執筆の時点で、このトピックに関する技術的な部分全体を1つの投稿で説明することはほとんど不可能であり、おそらく誰も必要としないという結論に達しました。 したがって、私はこの投稿を私の作品のレビューにすることにしました。 この投稿の目的は、追加の企業融資を使用せずに、いくつかの仮想サーバーを要求することなく、大企業の大規模ネットワークのアクティブな機器を監視するための効果的な環境を構築できることを示すことです。
ネットワーク監視のトピックに興味がある場合、または私の仕事を自分のものと比較したい場合は、catに招待します。
小規模な「ホーム」ネットワークでは、ネットワークを監視するタスクは、利用可能な無料の監視プラットフォームのいずれかを使用して解決できます。 ただし、多数のノードを持つ大企業の場合、すべてがそれほど透過的ではありません。 そして主な問題は、物理リソースの不足と、要件に適合したシステムの不足です。 有料製品の場合、状況はわずかに改善されますが、有料システムが何らかの監視のためにビジネスの費用に入ることはほとんどありません。
制御システム
すべての監視のスケルトンは、マウスが新しいノードまたはリンクを変更、削除、または追加できるようにする制御システムになります。
システム全体を全体として開発する場合、次の要件が考慮されました。
- アクティブな機器の最小構成/再構成。
- netflowで大量のトラフィックを処理します。
- ネットワークアクティビティを詳細に調べる機能。
- インシデントのオンライン更新。 チャンネルのドロップか大きなチャンネル負荷か。
- 可能なすべてのサンプルのモジュールまたはレポートを変更する機能。
- 最小限のインフラストラクチャを含める。
- 自分で機能を記述することは可能な限り少なくします。
インフラストラクチャは、現在の構成に達するまで別の方法で試行されました。 投稿を伸ばさないために、試したすべてのオプションについては説明しません。
