
こんにちは、harazhiteli!
ニュースレターのSMSサービスの比較についてここで読んだ後、このようなシステムを構築した経験についてお話しすることにしました。このシステムは数年間忠実に役立っており、絶えず改善されています。 私たちの経験があなたに役立つことを願っています。 一般的に、興味がある人のために、猫をお願いします。
SMSメールシステムとは何ですか?
SMSDirectシステムの主なタスクは、単一のSMSメッセージを送信または送信することです。
フロントエンド
サービスは全体が複雑で、氷山の一角がクライアント部分であるサイトです。 これは、システムへのエントリポイントです。 個人用アカウント(メーリングリストを手動でダウンロードする場合)と、メーリングを作成してメッセージを送信するためのAPIメソッドのセットがあります。
システムに入るには、クライアントが登録してから、APIメソッドのセットまたは個人アカウントのインターフェースを使用する必要があります。 ここでは、ユーザークライアントデータベース(サブスクライバーリスト)の読み込みと保存、およびこれらのリスト(または手動で入力した番号)のメーリングリストの作成と管理の機能が実装されています。
バックエンド
コンポーネントシステム:大量の同じタイプのデータを処理し、それらからメールを生成できるソリューションと、システムをオペレーターと接続する信頼性の高いメカニズム。 ここでの主要なタスクは、膨大な量のユーザーデータベース、それらの迅速な処理、およびそれらへのアクセスを保存することです。
ルーティング
保有するデータの量は非常に多いため、処理、分割、ルーティングの方法を決定する必要がありました。
データ全体をいくつかの内部接続に分割した後、各メッセージが必要なゲートウェイに確実に届くようにする必要がありました。 したがって、メッセージはオペレーター間で特定の方法で配信する必要があります。 このような配信はルーティングコンプレックスで実行されます。ルーティングコンプレックスは、特定のゲートウェイを介して数百万のメッセージを送信するアプリケーションシステムです。 分割は、メッセージ属性の分析に基づいて実行されます:サブスクライバーは特定のオペレーター(コードだけでなく、サービスオペレーターによって)に属し、メッセージテキスト、送信者番号、つまりメッセージプロパティは完全な分析と処理の対象となります。 したがって、メッセージ配信の問題を解決します。1つの配信があり、メッセージは配信され、オペレーター(サブスクライバー番号)および送信者の数などに応じて異なる方法で配信されます。 いくつかの専用サーバーがトラフィックルーティングに関与し、UIおよびバックエンドの外部のインフラストラクチャの一部を表します。
インテリア建築
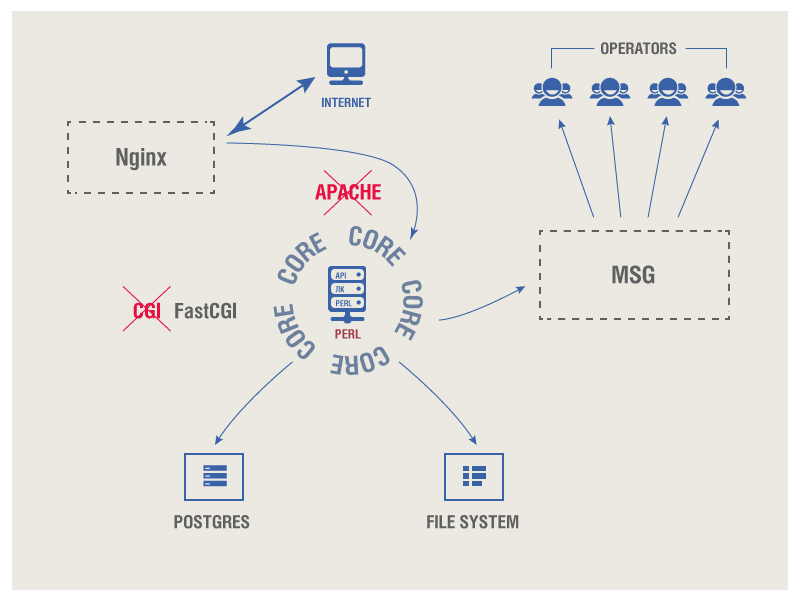
Nginxは、UIへのユーザー呼び出しとAPIリクエストを処理するWebサーバーとして機能します。
このソリューションは古典的であり、そのようなタスクにはほぼ普遍的です。 下位レベルでは、Apache Webサーバーを展開することは論理的ですが、それを使用しないことでリソースを節約することを決定し(すべての機能が必要ではなく、必要な機能の1%に全額を支払うのは不適切です)、独自のPerlコアを作成しました。 これが実際にシステムの基礎となっているものです。
なぜPerlなのか?
