たとえば、特定のアプリケーションをjsfiddle.netに簡単に配置でき、そのバックエンドは別のドメインに配置されます。
JSFiddle内にある本格的な動作する最終製品(データ交換を集中化するために特定のサーバーを必要とする)がおかしく見えることに同意します!
この記事の目的は、2つの側面からの現在の経験を共有することです。
- JSONP +ロングポーリングの実装
- 素晴らしいRedisと連携する
BackendLessのメンバーは同様のことをしています。
何がありますか
だから私たちは持っています:
- Python 2.xを搭載した独自のサーバー
- ブラウザとJSFiddle.netへのアクセス
- API-over-JSONPを構築したい
私が使用したもの
ジョンソン
読者はそれが何であるかの説明を必要としないと思います。 実装に関しては、すべてが1人のデコレーターによって行われます。
def jsonp(fn): def wrapper(*args, **kwargs): callback = request.args.get('callback', None) if not callback: raise BadRequest('Missing callback argument.') return '{callback}({data});'.format( callback=callback, data=dumps(fn(*args, **kwargs)) ) wrapper.__name__ = fn.__name__ return wrapper
レディス
そのような素晴らしいものがあります-Redis。 開発者がそれについて言うように、
Redisは、オープンソース、BSDライセンス、高度なキーと値のキャッシュおよびストアです。 キーには文字列、ハッシュ、リスト、セット、ソートされたセット、ビットマップ、およびハイパーログが含まれているため、データ構造サーバーと呼ばれることがよくあります。
または簡単に言うと:
Redisは、強力なキーと値のストレージおよびキャッシュシステムです。
Redisについて
Redisに慣れていない場合は、オフィスでそれについて読むことをお勧めします。 なぜなら、それを扱うことのすべての微妙な点が以下で説明されるわけではないからです。
実際、Redis自体は独立したデーモンとして機能し、Pythonスクリプトからは、同じ名前のかなり単純なコネクタモジュールを介してアクセスします。
キーを作成して割り当てることができます。
- スカラー値(実際には文字列 )
- 一覧
- 配列
- 多くの
- ソートセット
しかし! たとえば、配列の配列を作成することはできません。 したがって、この場合、インデックスのリストと各インデックスのキーでキーを作成する必要があります。 また、値によるサンプリング(SQLのWHEREなど)がないため、たとえば、ニックネームでユーザーIDを検索したり、IDでユーザーニックネームを検索したりするために、逆「マッピング」でリストを作成する必要があります。
大まかに言うと 、SQLのテーブルとは、Redisのインデックスのリスト と配列のセットです 。 キーの一部をコロンで区切ることも慣習です。
SQLの例: 1つのテーブル-フィールドuser_id、user_name、user_emailおよび5レコード。
