
この間ずっと、私はロシア語が2つの亜種に分かれていると強く感じていました-乾式事務法務公用語と「インターネット言語」、新しく形成された単語、専門用語、重要な擬人化。 「人生はこれ以上先に進むことはできない」という絶え間ない気持ちに加えて、これが私を導き、最初にそれが呼ばれているものの正しい名前を探し、次にプログラムできる人がこれを行うことができるようになりました。
ちょっとした歴史
2011年1月18日、オバマ大統領は大統領令「EO 1356-規制と規制の見直しの改善」を新たに発布しました。 「[当社の規制システム]は、ルールがアクセス可能で、一貫性があり、 簡単な言語で記述され、容易に理解されるようにする必要がある」と述べています。
簡単な(理解可能な)言語で書かれています -これは決して一般的な用語であり、発言の順番ではありません。 これは、公式テキスト、文書、政治家のスピーチ、法律、および公式の意味に満ちたすべてのものを、単なる人間にとって理解可能な形式で翻訳するために数十年にわたって策定されたアプローチです。
明確な言語は、読者がテキストをできる限り迅速かつ完全に理解できるように設計された、明確で簡潔なスペルです。 過度の詳細、スピーチと専門用語の混乱を避けます。
英語の「プレーン」は「シンプル」を意味しますが、ロシア語では「わかりやすい」という言葉は翻訳に近いですが、「クリア」または「シンプル」な言語と言うこともできます。
英語の明確な言語- 平易な言語 、最初は英語圏の国では「平易な英語」のように聞こえた現象でしたが、すぐに国際的な現象とともに世界的な現象に発展しました。
現在、世界には数十の組織があり、言語理解のアイデアの普及に取り組んでいます。 多くの国では、法律が制定され、書籍が発行され、明確な言語での記述方法に関する政府の公式指示が発行され、最もわかりやすく理解できないテキストに対して年次賞が授与されます。
しかし、これらはすべてロシアにあるわけではありません。ロシアが世界で何をしているのかを理解するために、私たちはそれがどのように機能するかを理解しようとします。
わかりやすさとは
言語のわかりやすさに関するすべては、測定と変更という2つの用語に当てはまります。
測定は、簡単にするためのテキストの評価です(「読みやすさ」、「読みやすさ」)。 将来テキストを単純化する必要があるかどうかを理解するため、またはテキストが単純化されているかどうかを確認するために必要です。 測定例は読みやすさの公式であり、これらは学童/生徒が自分の言葉で読んだテキストをどれだけ読み返すことができるか、およびテキストが読者に理解できる程度を判断する他の方法に関する特別なテストです。
変更は、測定後の次のステップです。 これは、意味を失わずに可能な限り簡素化するために、ルール、アプローチ、および推奨事項に従ってテキストを編集しています。 変更の例は、いくつかの言葉のフレーズを自動的に置き換える特別なプログラムです。これらは複雑なテキストを正しく書き換える方法に関する指示書です。これらは「単純な言語」の辞書です。
もちろん、ほとんどすべての人がテキストの理解可能性と理解不能性を主観的に評価でき、多くの人が複雑なテキストを修正することさえできます。
しかし、私たちに近いものについてお話します。 自動化できるテキストを測定および変更する方法について。 まず、読みやすさの指標のような複雑さを測定する方法について
可読性指標
読みやすさの指標は、読みやすさとテキストの理解の複雑さを評価するために設計された数式です。 原則として、これらの式は、測定しやすいテキストメトリックを使用します。文章の数、単語の数、文字と音節の数に基づいて、テキストの複雑さまたは予想される視聴者形成の数値推定を提供します。
Flash-Kinkaidテスト(Flesch-Kinkaid可読性テスト)
このテストはもともと英語のテキストの複雑さを評価するためのルドルフフラッシュテストに基づいており、ボールは米海軍との契約の下でピーターキンカイドによって完成されました。
テストは、文中の単語が少なく、単語が短いほど、テキストが単純であるという論文に基づいています。
計算式は次のとおりです
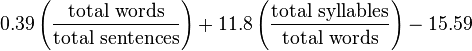
3つのパラメーターを使用します。
- 総単語数-総単語数
- 総文
- 総音節-総音節。
結果は、テキストを理解するために必要なアメリカの卒業の研究の年数です。
これは単語や文章の評価にすぎず、それらの意味ではないことに注意してください。 この式は、その後のすべての式と同様に、人生で見られる自然なテキストのために作られています。 なぜなら、あなたはいつでも誰も必要としない短い単語や文章から完全な無意味を書くことができるからです。
Coleman-Lian可読性テスト
このテストは、テキストの複雑さを簡単かつ機械的に評価するために、Meri ColemanとTL Liauによって開発されました。 Flash-Kinkaidテストや読みやすさを評価する多くの方法とは異なり、音節ではなく、文字と単語あたりの平均文字数と文あたりの平均単語数を考慮した計算式を使用します。
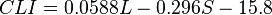
Lは100単語あたりの平均文字数です
S-100単語あたりの平均文数
SMOGテスト(SMOGグレード)
