これは、キューの実装に当てはまりますか? それらの使用の境界はどこですか? これが私たちが見つけようとするものです。
すべてのテストはGitHubで利用できます 。 JVMのメモリ制限は64MBに設定されており、目標の達成、満杯時のメモリダンプ(OOM)、およびこの災害の場合のアプリケーションの強制終了を加速しました。
-Xms64m -Xmx64m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp -XX:OnOutOfMemoryError="kill -9 %p"
それでは、行きましょう。 hazelcastの最新の安定バージョンが使用されます-3.2.3。
(テストは、速度と量の測定に関するサンプルデータを提供します。テストマシンの構成は公開されていません。データはテストを相互に比較するのに十分であり、これが目標です)
テスト1-メモリは計り知れない
最初のテストでは、1つのhazelcastノードを使用します。 メモリが不足するまでキューを作成し、そこに要素を追加します。
結果が期待されます。 要素あたり0.026msの速度で46万のオブジェクトを記録することができました。 これらのデータは、比較のためにさらに役立ちます。
メモリダンプの学習:
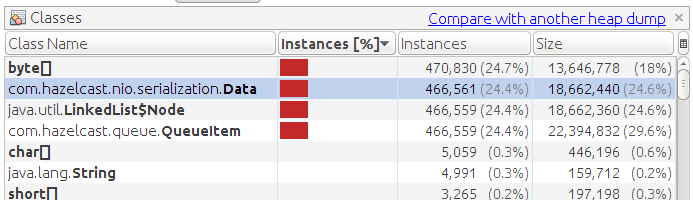
多数のQueueItemオブジェクトが表示されます。 この内部オブジェクトは、キューの要素ごとに作成されます。 要素の一意の識別子とデータ自体(データオブジェクト)が含まれます
テスト2-ストレージの接続
データをメモリに保存せずに解放するために、ストレージをキューに接続できます。 テストのために、MockQueueStoreを準備しました。これは何も行いませんが、ストアを正しく表示し、送信されたすべての要素を失います。 メモリー内のデータのストレージを完全に除外するために、パラメーター「memory-limit = 0」を指定します(デフォルトでは、1000個のエレメントが保存されます)。
私たちの期待はOOMを取り除くことにありますが、そうではありませんでした。 より多くのオブジェクト-980kを記録することができましたが、すべて同じでした。
メモリダンプを確認します。
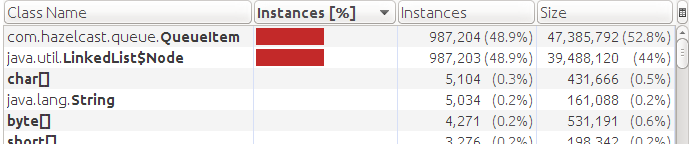
Data型のオブジェクトはありませんが、QueueItemはまだメモリにあることがわかります。 これが私たちの最初の発見です。 hazelcastキュー(QueueContainer)を実装しても、ストレージがあるときにヘルパーオブジェクトは削除されません。 彼女は常に内部キュー(LinkedList)に保存します。
この状況では、空きメモリの可用性を超えるボリュームで制御できない成長が発生する可能性があるキューを使用できません。 これは何にも終わりをもたらしません。 50メガバイトでは、約100万個の要素が収まります。 すべてのタスクでそのような量が可能というわけではなく、実際にはより多くのメモリがあります。 ただし、この制限が必要であることを忘れないでください。 どうぞ
テスト3-トランザクションを使用したスパイ機能
実装のソースコードを読み取ると、別の機能またはバグが発見されました。 Hazelcastを使用すると、トランザクションで分散オブジェクトを操作できます。 項目の追加中に3番目のテストにトランザクションを追加するとどうなるか見てみましょう。
約250kのキュー要素でOOMを取得します。 ダンプを確認します。
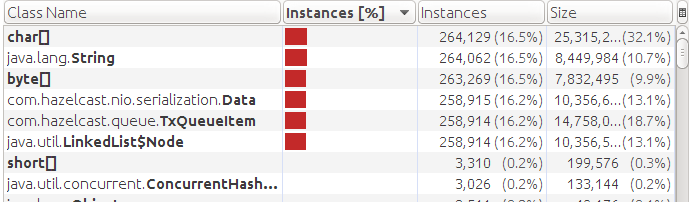
ストレージを接続しましたが、メモリ(データ)にデータストレージがあります。 また、QueueItemオブジェクトの代わりに、TxQueueItemが使用されます。 これはすべて実装の結果です。 トランザクションを使用する場合、データはストレージにフラッシュされません。 また、TxQueueItemオブジェクトは追加のフィールドを持つQueueItemの後継であり、より多くのメモリを消費するため、OMMの前の要素は最初のテストよりもさらに少なくなりました。
結論-トランザクションとキューストレージは連動しません。
続けましょう。 クラスター内のキューがどのように機能するかを見てみましょう。
テスト4-ちょうど2つのノード