Redisでの類推: 1つのリストと5つの配列-データ[1、2、3、4、5]を持つユーザーのリストと、 user:Xのデータ{id:X、name:Y、email:という形式の名前(キー)を持つ5つの配列Z}、およびフィードバック付きのいくつかの配列、たとえば値{andrew:1、john:2、mike:3、...}のニックネーム
なぜredis
- Redisはデータ構造を定義する必要がありません:それらをそこに置くだけです。
- Redisデータベース内のデータを使用してCRUD ( Create-Read-Update-Delete )を実行し、組み込みのロックメカニズムを使用することもできます-ところで、それは、 長いポーリングメカニズムの実装を大幅に簡素化します。
- Redisは、JOINやWHEREをどのように結合するかを知りません。プリミティブ、最大リスト、またはプリミティブからの連想配列を保存するだけです。 ただし、これはマイナスではなく、アクションの追加の自由と思考を拡張するインセンティブです。これは、SQLおよびNoSQL-DBMSパターンとは異なります。
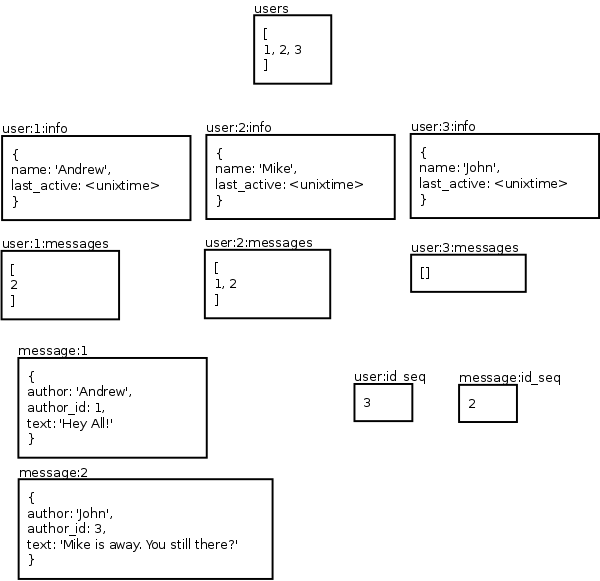
キーバリューストレージシステムのデータベース構造
これは、Andrewがメッセージを作成し、Johnがメッセージを作成した時点で、Redisのデータがどのように見えるかですが、最初はシャツ以外のすべてを読み取り、2番目はJohnだけです。 しかし、すぐにすべてのユーザー:X:メッセージが消去されます。 洗練されたタイムアウトがあり、データはクライアントに送られます。 つまり ユーザー:X:メッセージ -これは、特定のユーザーがまだ受信していないメッセージのコンテナーです。
長いポーリング
Redisは、 長いポーリングを簡単に実装できます。 アルゴリズムの例は次のとおりです。
- Redisで( LLENコマンドを使用して)クライアントのメッセージリストに現在メッセージがあるかどうかを確認します。メッセージがある場合は、メッセージを返し、 DELを介してリストをクリアします
- メッセージがない場合は再度要求しますが、今回はBLPOP コマンドを使用して、データが表示されるかタイムアウトが期限切れになるまでアクティブストリームをブロックします。 ロックを解除すると、Redisからの結果がクライアントに返されます。Redisでは、メッセージが到着したか、何も表示されません。
「バトルチーム、ゴー!」
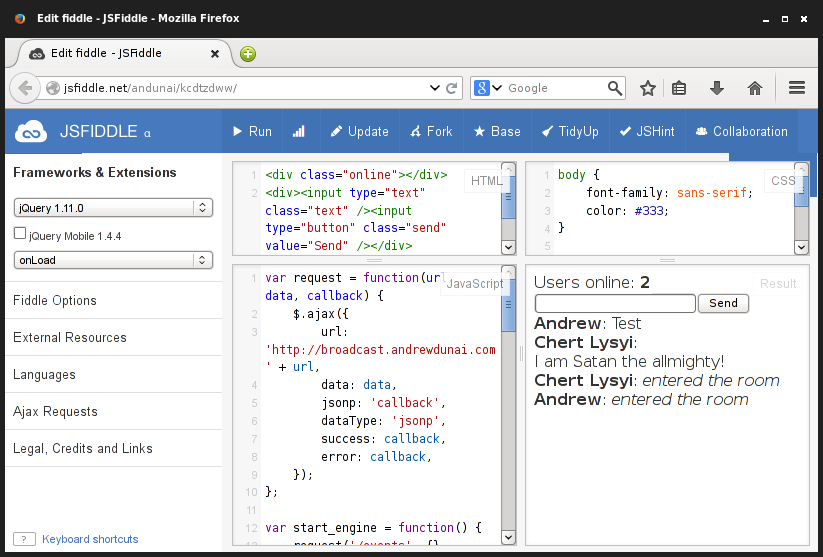
テスト用のフロントエンド: jsfiddle.net/andunai/kcdtzdww
バックエンドソースコード: bitbucket.org/AndrewDunai/nobackend-chat-dirty
フルスクリーンバージョン: jsfiddle.net/andunai/kcdtzdww/embedded/result
ポスト台本
あなたがこの場所まで読んでくれてとてもうれしいです。 いつものように、コメントや提案を歓迎します。
願わくばhabraeffectが私の小さなVPSをそれほど傷つけないことを願っています。
ご清聴ありがとうございました!
更新:リポジトリは現在公開されており、作成中に誤って非公開にされました。