SMOGフォーミュラは1969年にハリーマクラフリンによって開発され、 SMOGグレーディング-新しい読みやすさのフォーミュラで公開されました
テキストの複雑さは、常に多くの音節を持つ単語である複雑な単語によって最も影響を受け、音節が多いほど単語が複雑になるという考えでした。
最終的なSMOGグレードの式では、3音節以上の多音節の単語の数と文の数を考慮しました。 実際、これは文章の数に対する複合語の割合の推定値です。
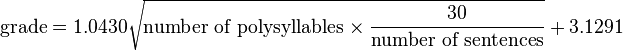
たまたま、SMOGフォーミュラが医療テキストの複雑さの評価に最も使用され、その後の研究では、Flash-Kinkaidフォーミュラと比較してより高い精度が示されました。
デール・シェールの可読性の式
この式は、1948年に763語のリストに基づいてEdgar DaleとJoan Challによって開発されました。80%の4年生のほとんどの生徒は馴染みがあり、それによって複雑な語を識別しました。 1995年には、3,000個の認識可能な単語を考慮に入れた、同じテストの更新された式が登場しました。
数式自体は非常に簡単に計算されます

ただし、評価の詳細を考慮して、主に使用され、4年生の学童のテキストをチェックするために使用されます。
自動可読性インデックス
この式は1967年に公開され、コールマン・リアウ式と同様に、文字数によるテキストの複雑さの評価に基づいて作成されました。 これにより、電気タイプライターで式を使用して、テキストの複雑さをリアルタイムで測定できました。
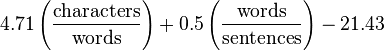
その他の式
さらに、積極的に使用されている多くの数式は、括弧の後ろに残されています。
- 稚魚の読みやすさの式
- ガニングフォグインデックス
- Spache Readability Formula
- Raygor可読性の見積もり
- リンシアライト
- レキシル
- リックス
- Flesch Reading Ease Readability Formula
- 予報
それらはすべて同様の原則に基づいて計算され、それらの多くは実際に積極的に使用されています。
ウィキペディアの基本的な読みやすさの公式の詳細: https : //en.wikipedia.org/wiki/Category : Readability_tests
ドイツ語、日本語、スウェーデン語、ポルトガル語など、さまざまな言語の読みやすさの公式がありますが、英語のようなさまざまな言語はどこでも利用できません。
実際に
- 米国社会保障局は、言語理解の要件の順守に関する特別なレポートを発行しました。特に、従業員は、テキストの評価と簡素化に役立つ特別なソフトウェアStyleWriterを使用しています。 SSA-2013プレーンライティングコンプライアンスレポート
- Oregon State Administrationは、学年10年までに発行するすべてのテキストをチェックおよび検証します-Oregon Readability
- バージニア州コードには、すべての生命保険および損害保険契約の必須の可読性要件と、Flesch-Kinkaid Virginia Codex 38.2を使用した可読性テストが含まれています。
- 州の研究を含む膨大な数の出版物は、読みやすさの公式Science.govの学年レベルの読みやすさを専門に扱っています。
ロシア語はどうですか?
ロシア語とそれに応じたロシア語のテキストは、音節、文の長さ、文字の数、多音節とみなせる単語によって英語のテキストと異なります。 特にロシア語では、単語は通常長くなりますが、文章は短くなります。 一般的なスピーチでは、多音節の単語と式の係数が異なる必要があります。
言語のわかりやすさのトピックに興味を持ち始めたとき、私はまずこのトピックに関する出版物とロシア語の実装の例を見つけようとしました。 彼らはほとんど完全に欠席していることが判明しました。 ロシアにはコンピューター言語学、特にテキストの分析に多くの強力なチームが存在するという事実にもかかわらず、実際には言語理解の分野では空虚です。
それをどうするかを決めて、私は一度に2つの方法で行くことにしました。 最初の方法は、このトピックに興味のある人を見つけることであり、もう1つは、私が理解している分野で自分で読むことです。
これが私たちの検索、NP「情報文化」、今年の毎年開催されるApps4Russiaコンテストです。私たちは一般的に理解可能性のトピックをそのテーマとして取り上げました。 そして、ロシア語の理解のしやすさは指名の一つです。 ノミネートの主な賞品は10万ルーブル、2位は5万ルーブルです。 この分野で技術プロジェクトを作成すれば、勝つことができます。 独自の式を開発し、指示を出し、読みやすさのレベル(たとえば、Webサイトでの使用条件)の調査を行い、既存の式を改善し、テキストまたは特別なWebサービスを修正または測定するためのブラウザーサービスを作成します。 多くのオプションがありますが、アイデアについて少し考えて、それを実現する以外に必要なものはありません。
しかし、2番目の方向-理解しやすい辞書と複雑な言語を書き換えるための指示を作成する前に、それが私を導きました。 そして、あなたが役人とひどいオフィスで彼らが言うことについて話す前に。 まず、ロシア語の読みやすさの公式を作成する必要があります。