一番下の行は、CentOS 6を実行する2つの仮想サーバーです。
制御および表示システム用。 2プロセッサ、4GB RAM、250GBドライブ。
2番目はnetflowコレクターです。 2プロセッサー、4GB RAM 150GBドライブ。
サーバー設定は非常に標準的なphp + mysqlを 使用したApache Webサーバーです。
サボテン
制御システムには、 Cactusが選択されました。 サボテンを魅了したもの:
- WEBディスプレイに複雑なコードがない(フラッシュ、aciveXおよびその他のアクティブなコンポーネントがないため、モバイルデバイスで使用する利点があります)。
- シンプルで明確なデータベース構造。独自の機能を簡単にバインドできます。
- 特にアクティブな機器を監視するための多くのプラグイン。
- 組み込みSNMPサポート。
- チャートのソースとしてのRRDTool (hello zabbiksu);
- クライアント部分はありません。
Cactusのインストールは簡単です。 このトピックに関する情報はインターネット上にたくさんありますが、もちろん、公式ドキュメントが最適です。
また、セットアップには詳細なIT知識は必要ありません。 [デバイス]ページで、デバイスが追加され、SNMPの種類と承認が示されます。 標準テンプレートがバインドされています。
装置 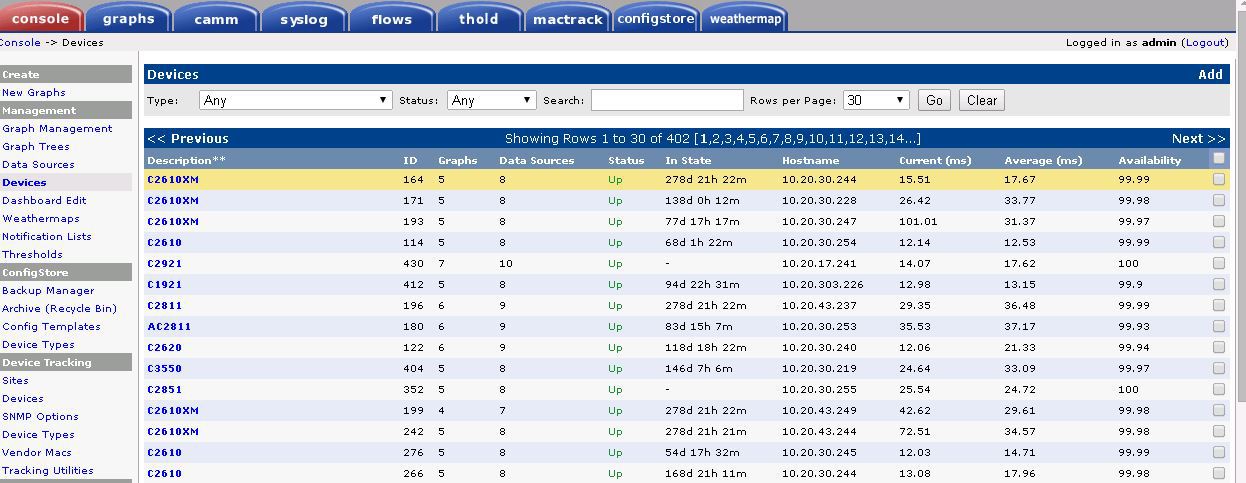
SNMPセットアップ 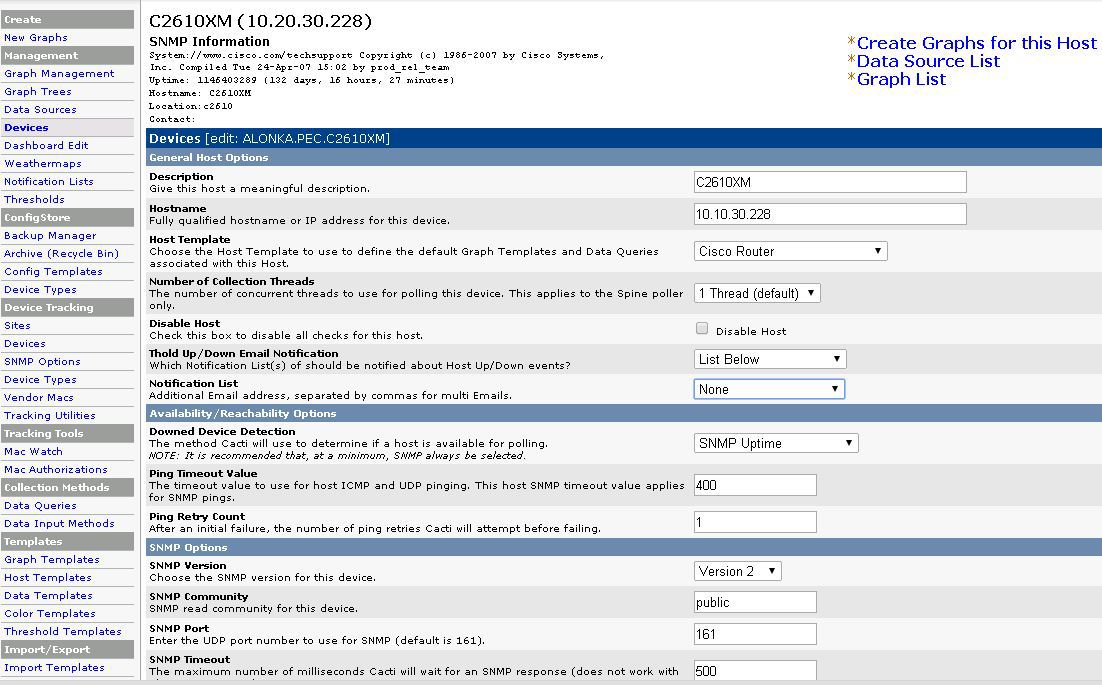
パターン 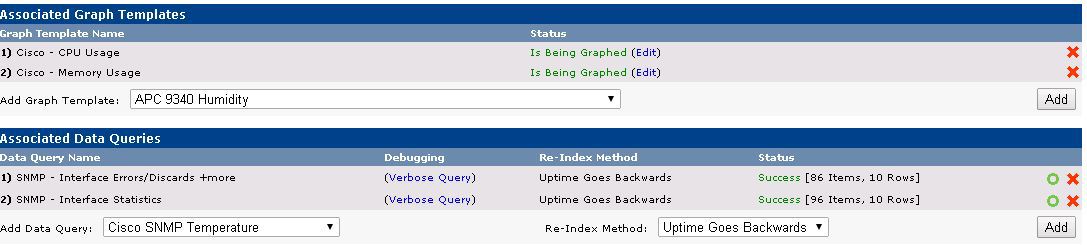
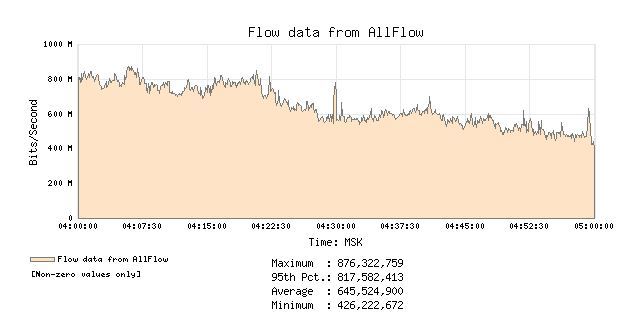