追加のキュー設定は使用しません。 すべてデフォルトで。 ストレージなし。 10万個の要素をスタックして読み取ります。 キューを所有するノードにそれを入れて読み取ります。 後者は、データアクセス速度にとって重要な場合があります。 実際には、Mapとは異なり、キューの実装は分散されていません。 キューのすべての要素は、クラスターノードの1つ(キューの所有者)に存在します。 より正確には、キューが属するパーティションの所有者。 所有者と対話するため、クラスターがない場合と同様に、アクセスが高速になると予想されます。
その結果、次の速度が得られます。
INFO: add 100000 0.255ms
INFO: poll 100000 0.223ms
速度は1桁低下しました(最初のテストの0.026msに比べて)。 実際には、デフォルトで1つのキューがキューに使用されます。 また、hazelcastは、追加および読み取り時に2番目のノードとデータを同期しました。
テスト4_1-所有者と協力しないようにしてください
キューに追加し、パーティションの所有者からではなく読み取る場合、速度に違いはありますか?
有意差はありませんでした:
INFO: add 100000 0.215ms
INFO: poll 100000 0.201ms
同等の速度が見られます。 テスト4のように、両方のノードは同様の操作セットを実行し、結果は用語の場所を変更してもほとんど変わりません。 実際の作業は、バックアップを含む仲介者を通じてキューの所有者と一緒に行われます。
テスト5-所有者を殺す
キューを削除してから、キューを所有しているノードを削除してみましょう。 そして、残りのノードからデータを読み取ります。 次の結果が得られます。
INFO: add 100000 0.267ms
INFO: poll 100000 0.025ms
残りの1つのノードが1桁速く動作し始めます。 彼はクラスター内に単独で残り、バックアップを作成するための通信にリソースを費やしません。
テスト6-バックアップをオフにする
キュー構成でバックアップをオフにし、前のテストのように所有者を削除するとどうなるか見てみましょう。
INFO: add 100000 0.022ms
その結果、キューの所有者との作業が高速になります。 彼はバックアップにリソースを費やしません。 しかし、彼のfall落後-行全体が失われます。
テスト7-ストレージをクラスターに接続する
バックアップがないため、ノードの停止後にすべてのデータが失われました。キューの所有者です。 ストレージをこの構成に接続して、データが生き残るかどうかを確認しましょう。 ストレージを少しスマートにして、メモリ(MemoryQueueStore)からデータを保存して返すようにします。
結果:
INFO: add 100000 0.023ms
INFO: poll 100000 0.018ms
速度はどこでも良好であることがわかります-バックアップよりも1桁高いです。 また、残りのノードでキューが回復したこともわかります。
2番目のノードでのキューの復元に関する詳細。 このプロセスでは、最初にすべてのキーがQueueContainer実装によってストレージからメモリに読み込まれ、新しいキーをさらに生成するためにそれらから最大値が決定されます。 LinkedListの内部キューは、キューのすべての要素ですぐにいっぱいになりますが、データはありません。 リポジトリからの復元後にキュー内のアイテムの順序を保持するには、リポジトリはセット内の正しい順序でそれらを発行する必要があります。 次に、必要に応じて、ストレージからデータがロードされます。 ロードはバッチで行われます。 デフォルトは250個です。
いくつかの結論
- ストレージを使用しても、メモリが完全に解放されるわけではありません。 データ量を予測し、OOMに到達しないことが必要です。
- ストレージを使用する場合、バックアップを強制的に無効にする必要があります。 デフォルトでは有効になっており、他のノードの速度とメモリ使用量に影響します。
- ストレージからのキュー回復の実装はリソースを消費し、最適ではありません。 復元するとき、新しい所有者は前の所有者よりも少ないメモリを持っていてはなりません
- トランザクションを使用する場合、キューストレージは使用されません
そしてもちろん、主要な結論は、重要なタスクで製品を使用する前に製品をテストし続ける必要があるということです。
PS:QueueContainerの実装を修正する方法は、このドキュメントの範囲外です。 これを共有する時間と努力があることを願っています。