実装言語としてBrainfuckを使用してください。 実装は簡単です。これはこのトピックを調査するのに最適ですが、最初に実装を紹介します。
JBrainfuckは、Java VM用の最適化Brainfuckインタープリターおよびコンパイラーです。 JITのおかげで、高いパフォーマンスが得られます。
- ライセンス:MIT
- プロジェクトのアドレス: https : //github.com/SystemX-Files/jbrainfuck/
- プラットフォーム:Linux、Windows、MacOS、およびJavaがどこにいても。
開発ツールの選択
明らかな解決策は、Javaでコンパイラーを作成することです。
バイトコードを生成するには、 ASMライブラリを使用します。 Groovy、JRubyなどの一般的な言語で使用されます。
JVMバイトコードを簡単に監視するには、IDEにプラグインをインストールします。
作成を開始
私たちが実装しているBrainfuck言語を知っている人は多いと思います。 それはたった8つの単純なコマンドで構成されていますが、それでもチューリングは完全であり、OS(
その本質はシンプルです。 左右に移動したり、セルの値を増減することでセルの値を変更できるメモリテープがあります。
これらのコマンドのリストは次のとおりです。
| Brainfuckチーム | 同等のJava | 説明 |
|---|---|---|
| 開始する
プログラム | | テープにメモリを割り当てます
真ん中に位置を置きます |
<
|
| 左にスキップ |
>
|
| 右にスキップ |
| + |
| 現在のセルに1を追加 |
| - |
| 現在のセルから1を引く |
| 。 |
| 現在のセル値を印刷 |
| 、 | | 現在のセルの値を入力してください |
| [ | | 値がゼロ以外になるまでサイクルで作業します |
| ] |
| サイクルの先頭に移動します |
コード
++++++++[>+>++>+++>++++>+++++>++++++>+++++++>++++++++> +++++++++>++++++++++>+++++++++++>++++++++++++>++++++++ +++++>++++++++++++++>+++++++++++++++>++++++++++++++++< <<<<<<<<<<<<<<<-]>>>>>>>>>.<<<<<<<<<>>>>>>>>>>>>>---.+ ++<<<<<<<<<<<<<>>>>>>>>>>>>>>----.++++<<<<<<<<<<<<<<>> >>>>>>>>>>>>----.++++<<<<<<<<<<<<<<>>>>>>>>>>>>>>-.+<< <<<<<<<<<<<<>>>>>>----.++++<<<<<<>>>>.<<<<>>>>>>>>>.<< <<<<<<<>>>>>>>>>>>>+.-<<<<<<<<<<<<>>>>>>>>>>>>++.--<<< <<<<<<<<<>>>>>>>>>>>>>>++.--<<<<<<<<<<<<<<>>>>+.-<<<<.
コンパイラを書く
すべての規則に従ってコンパイラーを作成するため、コンパイラーには、字句解析、最適化、バイトコード生成の3つのコンパイル段階があります。
まず、可能な最適化を検討する価値があります。これにより、コンパイラの設計がより便利であることがわかります。
最適化
おそらく最初に目を引くのは、同じ種類の操作です。 もちろん、すべてを圧縮し、一連の操作を
#~
の形式に減らすという考えがすぐに生まれます。ここで、 #は操作の数で、 〜は操作です。
また、
[-]
または
[+]
という形式のコードはセルのゼロ化であるため、このために別の操作を選択することは理にかなっています。
演算の数を減らすという考えをさらに進めると、加算/減算演算は同等であり、数の符号のみが異なることが理解できます。 したがって、それらを1つの操作に導くことができます。 同じことが左/右に移動する操作にも有効です。
すべての最適化の後、新しい操作テーブルを作成します。 そのすぐ下でコンパイラーを実行します。
| 運営 | Javaアナログ | 説明 |
|---|---|---|
| SHIFT(引数) |
| テープシフト |
| ADD(引数) |
| 加算(負の数による減算) |
| ゼロ | | ゼロ調整 |
| OUT(引数) | | セル引数時間を印刷 |
| IN(引数) | | セル引数時間を入力してください |
| ながら | | |
| 終了 |
|
操作と繰り返し回数を保存するクラスを作成します。
コード
public class Opcode{ public enum Type{ SHIFT, ADD, ZERO, OUT, IN, WHILE, END } public Type type = null; // public int arg = 1; //- public Opcode(Type type, int arg) { this.type = type; this.arg = arg; } public Opcode(Type type) { this.type = type; } public Opcode clone(){ return new Opcode(type, arg); } }
字句解析器
Brainfuckコードで発生する可能性のあるトークンを強調表示します。
| トークン | 運営 |
|---|---|
<
| -でシフト |
>
| SHIFT + |
+
| +追加 |
-
| -で追加 |
.
