はじめに
最近、長くはないが、2014年5月5日にEMC 2によって顧客向けに発表されたVNXe3200データストレージシステム(SHD)が私の手に落ちました。 VNXe3200は、EMC 2の第2世代のエントリレベルの統合ストレージです。 このモデルでは、テクノロジーは以前、より高価なミッドレンジアレイでのみ利用可能でした。 特に、FastCacheテクノロジー-つまり SSDディスクの第2レベルのキャッシュ。これは、ストレージコントローラーのRAMの従来のキャッシュ(EMC用語ではストレージプロセッサー)とディスク自体のギャップにあります。 私は、このテクノロジーが最年少のEMC 2ストレージシステムのI / Oパフォーマンスにどのように影響するかをテストすることにしました。
古いEMC VNXストレージシステムとは異なり、このモデルでは、ブロックアクセスとファイルアクセスの両方が同じコントローラー(SP)に実装されます。 データベース内のストレージシステムには、各SP 4銅線ポート10Gbit / s(10GBASE-T)があり、これを介してクライアント/ホストがCIFS / SMB、NFS、およびiSCSIプロトコルを介して接続されます。 これらのポートには、1秒あたり10G / 1G / 100Mbの自動ネゴシエーションがあります。 さらに、各SPでは、4つの8Gb / s FCポートにボードを配置できます。 IOMETERを使用してテストすることにしました。 この記事は、とりわけ、Habr: linkのこの記事によって助けられました。
スタンドとテストの説明
負荷プロファイルに精通していなかったため、標準のデータベースパターン(Intel / StorageReview.com)を使用しました。
テストのために、4Gbit / sポートのビルトインFCブレードスイッチを介してFC経由でストレージシステムに接続されたBlade BL460c G7サーバー(6コア+ HTの1CPU、24GB RAM)を使用しました。 OS Windows 2012 R2は、VNXe3200からのFCブート(SANからのブート)でサーバーにインストールされました。 NTFSファイルシステムを使用したサイズが1Tbのテストボリューム(LUN)も、FCを介してサーバーに接続されました。 ストレージシステムには、内部に2つのプライベートRAIDグループ(RG)を持つ10個のディスク(SAS 2.5 "10k RPM 600Gb)のストレージプール(Raid5(4 + 1)構成)もアセンブルされます。2つのSSDディスク(2.5 「100Gb)FastCache(ミラーペアRaid1)によってアセンブルされます。
テストは3段階で実施されました。
1)IOMETERを使用して、ストレージ上のCache SPに完全に適合すると仮定して、サイズが2Gbの小さなテストファイルが作成されます。
2)以前のテストファイルが削除され、キャッシュSPに収まらないがFastCacheに完全に入ると仮定して、サイズが最大50Gbのテストファイルが作成されます。
