キークエリの競合の程度を評価することは、検索エンジン最適化の神聖なタスクの1つです。 競合他社に気付かれずに良好な変換でクエリを見つけることの希望は、フィロソボの石を見つけることに似ています。 試してみましょう、私たちはこの錬金術の集まりに貢献します。
2つの相互接続されたクエリの検索結果を比較するだけで、ほぼ瞬時に競合の程度を推定できることがわかります-プゾメルキ、競合サイト、クリックコスト統計、大量の情報を分析することなく。
背景
特定のキーリクエストに対するトップでの昇格の難しさは、当然、1位を争う競合他社の数に関連しています。 この「困難」の程度を評価する方法はいくつかあります。 最も一般的なものを次に示します。
ランキング要因の分析 。 この方法では、検索結果自体とそれに含まれるサイトを分析します。サイトの総数、コンテキスト広告の数、リンクの平均数、各サイトの最適化の程度などです。 次に、重み関数を使用してこの情報を1つの指標KEI(キーワード有効性指数)に減らし、クエリを比較します。 この方法の適用に関する主な問題は、指標の選択、それらの(自動)測定方法、および重量です。 Yandexは800個の重要なパラメーターを使用してピースをランク付けすることに注意してください。
コンテキスト広告率の分析 。 この方法は、コンテキスト広告システム(Yandex Direct、Google AdWords)でのクリックコストのオークションレートの推定と比較に帰着します。 接続は明確です-要求が「より興味深い」、より多くの広告主が第一位のために戦っている、より高いレート。 ただし、コンテキストと検索エンジン最適化における価格形成の原則は異なり、見積もりの精度に影響する可能性があります。
競争力のある予算との比較 。 この情報は、ユーザーの統計として多数の自動プロモーションシステム(SeoPult、Rookee)で利用できます。 しかし問題は、中頻度および低頻度のクエリでは、そのような統計では十分でない可能性があるため、コストの推定値として標準の最小量を確認できることが多いということです。 さらに、このような予算の主な(唯一ではないにしても)コンポーネントは参照予算です。 また、リンクの役割はかつてないほど小さくなっています。
アイデア
しかし、検索エンジンのクエリ言語のいくつかのプロパティに基づいた別の興味深い方法があります。 この言語には、通常、幅広く正確なクエリなどの概念があります。 その意味は、幅広いリクエストに応じて、すべての単語形式で任意の単語の順序で、正確な単語に応じて-リクエストが形成された形式で情報を取得できるということです。
たとえば、Yandex検索言語表記では、広範なクエリは次のようになります
[車を買う]そして正確に
["!buy!car"]
検索エンジン最適化サイトの主な要件は、サイト内のテキストおよびマークアップ内での検索クエリの正確な出現の存在、ならびに外部および内部リンクのアンカーとしての使用です。 その結果、特定のクエリ用に最適化されたサイトは、検索クエリが正確に多数発生するように最適化されていないサイトとは異なります。
リクエストが非常に競争力がある場合、最適化されたサイトが多数あり、検索アルゴリズムに選択できるものがたくさんあるため、広く正確なクエリの結果の結果の差はそれほど変わりません。 クエリの競争力が低い場合、検索アルゴリズムは最適化されたサイトの不足を残りの部分で補います。検索クエリに近いが、おそらく異なる形態と異なる順序で単語を見つけることができるサイトです。
その結果、競争が低ければ低いほど、検索結果はより多様で「緩い」ものになり、新しい候補者がより簡単に侵入できるようになります。 競争が高ければ高いほど、多様性は低くなり、関係する同じ人で満たされる可能性が高くなり、彼らの間を絞ることは容易ではありません。
例として、(さまざまな程度の競争を保証するために)自動車のトピックからのいくつかの異なるリクエストを見て、Yandexでそれらに何が起こるかを見てみましょう。
これらのクエリの幅が広く正確な形式、および幅の広いクエリの頻度は次のとおりです。
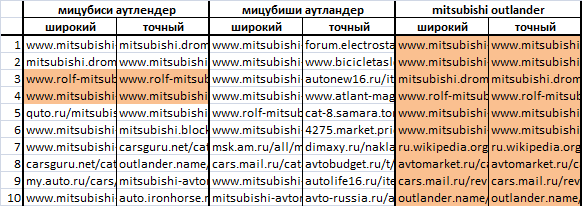
[crossover] ["!crossover"](239,714) [三菱アウトランダー] ["!三菱アウトランダー"](73,760) [三菱アウトランダー] ["!三菱アウトランダー"](68,149) [三菱アウトランダー] ["!三菱アウトランダー"](128) [三菱アウトランダー] ["!mitsubishi!outlander"](41,392)
これらのクエリのランキング結果は次のようになります。 ここで、色は、幅広く正確なオプションの発行で一致するサイトを示します。
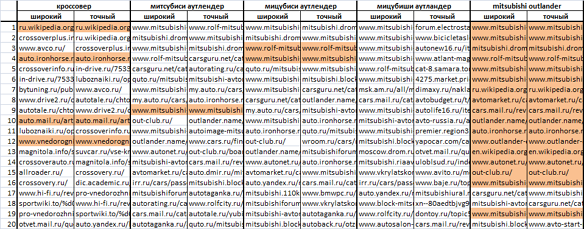
肉眼で見ると、[三菱アウトランダー](41,392)と[三菱アウトランダー](128)の違いがすぐにわかります。つまり、明らかに競合が異なる要求の間です。
計算
視覚的には、アイデアは明確です-広く正確な検索クエリフォームでの検索結果の差が大きいほど、競合は少なくなります。 品種が少ないほど、競争が激しくなります。 しかし、今それを数える方法は? この多様性の程度を測定する方法は?