簡単な答え:
長い答え:これはハリウッドの質問です。実際、特定の言語を使用する特別な理由はありません。 大規模で複雑なプロジェクトの重要な問題は、言語ではなく、適切に設計されたアーキテクチャです。 さまざまな言語を知っていて愛するスペシャリストがいるので、このプロジェクトを開発するときに、Perlを知っている専門家が熱意を示したように話が判明しました:)同時に、Perlが最終的に選ばれたので、この言語の利点、特に間違いなく、CPAN(読み取り-任意のタスクの既製のソリューション)と言語の成熟度(読み取り-更新中のコードの保証されたパフォーマンス(ここで、ピンはPHPに対応しています))があります。
コア
カーネルは、FastCGIインターフェースを介してWebサーバーと対話します。FastCGIインターフェースは、まずnginxを受け取ってリクエストをカーネルに転送する役割を果たします。常に実行されているカーネルがあります。
コア自体はいくつかの別個の「デーモン」に分割され、それぞれがプロセスの一部を担当します。 それらの最も基本的なものは、個人アカウント、APIのセット、ユーザーからのファイルのダウンロードを担当する機能(サブスクライバーベース)を備えたサイトです。また、外部データと対話せず、内部(サービス)プロセスのみに焦点を当てたサービスパーツがカーネルで提供されます。 それ自体では、この部分はいくつかの低レベル関数に分割されます。 たとえば、ユーザーがサブスクライバーデータベースをダウンロードした場合、システムは最初にそれを、作業に適さないデータを含む単なるファイルと見なします。 ファイルがダウンロードされた後、処理されます-サブスクライバー番号の正しい長さとプレフィックスがチェックされ、空で短すぎる番号は破棄されます。つまり、「生の」ファイルはサブスクライバー番号、ID、リージョン識別子、およびその他のサービスパラメーターを含む標準内部構造に変換されます。
データベース
ユーザーが読み込んだデータベースはディスクに保存され、ファイルシステムにありますが、サービススクリプトが実行された後、必要な説明情報がデータベースから抽出され、データベースに保存されます。 この情報は構造化されており、各属性のフィルターを使用してクエリを作成できます。
データベースを処理し、データベースから必要なエンティティを抽出するとき、または取得した統計を処理するとき、ソートには膨大な量がかかります。 従来のソーターは、このようなボリュームとソートの複雑さにはほとんど役に立たないため、これにはMSORTを使用します。
ファイルシステム
ユーザーは大きなサブスクリプションリストをアップロードするため、どこかに保存する必要があります。さらに、各ニュースレターは、独自のサービスデータを大量に生成します。ニュースレターで生成されたメッセージのブロック、これらのブロックで受信したステータス、およびエクスポート用の最終ファイルです。 配布が終了すると、中間ファイルは削除されます。 たとえば、1,000万のメッセージを送信すると、それぞれに3〜5個の信号が送信されます。これは、ファイル内の既に3,000〜5,000万件のレコードです。 一般に、クライアントはいつでも詳細を把握する必要があるかもしれないので、失うべきではない数十億のレコードを生成します。 これを行うには、個別のファイルストレージをカーネルに接続します。
場合によっては、特定のファイルで特定のレコードを見つける必要があります。それは、数値のデータベースやその他の統計情報です。 最初から最後まで徹底的に検索することでそれを読むのは長くて費用がかかるため、多くのプロセスで忘れられている多くのツール-Berkeley DB(BDB)を使用しています。 これはディスク上のハッシュの一種で、ファイル内のオフセットを示す特定の識別子が含まれており、そこから必要な情報を読み取る必要があります。
オペレーターへの情報のルーティングと配信
カーネルは、オペレーターにメッセージを送信する内部ルーティングシステムと対話します。 この部分はi-Freeによって開発され、会社のインフラストラクチャによってサポートされています。
私たちはオペレータに接続し、ネイティブツールを使用してメッセージ(SMSメッセージ)を送信します。 原則として、これはSMPPであり、オペレーターがサプライヤーに割り当てます。