| アウト |
,
| で |
[
| ながら |
]
| 終了 |
[-]
または [+]
| ゼロ |
そして、これらのトークンのシーケンスを選択するアナライザーを作成します。
コード
public abstract class Tokenizer{ public static List<Opcode> tokenize(String code) { // ( ) List<Opcode> retValue = new ArrayList<Opcode>(); int pos = 0; // while (pos < code.length()) { switch (code.charAt(pos++)) { // , case '>': retValue.add(new Opcode(Opcode.Type.SHIFT, +1)); break; case '<': retValue.add(new Opcode(Opcode.Type.SHIFT, -1)); break; case '+': retValue.add(new Opcode(Opcode.Type.ADD, +1)); break; case '-': retValue.add(new Opcode(Opcode.Type.ADD, -1)); break; case '.': retValue.add(new Opcode(Opcode.Type.OUT)); break; case ',': retValue.add(new Opcode(Opcode.Type.IN)); break; case '[': char next = code.charAt(pos); //, ([+] [-]) if((next == '+' || next == '-') && code.charAt(pos + 1) == ']') { retValue.add(new Opcode(Opcode.Type.ZERO)); pos += 2; } else retValue.add(new Opcode(Opcode.Type.WHILE)); break; case ']': retValue.add(new Opcode(Opcode.Type.END)); break; } } return retValue; } }
オプティマイザー
ここでのタスクは、繰り返し操作を圧縮し、不要な操作(たとえば、連続する複数のZEROコマンド)を削除することです。
すべてが比較的簡単に行われます。
コード
public abstract class Optimizer { public static List<Opcode> optimize(String code) { return optimize(Tokenizer.tokenize(code)); } public static List<Opcode> optimize(List<Opcode> tokens) { Stack<Opcode> retValue = new Stack<Opcode>(); // for (Opcode token : tokens) { switch (token.type){ case SHIFT: case ADD: case OUT: case IN: case ZERO: // , if(retValue.size() == 0) { retValue.push(token.clone()); continue; } // , if(retValue.peek().type != token.type) { if(retValue.peek().arg == 0) // "" retValue.pop(); // if(retValue.peek().type == Opcode.Type.ZERO) // ZERO retValue.peek().arg = 1; // , retValue.push(token.clone()); // continue; } // , // retValue.peek().arg += token.arg; break; case WHILE: case END: // retValue.add(token.clone()); break; } } return retValue; } }
バイトコードジェネレーター
最も困難で興味深い部分、つまりJava VMのバイトコードの生成に移ります。 バイトコードの生成方法を理解するために、 以前にインストールされたIDE用のプラグインが役立ちます。 始めましょう。
最初に、テープにメモリを割り当て、位置を設定する必要があります。 パラメータなしのメソッドでクラスを作成し、その中の位置の配列と変数を宣言するだけです。
// public void test() { char[] arr = new char[30000]; int i = 15000; // }
ここで、Javaコンパイラがこのコードから作成するバイトコードを確認する必要があります。 これを行うには、エディターのコンテキストメニューから「Show Bytecode outline」コマンドを呼び出します(IDEAの場合)。 環境はメソッドを使用してクラスをコンパイルし、バイトコードを表示します。 私たちの方法を見つけて、それを観察します。
結果をより確実に理解するために、JVM命令表を参照することをお勧めします 。
public test()V // , ( ) L0 // VM, 5 L0 LINENUMBER 5 L0 // short 30000 SIPUSH 30000 // T_CHAR , - ( ) NEWARRAY T_CHAR // 1 ( JVM) ASTORE 1 L1 // LINENUMBER 6 L1 // 5 L1 SIPUSH 15000 // ISTORE 2 // integer 2 L2 LINENUMBER 7 L2 RETURN // L3 // LOCALVARIABLE this LByteCodeTest; L0 L3 0 LOCALVARIABLE arr [C L1 L3 1 LOCALVARIABLE i I L2 L3 2 MAXSTACK = 1 MAXLOCALS = 3