サボテンでデバイスをポーリングした後、特定のネットワークインターフェイスまたは他のセンサーからのSNMPのデータに基づいて、IPBのネットワークの電圧またはスイッチのプロセッサ負荷に関係なく、グラフを作成することが可能になります。
選択チャート 
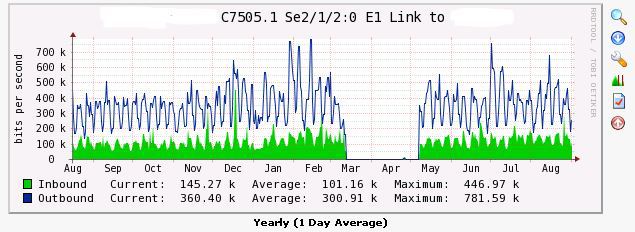
アクティブな機器を操作するためのCactusプラグイン
ネットフロー
主なアイデアは、netflowストリームに基づくレポートです。 したがって、必要な最初のflowviewプラグインです。 フローソースをグラフィカルに構成できる非常にシンプルなプラグイン。
フロービュー設定 
また、フローストリームに基づいて選択を行い、スケジュールに従って自動レポートを作成します。
フロービュースケジュール 
syslogおよびトラップ
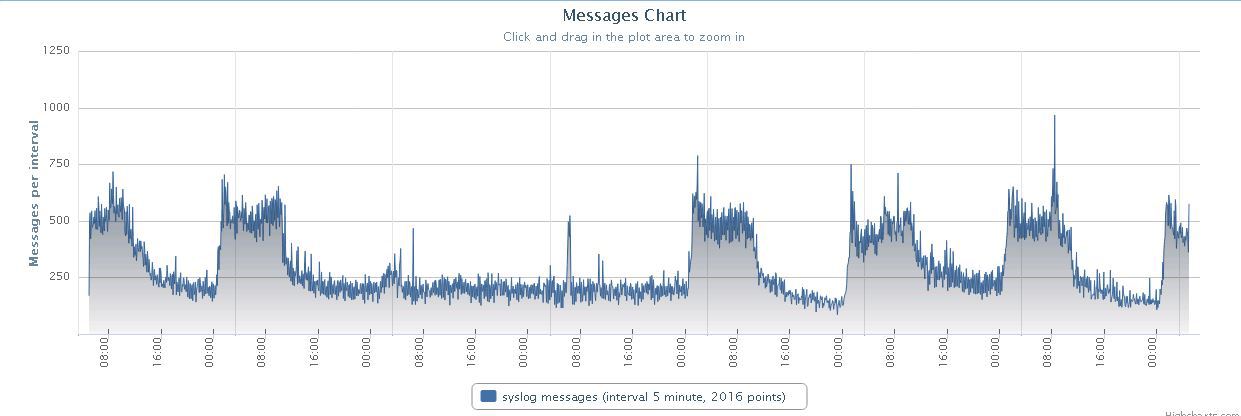
2つのプラグインを使用して、Ciscoでトラップとsyslogを収集および分析しました。
これはcammとsyslogです。
カム 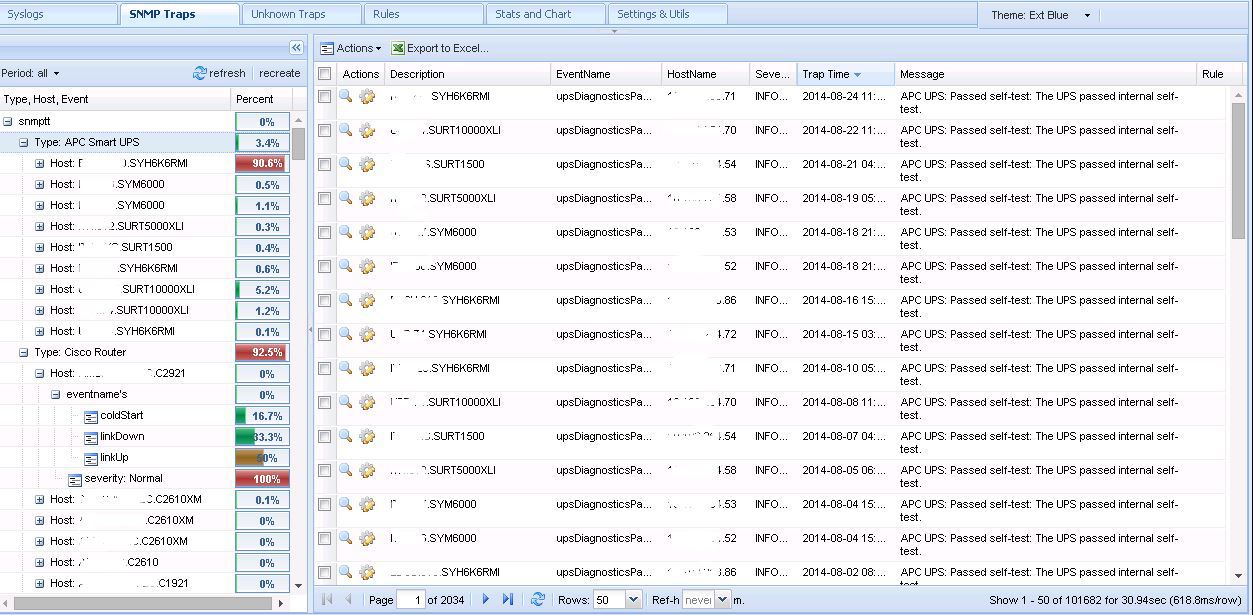
最初のものは、フィルターとイベントのルールを作成する機能に感銘を受けました(たとえば、企業のジャバーで企業のイベントに関するメッセージを受け取りました)。
カムルール 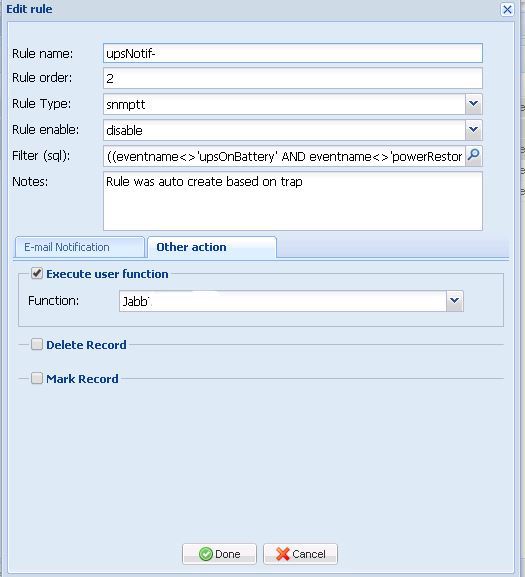
また、MIBとサボテンデータベース自体に基づいた非常に便利なグループ化です。
カムグループ 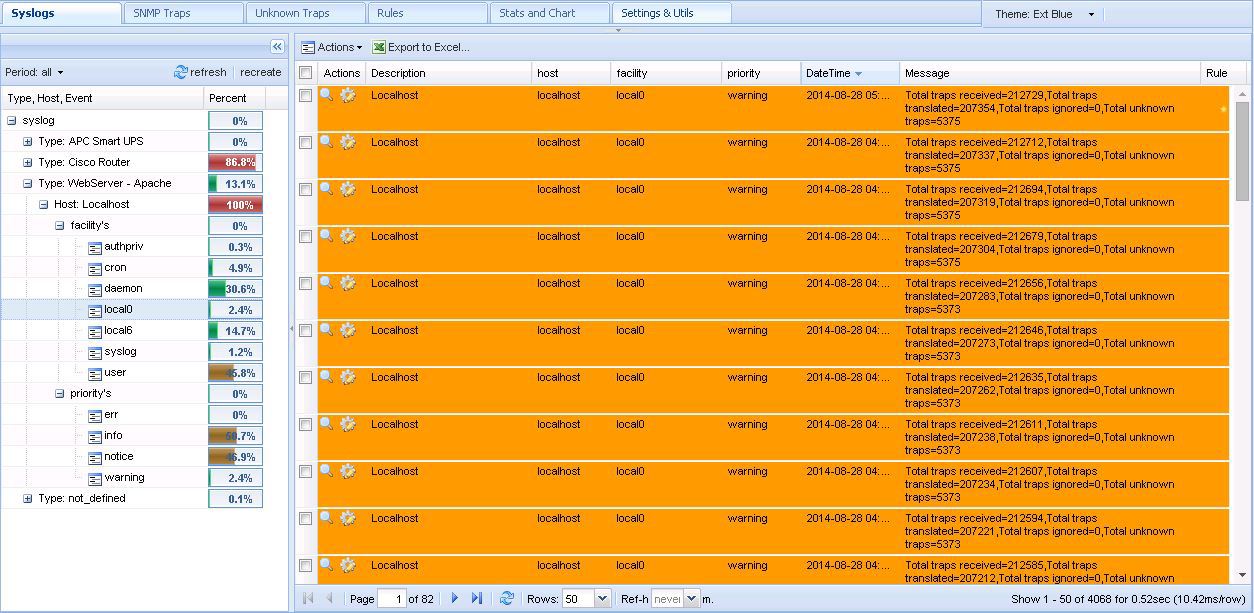
2つ目は、非常に透過的な構造を持つ自律型データベースを作成します。この構造に、独立して記述された機能を添付しましたが、後で詳しく説明します。
ネットワークマップ
Weathermapは、ネットワークの監視に使用する最後のプラグインです。 彼は美しく、シンプルです。 データはサボテン自体のRRDデータベースから取得され、エディターはペイントに似ています。
