット3に置かれます。
ブルームフィルターとの違い
なぜこのシステム全体が複雑なのですか? いくつかの利点があります。
1.すべてのデータはメモリ内に順番に配置されます。 必要なクラスターのみをロードする必要があります。これは通常、アレイ全体ではなく、小さいクラスターです。 これにより、プロセッサデータキャッシュからの読み取りのミス数が減少します。
2.アレイのサイズを縮小/拡大する機能。 これを行うには、データを再度ハッシュする必要はありません。残りの1ビットをプライベートビットに転送するだけです。
3. 2つのフィルターを1つにマージします。
参照資料
1. vldb.org/pvldb/vol5/p1627_michaelabender_vldb2012.pdf-作成者によるフィルターの説明
2. en.wikipedia.org/wiki/Quotient_filter-すばらしいウィキペディアの記事
エラーと不正確さについて書いてください-私は喜んでそれを修正します。