これで、コードがバイトコードレベルでどのように機能するかがわかりました。 ラベル、行番号、および返却後のすべてを削除します。 この情報は、正しい操作には必要ありません。 その結果、次のようになります。
// SIPUSH 30000 NEWARRAY T_CHAR ASTORE 1 // SIPUSH 15000 ISTORE 2 // RETURN
これまでのところ、すべてはそれほど単純ではありません。 JVMでは、実行後のほとんどの操作は引数をスタックから削除します。 それは非常に便利で、後で掃除する必要はありません。 ここで、 表で説明した入力/出力を含め、これまでのサイクルなしのすべての操作をメソッドに追加します 。
次のようになります。
public void test() throws IOException { // read() char[] arr = new char[30000]; int i = 15000; i += 1111; arr[i] += 2222; arr[i] = 0; System.out.print(arr[i]); arr[i] = (char) System.in.read(); }
この場合、コードの意味は重要ではありません。操作のバイトコードを確認することが重要です。
余分な指示を削除して表示します。
public test()V throws java/io/IOException // SIPUSH 30000 NEWARRAY T_CHAR ASTORE 1 // SIPUSH 15000 ISTORE 2 // 1111 IINC 2 1111 // 2222 ALOAD 1 // ILOAD 2 // DUP2 // CALOAD // char , ( CASTORE) SIPUSH 2222 // 2222 IADD // I2C // char ( integer) CASTORE // // ALOAD 1 ILOAD 2 ICONST_0 // JVM 0 ( ) CASTORE // // GETSTATIC java/lang/System.out : Ljava/io/PrintStream; // ( ) ALOAD 1 ILOAD 2 CALOAD // INVOKEVIRTUAL java/io/PrintStream.print (C)V // // ALOAD 1 ILOAD 2 GETSTATIC java/lang/System.in : Ljava/io/InputStream; // INVOKEVIRTUAL java/io/InputStream.read ()I // I2C CASTORE // RETURN
これで、サイクルなしでジェネレーターを実装するために必要なすべての操作のバイトコードができました。
I2C
命令は不要であることに注意してください(経験的に判明)。
CALOAD
命令は型ディメンションも制御し、その結果、
I2C
の存在はその意味を失うと想定できます。 また、コンパイラーは繰り返しを整数( Opcodeクラスのargフィールドの型)に格納するため、
SIPUSH
命令を
LDC
置き換えます(整数型の定数をスタックに追加します)。
Javaではすべてがクラスに格納されるため、生成中にクラスが作成されるという事実からコードジェネレーターを開始しましょう。 ASMライブラリには、それらを生成するための優れたツールがあります。 それはすべて、フィールド、メソッド、ネストされたクラスの形式の要素を持つ、クラスツリーの単純な構築に帰着します。 メソッド自体は、JVM命令の配列を格納します。 コンパイル結果の処理方法を理解しやすくするために、クラスにRunnableインターフェイスを継承させます。
このインターフェイスから継承された空のクラスを作成します。
public class ClassTest implements Runnable { @Override public void run() { } }
そして、バイトコードを参照してください:
// class version 52.0 (52) // access flags 0x21 public class ClassTest implements java/lang/Runnable { // access flags 0x1 public <init>()V L0 LINENUMBER 3 L0 ALOAD 0 INVOKESPECIAL java/lang/Object.<init> ()V RETURN L1 LOCALVARIABLE this LClassTest; L0 L1 0 MAXSTACK = 1 MAXLOCALS = 1 // access flags 0x1 public run()V L0 LINENUMBER 7 L0 RETURN L1 LOCALVARIABLE this LClassTest; L0 L1 0 MAXSTACK = 0 MAXLOCALS = 1 }
ご覧のとおり、バイトコードを生成するときに
init
メソッドが追加され、そのタスクは親コンストラクターを呼び出すことです。 この点を考慮する必要があり、このメソッドを追加することを忘れないでください。
クラスを生成するためのクラスClassNodeとメソッドのMethodNodeがあります。
次のように空のクラスを生成できます(ラベルと行番号を考慮せずに)。