チャンネル 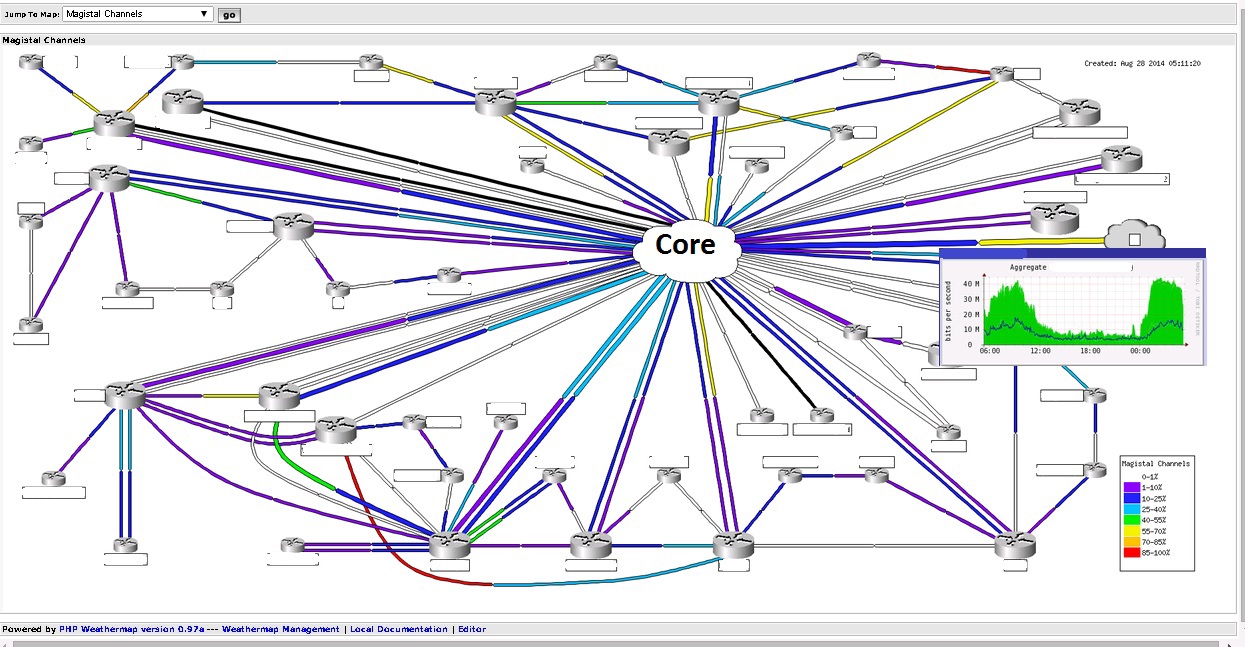
通信チャネルの負荷をグラフィカルに表示できます。 チャンネルで起こりうる問題も同様です。
ウェザーマップ構成ファイルの一部。
ウェザーマップの設定例
NODE C7606.1 LABEL C7606.1 LABELOFFSET N INFOURL /cacti/graph.php?rra_id=all&local_graph_id=3691 OVERLIBGRAPH /cacti/graph_image.php?rra_id=0&graph_nolegend=true&graph_height=100&graph_width=300&local_graph_id=3691 ICON images/Router_PU2.png POSITION 1132 180 NODE C7609#1 LABEL C7609#1 LABELOFFSET N INFOURL /cacti/graph.php?rra_id=all&local_graph_id=3366 OVERLIBGRAPH /cacti/graph_image.php?rra_id=0&graph_nolegend=true&graph_height=100&graph_width=300&local_graph_id=3366 ICON images/Router_PU2.png POSITION 795 180 # regular LINKs: LINK C7606.1-C7609#1 INFOURL /cacti/graph.php?rra_id=all&local_graph_id=347 OVERLIBGRAPH /cacti/graph_image.php?local_graph_id=347&rra_id=0&graph_nolegend=true&graph_height=100&graph_width=300 