私が最初に決めたのは、すべての同期作業を処理する別個の「ワーカー」プロセスを作成することでした。 「ワーカー」は可能な限りシンプルで、キューからタスクを1つずつ実行するように計画しました。 たとえば、データベースから何かを選択し、答えて、次のタスクを引き継いだ、などです。 多くの「ワーカー」を自分で実行することができ、AMQPはすでに一種のIPCとして機能します。
しばらくして、これからモジュールが成長しました。このモジュールはAMQPに関連するすべてのルーチンを引き受け、メッセージを送受信し、データが多すぎる場合はgzipで圧縮します。 それで、 乗組員が生まれました。 実際に、それを使用して、トルネード上のサーバーと単純で単純な「ワーカー」プロセスで構成される単純なAPIを作成します。 今後は、すべてのコードがgithubで利用可能であり、後で説明する内容はサンプルフォルダーに収集されます 。
準備する
それでは、順番に考えてみましょう。 最初に行う必要があるのは、RabbitMQのインストールです。 これを行う方法については説明しません。 私は同じubuntuにインストールされており、箱から出してすぐに動作すると言うことができます。 私のMacでは、LaunchRocketをインストールするだけで、homebrewを介してインストールされ、GUIに表示されるすべてのサービスを収集しました。

次に、virtualenvプロジェクトを作成し、pipを使用してモジュール自体をインストールします。
mkdir -p api cd api virtualenv env source env/bin/activate pip install crew tornado
モジュールの依存関係は、竜巻を意図的に示すものではありません。ワーカーがいるホストには存在しない可能性があるためです。 また、Webパーツでは、通常、requirements.txtを作成し、他のすべての依存関係をリストします。
物語の順序に違反しないように、コードを部分的に記述します。 最終的に得られるものは、 ここで見ることができます 。
コードを書く
竜巻サーバー自体は2つの部分で構成されています。 最初の部分では、要求ハンドラーのハンドラーを定義し、2番目の部分では、イベントループを起動します。 サーバーを作成して、最初のapiメソッドを作成しましょう。
Master.pyファイル:
# encoding: utf-8 import tornado.ioloop import tornado.gen import tornado.web import tornado.options class MainHandler(tornado.web.RequestHandler): @tornado.gen.coroutine def get(self): # test c 100 resp = yield self.application.crew.call('test', priority=100) self.write("{0}: {1}".format(type(resp).__name__, str(resp))) application = tornado.web.Application( [ ('/', MainHandler), ], autoreload=True, debug=True, ) if __name__ == "__main__": tornado.options.parse_command_line() application.listen(8888) tornado.ioloop.IOLoop.instance().start()
コルーチンの竜巻のおかげで、コードはシンプルに見えます。 コルーチンなしで同じことを書くことができます。