このために、 「検索結果の変動性の推定」で得られた評価間の距離の式を使用します 。
この式の計算例はここにあります 。
したがって、2つの評価R 'とR ' 'の間の加重相対距離を計算するための次の式があります。
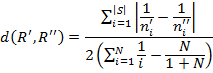
ここに:
N-評価の長さ(TOP5、TOP10など);
| S | -セットS = R ' U R ' 'の要素数、つまり、2つの評価における一意のオブジェクトの総数。
n ' iおよびn ' ' iは、それぞれ格付けR 'およびR ''におけるi番目の要素の位置であり、オブジェクトが格付けに含まれていない場合、この格付けにおけるその位置はN +1と見なされます。
結果の種類が多いほど、評価間の距離は大きくなります。 したがって、競争の度合いとして、距離と反対の値を使用します。
Cn = 1 - d
リクエストについては、TOP100レーティングに従って、以下の競争度の値(パーセント)を取得します。
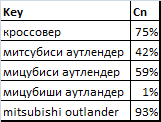
ここでの質問は、検索結果を表示する深さです。 それに答えるには、次の表に示されている格付けの長さに対する競争の度合いの依存性が役立ちます。
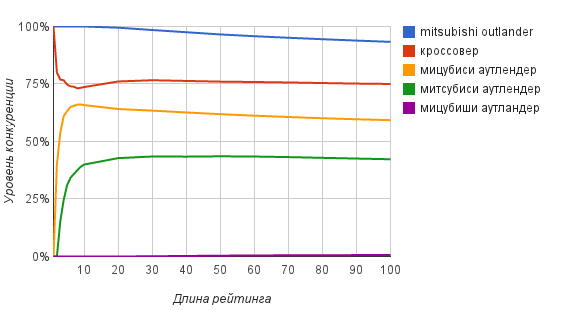
グラフからわかるように、すでにTOP20〜TOP30レベルで、競争の程度のかなり正確な推定値を取得できます。
承認
競合の度合いをより正確に評価する方法は、検索ランキングのトップに到達するためのコストを反映していますか? この質問に対する答えがわかりません。 単純な質問に対する答えがわかりません-SEOの実際の費用を計算する方法。 または、少なくとも特定の(個別の)キーリクエストの最適化の実際のコスト。
それでは、測定できない値を予測する精度をどのように評価できますか?
状況は栄養学のようなものです。あなたはたくさんのダイエットを思いつくことができますが、平均寿命に影響を与えたものを本当に評価することは不可能です。 そして栄養学のように、おそらく多くの世代の経験を通してのみ答えを得ることができます。
それまでの間、提案された方法の精度をチェックする唯一のオプションは、常識と類似物との比較です。 まあ、単純さと利便性の面では、彼には競合他社がいません。 結局のところ、彼は新たに出現した重要なフレーズについても見積もりを出すことができます(トレンドで稼ぐ人に注意してください)!
類似物については、上記の方法のいくつかを使用して競合の程度を評価した比較結果を以下に示します。
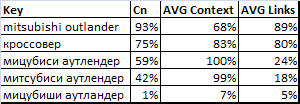
ここに:
Cn-私たちの方法によって得られた競争の程度の評価。
AVGコンテキスト -コンテキスト広告システム(Yandex DirectおよびGoogle AdWords)のクリック費用統計に基づく推定。 値は平均化および正規化されます(クリックあたりの最大コストは100%とみなされます)。
AVGリンク -推奨予算に従って自動プロモーションシステム(SeoPult、SeoPult PRO、Rookee)で得られた見積もり。 値は平均化および正規化されます(最大予算は100%とみなされます)。
値は異なりますが、主なことは、 CnおよびAVGリンクの評価を使用する場合、ランキングの順序が同じであることです。 これら2つの推定値のどちらがより正確であるかを言うのは困難ですが、5つのうち3つの要求のSeoPult PROソースデータには統計が含まれていません(可能な最小システム予算が提案されました)。 したがって、私たちのアルゴリズムがこのタスクをより良く処理できると信じるあらゆる理由があります。
コンテキスト入札AVG Contextの予測に関しては、明らかに一般的な傾向から外れています。 この方法は慎重に使用してください。
おわりに
提案された方法の単純さは明らかです。 計算の精度は非常に良いようです。 さらに、他の方法では無力な状況で成績を取得する機能。
競合他社の