TARGET /var/www/cacti/rra/c7606_1_traffic_in_403.rrd NODES C7606.1:N20 C7609#1:N50 BANDWIDTH 40M LINK C7606.2-C7609#2 INFOURL /cacti/graph.php?rra_id=all&local_graph_id=340 OVERLIBGRAPH /cacti/graph_image.php?local_graph_id=340&rra_id=0&graph_nolegend=true&graph_height=100&graph_width=300 TARGET /var/www/cacti/rra/c7606_1_traffic_in_396.rrd NODES C7606.1:N10 C7609#1:N50 BANDWIDTH 40M
NetFlowセットアップ
Flow-toolsは、ソフトウェアコレクターとして使用されます。 このソフトウェアは、トラフィックをキャプチャするだけでなく、分析することもできます。 また、このパッケージに基づいて、収集された情報を人間の形で表示するためのGUIが多数作成されています。
flow-captureコンポーネントをflowview cactus プラグインから管理するつもりだったので、 flow-toolsをインストールした後、プラグインフォルダーからサーバー上のinit.dにサービス起動スクリプトをコピーする必要があります。
制御システムに関するこの大騒ぎは何ですか? 結局のところ、構成を手動で修正してスコアリングする方が簡単ですか? しかし、そこにはありませんでした。 デバイスの数は約500個で、非常に大量のトラフィックがあります。 すべてのフローを1つのフォルダーに追加すると、1時間のトラフィックのデータの抽出に2時間以上かかるため、これは受け入れられません。