ClassNode cn = new ClassNode(); cn.version = V1_8; // ASM cn.access = ACC_PUBLIC + ACC_SUPER; // , ACC_SUPER, cn.name = "ClassTest"; // cn.superName = "java/lang/Object"; // cn.interfaces.add("java/lang/Runnable"); // { // public void <init>() MethodNode mn = new MethodNode(ACC_PUBLIC, "<init>", "()V", null, null); // InsnList il = mn.instructions; // // JVM il.add(new VarInsnNode(ALOAD, 0)); il.add(new MethodInsnNode(INVOKESPECIAL, cn.superName, "<init>", "()V", false)); // il.add(new InsnNode(RETURN)); // cn.methods.add(mn); } { // public void run() MethodNode mn = new MethodNode(ACC_PUBLIC, "run", "()V", null, null); // InsnList il = mn.instructions; // il.add(new InsnNode(RETURN)); // cn.methods.add(mn); } //, // COMPUTE_FRAMES // - ( JVM) // ClassWriter cw = new ClassWriter(ClassWriter.COMPUTE_FRAMES); // ClassNode ClassWriter cn.accept(cw); cw.toByteArray(); //
ここでのタスクは、Brainfuck操作を使用して、配列から
run
メソッドに命令を追加することです。 通常の
switch
を使用してこれを行います。
// // opcodes, Brainfuck public byte[] toByteCode(String className, int memorySize){ // ...................... MethodNode mn = new MethodNode(ACC_PUBLIC, "run", "()V", null, null); InsnList il = mn.instructions; // memorySize il.add(new LdcInsnNode(memorySize)); // integer il.add(new IntInsnNode(NEWARRAY, T_CHAR)); // il.add(new VarInsnNode(ASTORE, 1)); // 1 // il.add(new LdcInsnNode(memorySize / 2)); il.add(new VarInsnNode(ISTORE, 2)); // 2 // for (Opcode opcode : opcodes) { switch (opcode.type) { case SHIFT: // opcode.arg il.add(new IincInsnNode(2, opcode.arg)); break; case ADD: // opcode.arg il.add(new VarInsnNode(ALOAD, 1)); il.add(new VarInsnNode(ILOAD, 2)); il.add(new InsnNode(DUP2)); il.add(new InsnNode(CALOAD)); il.add(new LdcInsnNode(opcode.arg)); il.add(new InsnNode(IADD)); il.add(new InsnNode(CASTORE)); break; case ZERO: // il.add(new VarInsnNode(ALOAD, 1)); il.add(new VarInsnNode(ILOAD, 2)); il.add(new InsnNode(ICONST_0)); il.add(new InsnNode(CASTORE)); break; case OUT: // opcode.arg for (int i = 0; i < opcode.arg;+i) { il.add(new VarInsnNode(ALOAD, 0)); il.add(new FieldInsnNode(GETFIELD, cn.name, "out", "Ljava/io/PrintStream;")); il.add(new VarInsnNode(ALOAD, 1)); il.add(new VarInsnNode(ILOAD, 2)); il.add(new InsnNode(CALOAD)); il.add(new MethodInsnNode(INVOKEVIRTUAL, "java/io/PrintStream", "print", "(C)V", false)); } break; case IN: // opcode.arg for (int i = 0; i < opcode.arg;+i) { il.add(new VarInsnNode(ALOAD, 1)); il.add(new VarInsnNode(ILOAD, 2)); il.add(new VarInsnNode(ALOAD, 0)); il.add(new FieldInsnNode(GETSTATIC, cn.name, "in", "Ljava/io/InputStream;")); il.add(new MethodInsnNode(INVOKEVIRTUAL, "java/io/InputStream", "read", "()I", false)); il.add(new InsnNode(CASTORE)); } break; case WHILE: break; case END: break; } } // ...................... }
サイクルの問題を解決するために残っています。 繰り返しますが、テストメソッドのバイトコードを表示することに頼ってください。
public void test() { char[] arr = new char[30000]; int i = 15000; // while(arr[i] != 0) { i += 10000000; } }