Master.pyファイル:
class MainHandler(tornado.web.RequestHandler): def get(self): # test c 100 self.application.crew.call('test', priority=100, callback=self._on_response) def _on_response(resp, headers): self.write("{0}: {1}".format(type(resp).__name__, str(resp)))
サーバーの準備ができました。 しかし、それを実行して/に移動すると、答えを待つことはありません。処理する人はいません。
次に、単純なワーカーを作成します。
ファイルworker.py:
# encoding: utf-8 from crew.worker import run, context, Task @Task('test') def long_task(req): context.settings.counter += 1 return 'Wake up Neo.\n' run( counter=0, # This is a part of this worker context )
そのため、コードでわかるように、 タスク (「テスト」)デコレータでラップされた単純な関数があります。ここで、テストはタスクの一意の識別子です。 ワーカーが同じ識別子を持つ2つのタスクを持つことはできません。 もちろん、タスクに「crew.example.test」という名前を付けるのは正しいでしょう(通常は実稼働環境で呼び出します)が、この例では「test」だけで十分です。
Context.settings.counterはすぐにわかります。 これは、run関数が呼び出されたときにワーカープロセスで初期化される特定のコンテキストです。 また、コンテキストでは、context.headersはすでに存在します-これらは、応答からメタデータを分離するための応答ヘッダーです。 コールバック関数の例では、この辞書は_on_responseに渡されます。
ヘッダーは各応答後にリセットされますが、context.settingsはリセットされません。 context.settingsを使用して、データベースへの接続と、通常は他のオブジェクトをワーカー関数に渡します。
ワーカーはスタートアップキーも処理しますが、多くはありません。
$ python worker.py --help Usage: worker.py [options] Options: -h, --help show this help message and exit -v, --verbose make lots of noise --logging=LOGGING Logging level -H HOST, --host=HOST RabbitMQ host -P PORT, --port=PORT RabbitMQ port
データベース接続URLおよびその他の変数は、環境変数から取得できます。 したがって、パラメーター内のワーカーは、AMQP(ホストとポート)およびログレベルに接続するのを待つだけです。
だから、すべてを実行して確認してください:
$ python master.py & python worker.py
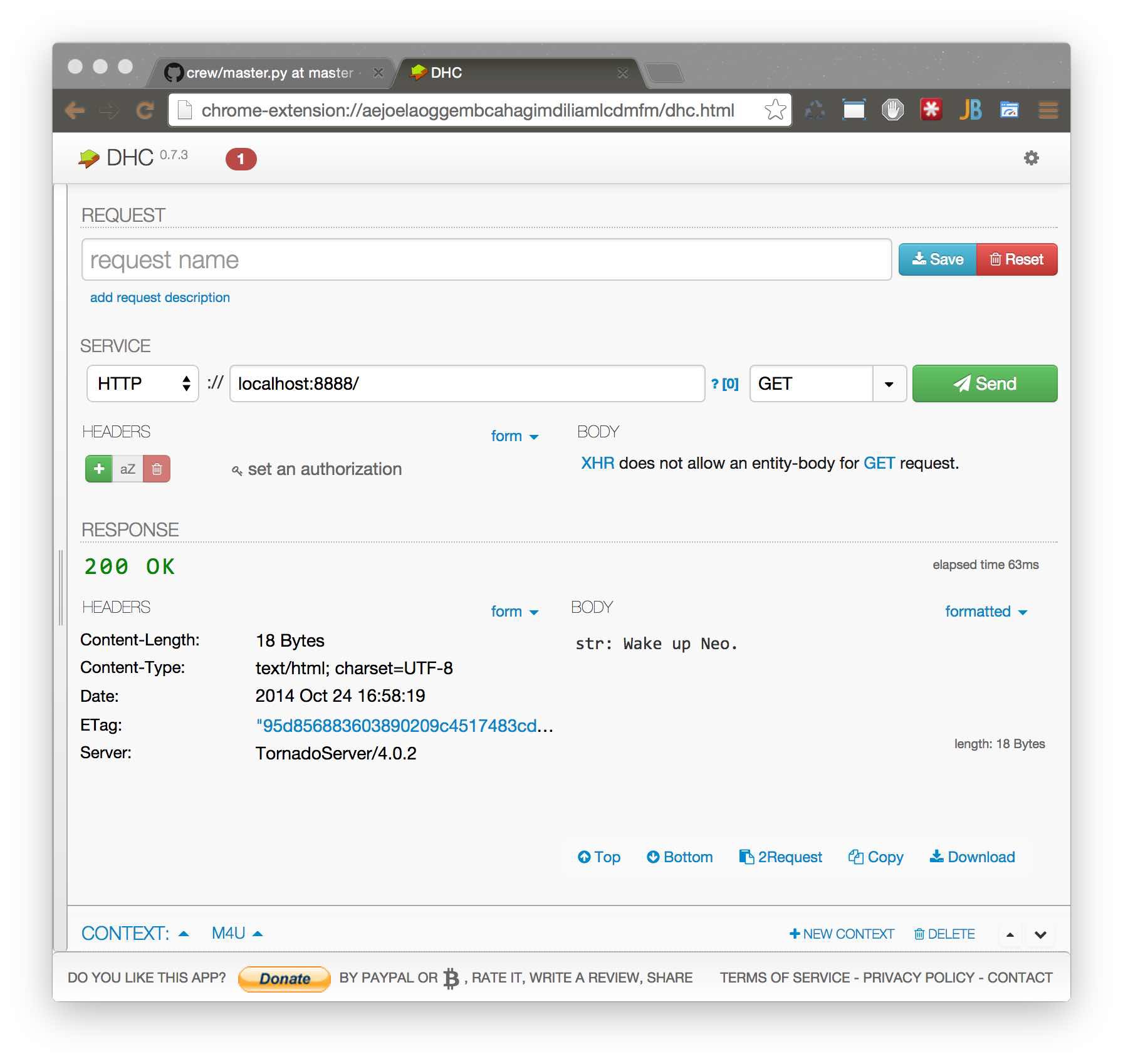
それは機能しますが、画面の後ろで何が起きましたか?