選択が必要なトラフィックを持つ特定のフォルダーで行われるように、各デバイスからのストリームを個別のフォルダーに分離することが決定されました。 フローキャプチャにより、これはデバイスからポートへのストリームの間隔を空けて行われます。 これは、各デバイスに一意のフローリターンポートを設定する必要があるということですか?
したがって、この問題を解決するのに役立つ単純な小さなプログラムsamplicatorも受け入れられません。 作業の本質はこれです。着信UDPパケットを受信し、送信元アドレスでソートし、選択したポートに変換します。 これは、1つのポートに対して標準の機器セットアップを行い、サーバー自体で既にポート間でフローを分散することを意味します。
構成構文:ソース/マスク:Destination1 /ポート[Destination2 /ポート]および例:
samplicate.conf
10.20.0.0/255.255.0.0:07/2056
10.20.30.252/255.255.255.252:10.20.0.108/2057 0/2057
10.20.30.4/255.255.255.252:10.20.0.108/2058 0/2058
10.20.30.160/255.255.255.255:10.20.0.108/2059 0/2059
10.20.30.252/255.255.255.252:10.20.0.108/2057 0/2057
10.20.30.4/255.255.255.252:10.20.0.108/2058 0/2058
10.20.30.160/255.255.255.255:10.20.0.108/2059 0/2059
フローが収集され、恐怖でディスクの充填速度が監視されます。 これをすべて表示するにはどうすればよいですか?