3)以前のテストファイルが削除され、〜500Gbのサイズのテストファイルが作成されます。これは、どのキャッシュにも適合せず、100%ランダムアクセスで既存のスピンドルドライブのパフォーマンスが実際に得られると想定しています。
テストは、各パスの前に10分間の「ウォームアップ」があり、その後20分間のテストが行われるように設定されました。 各テストは、12のワーカー(6コア+ HT)のそれぞれに対してI / Oフロー(1-2-4-8-16)を指数関数的に増加させて実行されました。 同時に、実際に発行されたIOPSストレージシステムに加えて、10ミリ秒(ms)未満の快適な平均応答時間を持つことは興味深いものでした。 「写真」にVNXe3200インターフェイスからグラフを提供することをすぐに予約しますが、それらの量的指標は、リンクで提供されるIOMETER csvファイルの結果と一致します。
さらにいくつかの計算。
I / Oに対するキャッシュの影響を考慮しない場合、SAS 10kドライブの場合、EMCはドライブあたり150 IOPSを推奨します。 合計で、10個のディスクを持つバックエンドでは、150 * 10 = 1500 IOPSを取得する必要があります。 67%/ 33%のr / w負荷とRaid5でCRCを使用することの損失を考慮すると、1つの未知数で次の式が得られます。 1500 = X * 0.33 * 4 + X * 0.67、ここでXはディスクからホストを受け取るIOPSです。 4はRaid5のペナルティシュートアウトです。 つまり、Raid5では、ホストからの1つの書き込み操作を実行するには、バックエンド(ストレージドライブ)で4つのI / O操作が必要です。 Raid1 / Raid10のペナルティ値は2で、Raid6の場合は6です。その結果、X = 1500 / 1.99 =〜750 IOPSになります。 実際には、達成された最大値は計算された値の1.5〜2倍であることに気付きました。 したがって、ピーク負荷時には、10台のSASドライブから1125-1500 IOPSを取得できます。
テストとその結果に移りましょう。
テスト1
予想どおり、テストファイルはキャッシュSPにほぼ完全に適合しました。

テスト時に、IOPSについて次の図を取得し、キャッシュ内のI / O要求をヒットしました。 ここでは、このグラフがSPを通過するすべてのIOを実際に表示するように予約する必要があります。 それらの一部はSPキャッシュ(ヒット)から処理され、一部はSPキャッシュを「フライ」(ミス)し、FastCacheまたはスピンドルSASディスクから処理されます。
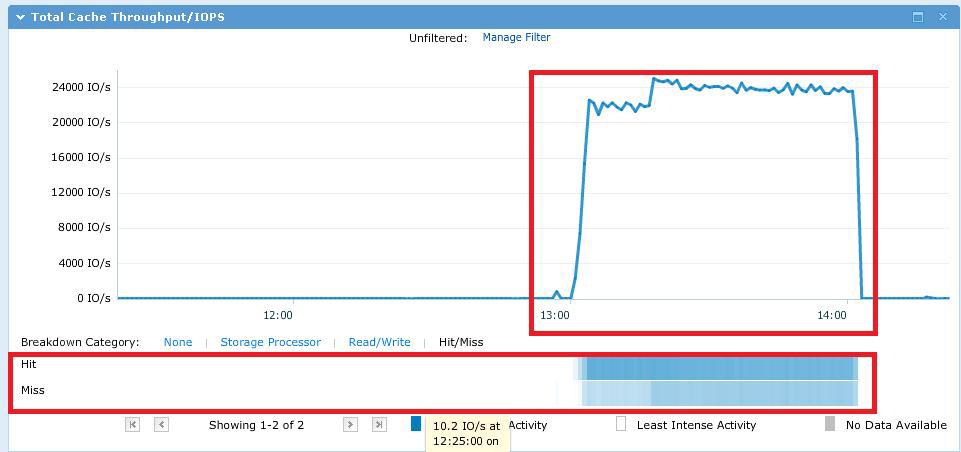
IOMETERの最大スレッド数(12ワーカー* 16スレッドIO = 192 I / Oストリーム)での平均応答時間は約8ミリ秒でした。 IOMETER結果ファイルはこちら 。 最初のテストは、ワーカーあたりのスレッド数を4から32(4-8-16-32)に増やして実施されました。 悔い改めたことに遅れて気づきましたが、やり直す時間はありませんでした。
テスト2
テスト中、〜50GBのテストファイルは、予想どおりFastCacheにほぼ完全に適合しました。