トルネードサーバーが起動すると、トルネードはRabbitMQに接続し、Exchange DLXを作成して、DLXキューのリッスンを開始しました。 このDead-Letter-Exchangeは、特定のタイムアウトでワーカーが実行しなかったタスクを受け取る特別なキューです。 彼はまた、ワーカーからの応答を受信する一意の識別子を持つキューを作成しました。
開始後、ワーカーはタスクデコレータによってラップされた各キューに対して順番に作成し、サブスクライブしました。 タスクが到着すると、メインループワーカーは1つのスレッドを作成し、メインスレッドでタスクの実行時間を制御し、ラップされた機能を実行します。 ラップされた関数から戻った後、関数をシリアル化し、サーバーの応答をキューに入れます。
リクエストが受信されると、トルネードサーバーはタスクを適切なキューに配置し、応答を受信する一意のキューの識別子を示します。 ワーカーがタスクを引き受けなかった場合、RabbitMQはタスクをリダイレクトしてDLXを交換し、トルネードサーバーはキュータイムアウトが期限切れになったというメッセージを受信し、例外をスローします。
凍結タスク
実行中にハングするタスクを完了するためのメカニズムがどのように機能するかを示すために、別のWebメソッドとタスクをworkerで作成します。
master.pyファイルに追加します。
class FastHandler(tornado.web.RequestHandler): @tornado.gen.coroutine def get(self): try: resp = yield self.application.crew.call( 'dead', persistent=False, priority=255, expiration=3, ) self.write("{0}: {1}".format(type(resp).__name__, str(resp))) except TimeoutError: self.write('Timeout') except ExpirationError: self.write('All workers are gone')
そして、それをハンドラーのリストに追加します。
application = tornado.web.Application( [ (r"/", MainHandler), (r"/stat", StatHandler), ], autoreload=True, debug=True, )
そしてworker.pyで:
@Task('dead') def infinite_loop_task(req): while True: pass
上記の例からわかるように、タスクは無限ループに入ります。 ただし、タスクが3秒以内に完了しない場合(キューから受信した時間をカウント)、ワーカーのメインループはSystemExit例外をスレッドに送信します。 そして、はい、あなたはそれを処理しなければなりません。
コンテキスト
前述のように、コンテキストはインポートされ、いくつかの組み込み変数を持つ特別なオブジェクトです。
ワーカーの回答に関する簡単な統計を作成しましょう。
次のハンドラーをmaster.pyファイルに追加します。
class StatHandler(tornado.web.RequestHandler): @tornado.gen.coroutine def get(self): resp = yield self.application.crew.call('stat', persistent=False, priority=0) self.write("{0}: {1}".format(type(resp).__name__, str(resp)))
また、リクエストハンドラのリストに登録します。
application = tornado.web.Application( [ (r"/", MainHandler), (r"/fast", FastHandler), (r"/stat", StatHandler), ], autoreload=True, debug=True, )
このハンドラーは、前のハンドラーと大差なく、単にワーカーが渡した値を返します。
これでタスク自体。
worker.pyファイルに追加します。
@Task('stat') def get_counter(req): context.settings.counter += 1 return 'I\'m worker "%s". And I serve %s tasks' % (context.settings.uuid, context.settings.counter)
この関数は、ワーカーによって処理されたタスクの数に関する情報を含む文字列を返します。
PubSubおよびロングポーリング
次に、いくつかのハンドラーを実装します。 リクエストに応じて1つは単にハングして待機し、2つ目はPOSTデータを受け取ります。 後者の転送後、最初のものはそれらを渡します。
master.py:
class LongPoolingHandler(tornado.web.RequestHandler): LISTENERS = [] @tornado.web.asynchronous def get(self): self.LISTENERS.append(self.response) def response(self, data): self.finish(str(data)) @classmethod def responder(cls, data): for cb in cls.LISTENERS: cb(data) cls.LISTENERS = [] class PublishHandler(tornado.web.RequestHandler): @tornado.gen.coroutine def post(self, *args, **kwargs): resp = yield self.application.crew.call('publish', self.request.body) self.finish(str(resp)) ... application = tornado.web.Application( [ (r"/", MainHandler), (r"/stat", StatHandler), (r"/fast", FastHandler), (r'/subscribe', LongPoolingHandler), (r'/publish', PublishHandler), ], autoreload=True, debug=True, ) application.crew = Client() application.crew.subscribe('test', LongPoolingHandler.responder) if __name__ == "__main__": application.crew.connect() tornado.options.parse_command_line() application.listen(8888) tornado.ioloop.IOLoop.instance().start()
公開タスクを書きましょう。
worker.py:
@Task('publish') def publish(req): context.pubsub.publish('test', req)
ワーカーに制御を移す必要がない場合は、竜巻サーバーから直接公開できます。
class PublishHandler2(tornado.web.RequestHandler): def post(self, *args, **kwargs): self.application.crew.publish('test', self.request.body)
並列タスク
多くの場合、いくつかのタスクを並行して完了することができる状況があります。 乗組員は、このために少し構文上の砂糖を持っています:
class Multitaskhandler(tornado.web.RequestHandler): @tornado.gen.coroutine def get(self, *args, **kwargs): with self.application.crew.parallel() as mc: # mc - multiple calls mc.call('test') mc.call('stat') test_result, stat_result = yield mc.result() self.set_header('Content-Type', 'text/plain') self.write("Test result: {0}\nStat result: {1}".format(test_result, stat_result))
この場合、タスクは2つのタスクを並行して設定され、withの終了は最後の最後に行われます。
ただし、タスクによっては例外が発生する可能性があるため、注意が必要です。 これは変数と直接同一視されます。 したがって、test_resultとstat_resultがExceptionクラスのインスタンスであるかどうかを確認する必要があります。
今後の計画
eigradが、乗組員を使用してwsgiアプリケーションを実行できるレイヤーの作成を提案したとき、私はすぐにこのアイデアが気に入りました。 想像すると、リクエストはwsgiアプリケーションには流れませんが、キューを介してwsgi-workerに均等に流れます。
私はwsgiサーバーを書いたことがなく、どこから始めればよいかさえわかりません。 しかし、あなたは私を助けることができます、私が受け入れるプルリクエスト。
また、ツイスト用の別の一般的な非同期フレームワークのクライアントを追加することも考えています。 しかし、私が彼に対処している間、十分な自由時間がありません。
謝辞
RabbitMQおよびAMQPの開発者に感謝します。 素晴らしいアイデア。
また、読者に感謝します。 時間を無駄にしないことを願っています。