同じflow-toolsパッケージを使用して手動でレポートを生成する方法は多数あります。 しかし、システムのすべてのユーザーがこれを行うことができるわけではなく、できる人なら誰でも汗をかいて人間のレポートを書く必要があります。
別のすばらしいFlowViewerプロジェクトに目を向けました。
掘り下げて使い始めたとき、バージョン3.3または2006年のようなものがありました。 私は第3バージョンで考え出したが、プロジェクトは思いがけず生き返り、開発を開始したが、第4バージョンは第3バージョンに比べて素晴らしかった。 執筆時点では、現在のバージョンは4.4です(4.1を使用しています)。
基本的に 、 Flowview Cactusプラグインをほぼ完全に複製しますが、使用可能なスケジュールがあるプラグインのみが好きで、選択作業が不安定で、フィルターが完全ではなく、必要な集約がありません。 また、アーキテクチャ上、フロー全体が2番目のサーバーに保存されます。つまり、 FlowVieverは 2番目のサーバーに喜んで配置し、トラフィックのある美しいグラフと選択を提供します。
フロービューア 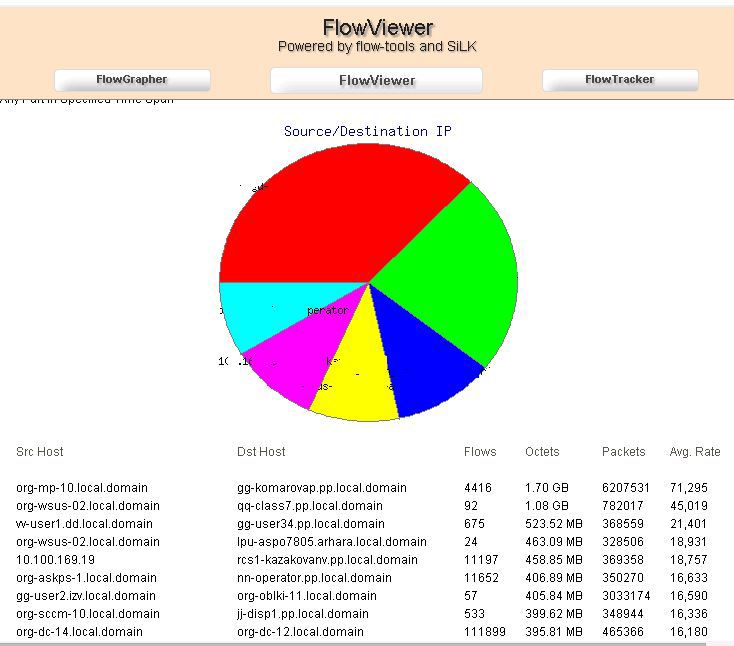
SNMPトラップ
流れのあるストリームは非常に優れており魅力的ですが、それらを使用して問題を報告することは不可能です。 問題を修正した後の分析のみ。
さて、最も手頃な価格のアラート方法はSNMPトラップです。 1つのリストで500台のデバイスからSNMPトラップを取得するのはあまり快適ではありません。ごみの中で重要な情報が失われます。 何らかのフィルターを実行する必要があることは明らかです。 私の要件を満たす既製のソリューションはありませんでした。 しかし、私はラダーアナライザーを自分で書くことにした研究所でのプログラミングへの渇望を思い出して、それは重要ではありません。
フィルタリングされたリストを取得する技術は次のとおりです。ラダーを受信すると、監視サーバーはそれを受信( snmptrapd )し、ロードされたMIB仕様に従って分析( snmptt )し、すぐにデータベースに入れます。
snmptt.conf
mysql_dbi_enable = 1
mysql_dbi_host = localhost
mysql_dbi_port = 3306
mysql_dbi_database = cacti
mysql_dbi_table = plugin_camm_snmptt
mysql_dbi_table_unknown = plugin_camm_snmptt_unk
mysql_dbi_table_statistics = plugin_camm_snmptt_stat
mysql_dbi_username = cacti
mysql_dbi_password = cacti
mysql_ping_on_insert = 1
mysql_ping_interval = 300
mysql_dbi_host = localhost
mysql_dbi_port = 3306
mysql_dbi_database = cacti
mysql_dbi_table = plugin_camm_snmptt
mysql_dbi_table_unknown = plugin_camm_snmptt_unk
mysql_dbi_table_statistics = plugin_camm_snmptt_stat
mysql_dbi_username = cacti
mysql_dbi_password = cacti
mysql_ping_on_insert = 1
mysql_ping_interval = 300
何らかの方法で独自のイベントスタックを開始する必要があるため、この処理をインターセプトすることは意味がありません。 ラダーが入るデータベースには、デバイスに関する情報(名前、ポート、リンク)がいっぱいになり、 CactusはSNMPポーリングを使用してそれ自体を収集します。