係数モデリングを少しいじってみたところ、アメリカのフォーミュラはほとんどすべてが学校や大学での同時テストによって開発されたという事実に出会いました。 それらは科学的研究として作成され、科学的な記事が掲載されました。 言い換えれば、すべては科学によるものでした。 オフラインテストを実施する機会とリソースがまだないため、適切なアプローチを見つけるのに時間がかかりました。
それは、彼らが書かれた聴衆のために以前に特定されたテキストによって正しい係数を選択することにあります。 ここで最も明らかなことは、課外の読書テキストを取ることでした。 それらはすべて、通常、どのクラスを対象としているのかを正確に示しています。 例として使用した、すでによく知られている読みにくい公式テキストが追加されました。
これをテストするために、読みやすさの評価式に含まれるパラメーター間に関係があると仮定しました。 そして、特に、文中の単語が多いほど、音節内の単語が多くなるということです。
この論文はテストされ、これらのグラフが判明しました
テキストの複雑さの音節の平均数への依存
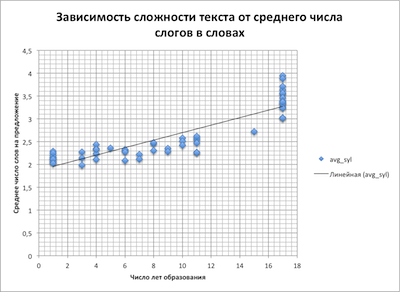
文の平均単語数に対するテキストの複雑さの依存性

単語あたりの音節の平均数の文中の単語の平均数への依存
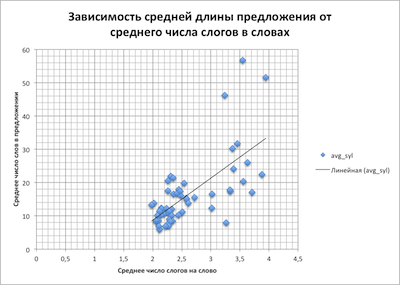
合計で、55のテキストが取得されました。
- 理解に必要な教育レベル
- 各テキストの品質指標:単語ごとの音節の平均数、文ごとの平均単語数、単語ごとの平均文字数など
さらに、タスクは式を反転し、3つの未知数と55の式でシステムを解決することでした。
式の定数は不明と見なされ、各テキストのパラメーターが取得されました。
これらの定数の選択という単純なタスクが1つだけありました。
おそらく彼女は美しい数学的な解決策を持っていたが、私は個人的に次のスキームに従って彼女の頭の上のすべてを決定した:
- 推定値の範囲は、0.0001のステップで定数に設定されました
- 定数のトリプルごとに、選択された式を使用して可読性メトリックが計算されました
- 次に、各テキストの正しい値からの偏差を計算しました
- すべてのテキストの偏差が再カウントされ、配列の平均偏差が取得されました
その結果、すべての定数オプションのうち、平均偏差が最小になるオプションが選択されました。
このすべてのモデリングと計算には数週間かかりました。 しかし、最終的に、ほぼすべてのアルゴリズムをロシア語に適合させることができました。ただし、完全な実験的検証に合格するまで、式のすべての値は任意であるという唯一の注意事項があります。
式の1つ-自動可読性インデックスの結果を表示します
定数の値は、6.26、0.2805、および31.04です。
ロシア語は文よりも短いため、単語ごとの平均文数の定数が大きくなると、単語が長くなるため、単語ごとの平均文字数の定数が小さくなります。 さらに、テキストを教育レベルに合わせるのに役立つ補正係数が選択されます。
これは、Pythonソースコードの計算結果です。
ARI_X_GRADE = 6.26 ARI_Y_GRADE = 0.2805 ARI_Z_GRADE = 31.04 def calc_ARI_index(n_letters, n_words, n_sent): """ Automated Readability Index (ARI) """ if n_words == 0 or n_sent == 0: return 0 n = ARI_X_GRADE * (float(n_letters) / n_words) + ARI_Y_GRADE * (float(n_words) / n_sent) - ARI_Z_GRADE return n
すべての数式は、オンラインサービスru.readability.ioとして実装されます。 実際、私が開発および調整し続けているすべての適応式がテストされています。 APIと、任意のテキストの可読性メトリックを取得する機能があります。
また、Githubで独自に数式を開発したいすべての人のために、テキストhttps://github.com/infoculture/plainrussian/のトレーニングサンプル全体とそれらで計算されたメトリックがあります。
シンプルだがシンプルすぎない
もちろん、読みやすさの指標はクールで便利なものですが、非常に限られています。 言語の理解に取り組む西洋の慣習では、式は100%に依存せずに慎重に使用しなければならないことが常に言及されています。 そのため、広く使用されているにもかかわらず、その開発の問題が生じます。
そして、この質問については、ここハブレで議論したいと思います。
テキストの複雑さを評価するために、他にどのようなアプローチを使用できますか?
たぶん、典型的な事務的なスピーチは変わりますか?
文の中に複雑な調和がありますか?
確かに私たちが先に進むことができる何かがあります。
* Creative Commons 2.0 Attribution、Sharealikeの下の画像
*オリジナル-secure.flickr.com/photos/visualpunch/8746310544