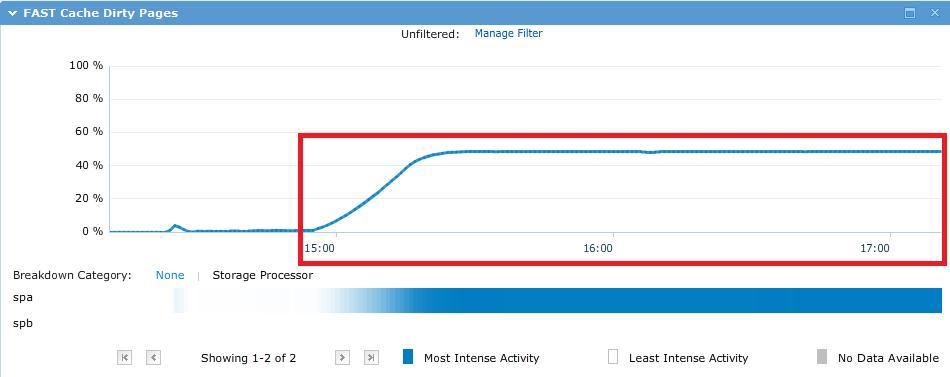
結果は次の図です。これは、ほとんどすべてのリクエストがSPキャッシュを通過することを示しています。

192スレッドの平均応答時間は約12.5ミリ秒でした。 快適な応答時間は、ワーカーの8スレッドで最大8ミリ秒(96 IOスレッド)です。 IOMETER結果ファイルはこちら 。
テスト3
テスト中に、I / Oはすべての〜500Gbでランダムに「実行」され、理論上は単一のキャッシュではなく、実際には以下のグラフから確認できます。
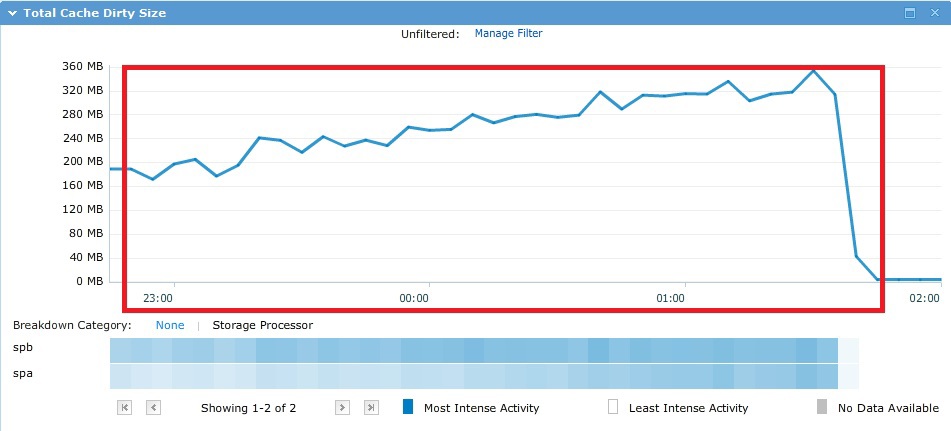
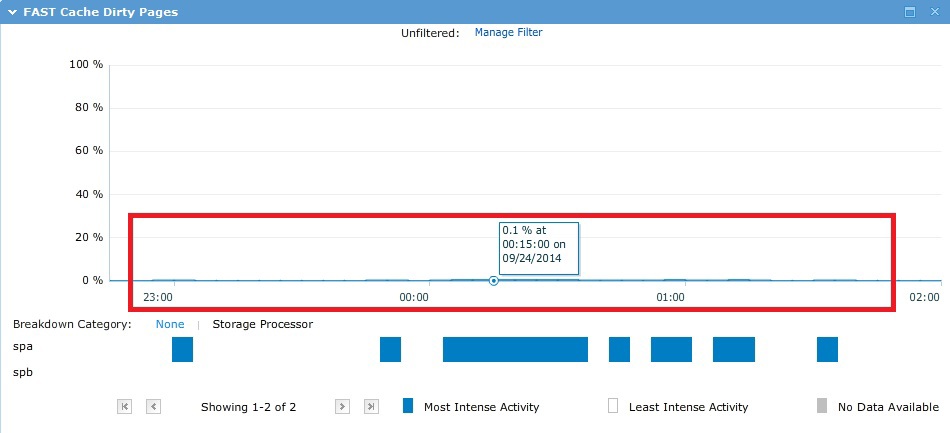
その結果、計画どおり、Raid5で10個のSASスピンドルのパフォーマンスが得られました。 この場合、プールで使用されるストレージドライブの最初の4つは、いわゆるVaultPackです。 つまり、これらの最初のドライブの一部(それぞれ約82.5 GB)は、システムのニーズに合わせて「切断」されます。
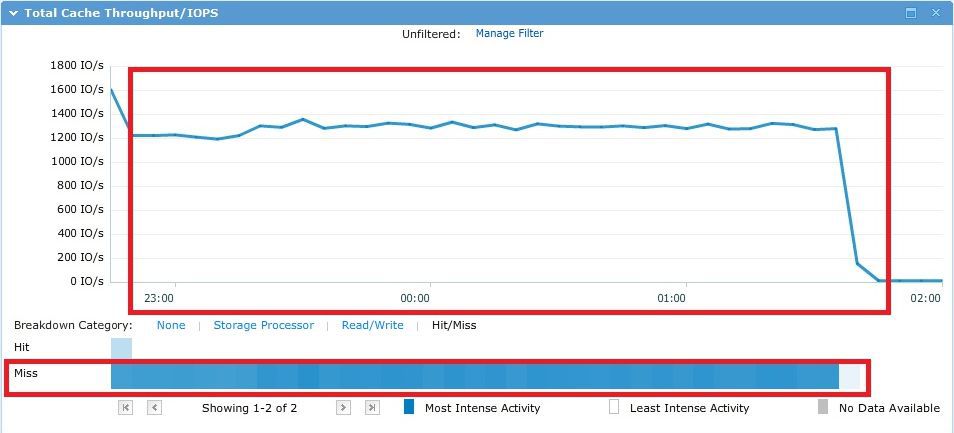
192ストリームの平均応答時間は非常に大きく、149ミリ秒に達しました。 快適な応答時間は、ワーカーあたり1スレッド(12 IOスレッド)〜10ミリ秒でした。 IOMETER結果ファイルはこちら 。
プールに関する小さな余談
ディスクプールを設計する際に、ホットデータ領域とウォームデータ領域の実際のサイズがわからない場合、EMCは、3レベルプールについて次の比率を維持することを推奨します。
10%-SSDドライブ
20%-SASドライブ
70%-NL-SASホイール
また、プールにフラッシュ層を自動的に追加すると、プールで作成された薄い衛星のすべてのメタデータがSSDに配置されることに注意してください。 それらに十分なスペースがある場合。 これにより、薄い月とプールの全体的なパフォーマンスを上げることができます。 このメタデータでは、プール上の細い衛星が実際に占有している各1Tbの3Gbボリュームに基づいて、SSDに追加のスペースを計画する必要があります。 このすべてにより、「最高の利用可能なティア」のタイルポリシーを持つ衛星は、他のデータよりもSSDダッシュに置かれたときに優先されます。
シンムーンに「利用可能な最も低いティア」ポリシーを使用すると、メタデータが最も遅いディスクに配置されます。
まとめ
テストの結果、ストレージシステム全体のすべてのタイプのキャッシュは、アレイの全体的なパフォーマンスだけでなく、プラスの効果があることがわかりました。 ただし、特に高負荷下でのI / O操作の平均応答時間についても同様です。 また、上記を考慮すると、「最もホットな」データがキャッシュに入れられるだけです。
EMC VNXe3200のFastCacheは、小規模な構成でも非常に成功した人気のある追加機能であると結論付けることができます。 その「ウォームアップ」プロセス(データがキャッシュに入る)が十分に速いことを考慮してください。