ベースからイベントを取得するオプションは魅力的で、情報コンテンツの既存のベースにリンクします。 ノートで武装して、彼は論理を発明し始めました。 これには特別な問題はありませんでした。データベースからデータを取得するときに問題が発生しました。 これは30秒からかかり始めました。 ここでは効率については話していませんでした。 データベースの最適化、クエリの最適化、インデックス、計画、私の仲間(超大規模データベースの専門家)の賢いヒントの理論が彼らの仕事をしました。

主なアイデアは、インターフェイス名(Eth、Serial、Gi、E)が記述されているUp / Downラダーを、SNMPを使用してテーブル内のデータを探す識別子とソースでフィルタリングすることです。 出力は、リンクが落ちた場所 、 場所 、 場所を示す美しい行です。
MySQL Select:チャンネルステータス
Select MAX(sd.id), sd.id_channel, sd.`status`, sd.diff, MAX(sd.date) as 'date', MIN(sd.date2) as 'date2', SUM(UNIX_TIMESTAMP(sd.date)-UNIX_TIMESTAMP(sd.date2)) as 'time', MAX(sd.id_trap) as 'id_trap', `host`.description, channel_list.ch_name from ( SELECT a.id, a.id_channel, a.`status`, UNIX_TIMESTAMP(NOW())-UNIX_TIMESTAMP(a.date) as 'diff', a.date, (select CASE cs2.`status` WHEN a.`status` THEN null ELSE cs2.`date` END from custom_status AS cs2 where cs2.id_channel = a.id_channel and cs2.date = (select MAX(cs.date) from custom_status cs where cs.date < a.date and cs.id_channel = a.id_channel ) LIMIT 1 ) as 'date2', a.id_trap FROM custom_status AS a JOIN (SELECT t.id_channel, MAX(t.date) AS max_date FROM custom_status t GROUP BY t.id_channel) AS b ON b.id_channel= a.id_channel) sd INNER JOIN channel_list ON channel_list.id = sd.id_channel INNER JOIN `host` ON channel_list.hostname = `host`.hostname where sd.`status` = 'linkUp' AND sd.date between DATE_SUB(CURDATE(),INTERVAL MOD(DAYOFWEEK(CURDATE())-2,7)+7 DAY) AND DATE_ADD(CURDATE(), INTERVAL MOD(7 - (DAYOFWEEK(CURDATE()) - 1), 7)-6 DAY) GROUP BY sd.id_channel,sd.`status` ORDER BY date desc"
データベースからのすべてのデータは、htmlページの形式で読み取り可能な形式で作成されます。
トラップからの情報 
異なる条件を受け取るデータベースからのサンプルは、異なるレポートラベルを形成します。
詳細情報 
面倒なナレーションすべてをマスターした読者に感謝します。 これは、システムが1年以上もの間、私なしで機能していることもあります。 私は多くを忘れました、何かがその意味を失いました。 しかし、監視はまだ機能し、データを収集し、私のサポートなしで既にサンプルを提供しています。
すべてのデータ、スクリーンショット、および構成は非個人化されます。 偶然は偶然です。