バイトコードは次のとおりです。
public test()V L0 LINENUMBER 6 L0 SIPUSH 30000 NEWARRAY T_CHAR ASTORE 1 L1 LINENUMBER 7 L1 SIPUSH 15000 ISTORE 2 L2 LINENUMBER 9 L2 FRAME APPEND [[CI] // // ALOAD 1 ILOAD 2 CALOAD IFEQ L3 // , L3 ( ) L4 LINENUMBER 10 L4 // ILOAD 2 LDC 10000000 IADD ISTORE 2 // L2 ( - ) GOTO L2 L3 LINENUMBER 12 L3 //FRAME SAME // RETURN
その結果、ループの場合、ラベルとトランジションを正しく配置するだけで済みます。
labelsにはLabelNodeクラスがあり、実際にはオブジェクト自体がラベルです。 指示の中に挿入した場所に行きます。
ジャンプするには、 JumpInsnNodeクラスを使用します。 最初の引数は遷移のタイプ(無条件または条件付きのいずれか)を示し、2番目の引数は遷移が行われるラベル自体です。
ネストを考慮してラベルを配布するには、スタックを使用します。 つまり ループの始まりに会い、ラベルをスタックに保存し、終わりに会い、ラベルを引き出し、トランジションを登録しました。
結果は次のとおりです。
// Stack<LabelNode> lbls = new Stack<LabelNode>(); MethodNode mn = new MethodNode(ACC_PUBLIC, "run", "()V", null, null); // ...................... for (Opcode opcode : opcodes) { switch (opcode.type) { // ........................ case WHILE: // LabelNode begin = new LabelNode(), end = new LabelNode(); // lbls.push(end); lbls.push(begin); // il.add(begin); // il.add(new VarInsnNode(ALOAD, 1)); il.add(new VarInsnNode(ILOAD, 2)); il.add(new InsnNode(CALOAD)); il.add(new JumpInsnNode(IFEQ, end)); // , break; case END: // il.add(new JumpInsnNode(GOTO, lbls.pop())); // il.add(lbls.pop()); break; } }
バイトコード実行
今、このビジネスはすべて何らかの形で開始する必要がありますが、最初にこのクラスをロードします。 残念ながら、Javaはこれらの目的のためのフルタイムAPIを提供していませんので、そのような松葉杖に頼ってみましょう(
public class ByteCodeLoader extends ClassLoader { public static final ByteCodeLoader clazz = new ByteCodeLoader(); public Class<?> loadClass(byte[] bytecode) { return defineClass(null, bytecode, 0, bytecode.length); } }
ダウンロードと起動自体は次のようになります。
Class<?> aClass = ByteCodeLoader.clazz.loadClass( // toByteCode( // "BrainFuckJit", // 30000 // ) ); ((Runnable)aClass.newInstance()).run(); //
性能試験
このオプションがどれほど賢いかを知るのは興味深いでしょう。 これを行うために、多くのネストされたループがあり、パフォーマンスのテストに適したBrainfuckに特別なプログラムがあります。
>+>+>+>+>++<[>[<+++>- >>>>> >+>+>+>+>++<[>[<+++>- >>>>> >+>+>+>+>++<[>[<+++>- >>>>> >+>+>+>+>++<[>[<+++>- >>>>> +++[->+++++<]>[-]< <<<<< ]<<]>[-] <<<<< ]<<]>[-] <<<<< ]<<]>[-] <<<<< ]<<]>.
このコードは、コンパイラのパフォーマンスをテストするのにも適しています。プログラムの最後に、コード202のシンボルが表示されます。表示されている場合は、すべて正常です。
6つのテストを実行します。 通常のBrainfuckインタープリター、JVM用コンパイラー、VC ++でのコンパイルを確認しましょう。 各テストは、最適化の有無にかかわらず(Brainfuckを使用して)テストされます。
テスト結果(少ないほど良い):
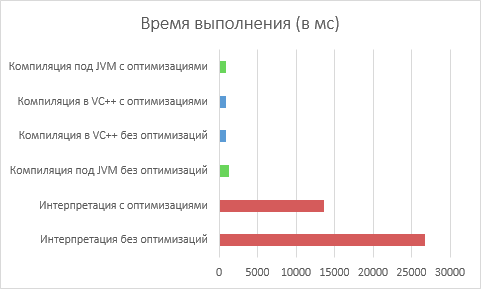
ご覧のとおり、私たちの努力は無駄ではありませんでした。 Java VMでのJITコンパイルはその役割を果たし、パフォーマンスをネイティブ実行のレベルに引き上げました。
おわりに
Java VMは、言語を実装するための非常に便利なプラットフォームです。 よく考えられた一連の命令と便利なAPIを備えたVMを使用すると、ごく短時間で独自の言語を作成できます。
シンプルで理解しやすいASMチュートリアルがないため、最初はライブラリの仕組みを理解するのが難しくなり、さまざまな古代の奇跡につながる可能性がありますが、ライブラリ自体はエレガントなソリューションを提供します。
この記事の目的は、このギャップを埋め、できるだけ早く作成を開始する機会を与えることでした。
私は成功したと思います。
ご清聴ありがとうございました!